 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cross-Lingual Quality Classifiers for Multilingual Pretraining Data Selection
Apr 22, 2026As Large Language Models (LLMs) scale, data curation has shifted from maximizing volume to optimizing the signal-to-noise ratio by performing quality filtering. However, for many languages, native high quality data is insufficient to train robust quality classifiers. This work investigates the idea that quality markers in embedding space may show cross-lingual consistency, which would allow high-resource languages to subsidize the filtering of low-resource ones. We evaluate various filtering strategies, including cross-lingual transfer, third quartile sampling (Q3), and retention rate tuning. Our results demonstrate that massive multilingual pooling frequently outperforms monolingual baselines in both rank stability and aggregate accuracy for a 1B model trained on 103B tokens, delivering gains for high resource languages (1.2% increase in aggregate normalized accuracy for French) and matching or exceeding monolingual baselines for low-resource languages. However, we find that scale alone does not guarantee stability. Furthermore, for high-resource languages like French, we show that refining the decision boundary through third quartile sampling (Q3) or tuning the retention rate is necessary to fully leverage the multilingual signal.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
Analyzing & Reducing the Need for Learning Rate Warmup in GPT Training
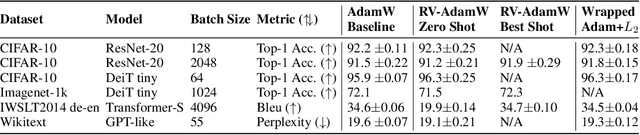
Oct 31, 2024Learning Rate Warmup is a popular heuristic for training neural networks, especially at larger batch sizes, despite limited understanding of its benefits. Warmup decreases the update size $\Delta \mathbf{w}_t = \eta_t \mathbf{u}_t$ early in training by using lower values for the learning rate $\eta_t$. In this work we argue that warmup benefits training by keeping the overall size of $\Delta \mathbf{w}_t$ limited, counteracting large initial values of $\mathbf{u}_t$. Focusing on small-scale GPT training with AdamW/Lion, we explore the following question: Why and by which criteria are early updates $\mathbf{u}_t$ too large? We analyze different metrics for the update size including the $\ell_2$-norm, resulting directional change, and impact on the representations of the network, providing a new perspective on warmup. In particular, we find that warmup helps counteract large angular updates as well as a limited critical batch size early in training. Finally, we show that the need for warmup can be significantly reduced or eliminated by modifying the optimizer to explicitly normalize $\mathbf{u}_t$ based on the aforementioned metrics.
On-device Collaborative Language Modeling via a Mixture of Generalists and Specialists
Sep 20, 2024We target on-device collaborative fine-tuning of Large Language Models (LLMs) by adapting a Mixture of Experts (MoE) architecture, where experts are Low-Rank Adaptation (LoRA) modules. In conventional MoE approaches, experts develop into specialists throughout training. In contrast, we propose a novel $\textbf{Co}$llaborative learning approach via a $\textbf{Mi}$xture of $\textbf{G}$eneralists and $\textbf{S}$pecialists (CoMiGS). Diversifying into the two roles is achieved by aggregating certain experts globally while keeping others localized to specialize in user-specific datasets. Central to our work is a learnable routing network that routes at a token level, balancing collaboration and personalization at the finest granularity. Our method consistently demonstrates superior performance in scenarios with high data heterogeneity across various datasets. By design, our approach accommodates varying computational resource constraints among users as shown in different numbers of LoRA experts. We further showcase that low-resourced users can benefit from high-resourced users with high data quantity.
Towards an empirical understanding of MoE design choices
Feb 20, 2024In this study, we systematically evaluate the impact of common design choices in Mixture of Experts (MoEs) on validation performance, uncovering distinct influences at token and sequence levels. We also present empirical evidence showing comparable performance between a learned router and a frozen, randomly initialized router, suggesting that learned routing may not be essential. Our study further reveals that Sequence-level routing can result in topic-specific weak expert specialization, in contrast to syntax specialization observed with Token-level routing.
Rotational Optimizers: Simple & Robust DNN Training
May 26, 2023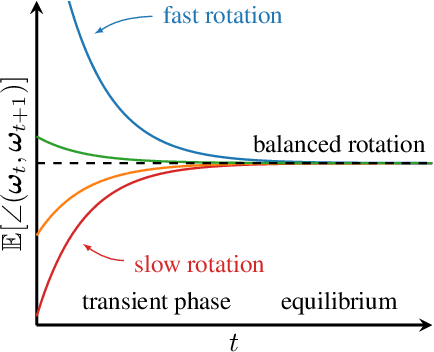

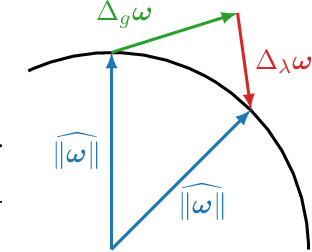
The training dynamics of modern deep neural networks depend on complex interactions between the learning rate, weight decay, initialization, and other hyperparameters. These interactions can give rise to Spherical Motion Dynamics in scale-invariant layers (e.g., normalized layers), which converge to an equilibrium state, where the weight norm and the expected rotational update size are fixed. Our analysis of this equilibrium in AdamW, SGD with momentum, and Lion provides new insights into the effects of different hyperparameters and their interactions on the training process. We propose rotational variants (RVs) of these optimizers that force the expected angular update size to match the equilibrium value throughout training. This simplifies the training dynamics by removing the transient phase corresponding to the convergence to an equilibrium. Our rotational optimizers can match the performance of the original variants, often with minimal or no tuning of the baseline hyperparameters, showing that these transient phases are not needed. Furthermore, we find that the rotational optimizers have a reduced need for learning rate warmup and improve the optimization of poorly normalized networks.