 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlotOCR Bench: OCR Models Still Struggle Beyond a Handful of Unicode Scripts
Apr 14, 2026Optical character recognition (OCR) has advanced rapidly with the rise of vision-language models, yet evaluation has remained concentrated on a small cluster of high- and mid-resource scripts. We introduce GlotOCR Bench, a comprehensive benchmark evaluating OCR generalization across 100+ Unicode scripts. Our benchmark comprises clean and degraded image variants rendered from real multilingual texts. Images are rendered using fonts from the Google Fonts repository, shaped with HarfBuzz and rasterized with FreeType, supporting both LTR and RTL scripts. Samples of rendered images were manually reviewed to verify correct rendering across all scripts. We evaluate a broad suite of open-weight and proprietary vision-language models and find that most perform well on fewer than ten scripts, and even the strongest frontier models fail to generalize beyond thirty scripts. Performance broadly tracks script-level pretraining coverage, suggesting that current OCR systems rely on language model pretraining as much as on visual recognition. Models confronted with unfamiliar scripts either produce random noise or hallucinate characters from similar scripts they already know. We release the benchmark and pipeline for reproducibility. Pipeline Code: https://github.com/cisnlp/glotocr-bench, Benchmark: https://hf.co/datasets/cis-lmu/glotocr-bench.
Insights from the ICLR Peer Review and Rebuttal Process
Nov 19, 2025Peer review is a cornerstone of scientific publishing, including at premier machine learning conferences such as ICLR. As submission volumes increase, understanding the nature and dynamics of the review process is crucial for improving its efficiency, effectiveness, and the quality of published papers. We present a large-scale analysis of the ICLR 2024 and 2025 peer review processes, focusing on before- and after-rebuttal scores and reviewer-author interactions. We examine review scores, author-reviewer engagement, temporal patterns in review submissions, and co-reviewer influence effects. Combining quantitative analyses with LLM-based categorization of review texts and rebuttal discussions, we identify common strengths and weaknesses for each rating group, as well as trends in rebuttal strategies that are most strongly associated with score changes. Our findings show that initial scores and the ratings of co-reviewers are the strongest predictors of score changes during the rebuttal, pointing to a degree of reviewer influence. Rebuttals play a valuable role in improving outcomes for borderline papers, where thoughtful author responses can meaningfully shift reviewer perspectives. More broadly, our study offers evidence-based insights to improve the peer review process, guiding authors on effective rebuttal strategies and helping the community design fairer and more efficient review processes. Our code and score changes data are available at https://github.com/papercopilot/iclr-insights.
MEXA: Multilingual Evaluation of English-Centric LLMs via Cross-Lingual Alignment
Oct 08, 2024
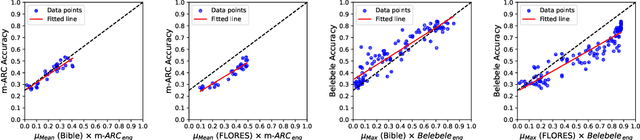


English-centric large language models (LLMs) often show strong multilingual capabilities. However, the multilingual performance of these models remains unclear and is not thoroughly evaluated for many languages. Most benchmarks for multilinguality focus on classic NLP tasks, or cover a minimal number of languages. We introduce MEXA, a method for assessing the multilingual capabilities of pre-trained English-centric LLMs using parallel sentences, which are available for more languages than existing downstream tasks. MEXA leverages the fact that English-centric LLMs use English as a kind of pivot language in their intermediate layers. It computes the alignment between English and non-English languages using parallel sentences to evaluate the transfer of language understanding from English to other languages. This alignment can be used to estimate model performance in other languages. We conduct studies using various parallel datasets (FLORES-200 and Bible), models (Llama family, Gemma family, Mistral, and OLMo), and established downstream tasks (Belebele, m-MMLU, and m-ARC). We explore different methods to compute embeddings in decoder-only models. Our results show that MEXA, in its default settings, achieves a statistically significant average Pearson correlation of 0.90 with three established downstream tasks across nine models and two parallel datasets. This suggests that MEXA is a reliable method for estimating the multilingual capabilities of English-centric LLMs, providing a clearer understanding of their multilingual potential and the inner workings of LLMs. Leaderboard: https://huggingface.co/spaces/cis-lmu/Mexa, Code: https://github.com/cisnlp/Mexa.
GIRT-Model: Automated Generation of Issue Report Templates
Feb 08, 2024
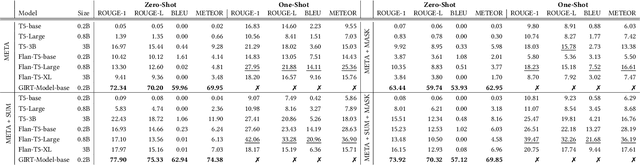
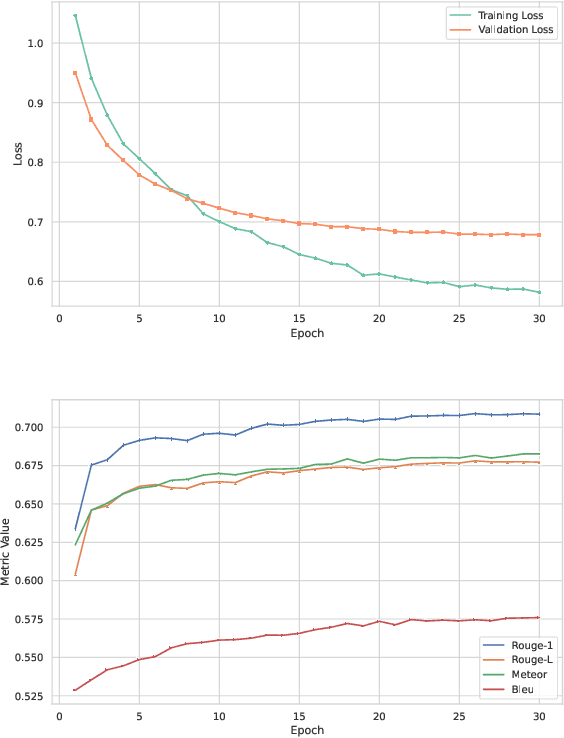
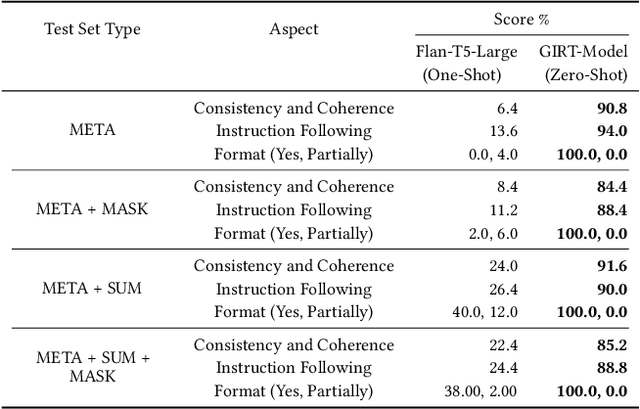
Platforms such as GitHub and GitLab introduce Issue Report Templates (IRTs) to enable more effective issue management and better alignment with developer expectations. However, these templates are not widely adopted in most repositories, and there is currently no tool available to aid developers in generating them. In this work, we introduce GIRT-Model, an assistant language model that automatically generates IRTs based on the developer's instructions regarding the structure and necessary fields. We create GIRT-Instruct, a dataset comprising pairs of instructions and IRTs, with the IRTs sourced from GitHub repositories. We use GIRT-Instruct to instruction-tune a T5-base model to create the GIRT-Model. In our experiments, GIRT-Model outperforms general language models (T5 and Flan-T5 with different parameter sizes) in IRT generation by achieving significantly higher scores in ROUGE, BLEU, METEOR, and human evaluation. Additionally, we analyze the effectiveness of GIRT-Model in a user study in which participants wrote short IRTs with GIRT-Model. Our results show that the participants find GIRT-Model useful in the automated generation of templates. We hope that through the use of GIRT-Model, we can encourage more developers to adopt IRTs in their repositories. We publicly release our code, dataset, and model at https://github.com/ISE-Research/girt-model.
MenuCraft: Interactive Menu System Design with Large Language Models
Mar 08, 2023Menu system design is a challenging task involving many design options and various human factors. For example, one crucial factor that designers need to consider is the semantic and systematic relation of menu commands. However, capturing these relations can be challenging due to limited available resources. With the advancement of neural language models, large language models can utilize their vast pre-existing knowledge in designing and refining menu systems. In this paper, we propose MenuCraft, an AI-assisted designer for menu design that enables collaboration between the designer and a dialogue system to design menus. MenuCraft offers an interactive language-based menu design tool that simplifies the menu design process and enables easy customization of design options. MenuCraft supports a variety of interactions through dialog that allows performing few-shot learning.