 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Decay may matter more than muP for Learning Rate Transfer in Practice
Oct 21, 2025Transferring the optimal learning rate from small to large neural networks can enable efficient training at scales where hyperparameter tuning is otherwise prohibitively expensive. To this end, the Maximal Update Parameterization (muP) proposes a learning rate scaling designed to keep the update dynamics of internal representations stable across different model widths. However, the scaling rules of muP rely on strong assumptions, particularly about the geometric alignment of a layer's inputs with both its weights and gradient updates. In this large-scale empirical investigation, we show that these assumptions hold only briefly at the start of training in the practical setups where learning rate transfer is most valuable, such as LLM training. For the remainder of training it is weight decay rather than muP that correctly stabilizes the update dynamics of internal representations across widths, facilitating learning rate transfer. This suggests muP's scaling primarily acts as a form of implicit learning rate warmup, allowing us to largely replace it with modified warmup schedules. Together these findings fundamentally challenge prevailing beliefs about learning rate transfer and can explain empirical practice such as why muP requires the independent weight decay variant for successful transfer.
Analyzing & Reducing the Need for Learning Rate Warmup in GPT Training
Oct 31, 2024Learning Rate Warmup is a popular heuristic for training neural networks, especially at larger batch sizes, despite limited understanding of its benefits. Warmup decreases the update size $\Delta \mathbf{w}_t = \eta_t \mathbf{u}_t$ early in training by using lower values for the learning rate $\eta_t$. In this work we argue that warmup benefits training by keeping the overall size of $\Delta \mathbf{w}_t$ limited, counteracting large initial values of $\mathbf{u}_t$. Focusing on small-scale GPT training with AdamW/Lion, we explore the following question: Why and by which criteria are early updates $\mathbf{u}_t$ too large? We analyze different metrics for the update size including the $\ell_2$-norm, resulting directional change, and impact on the representations of the network, providing a new perspective on warmup. In particular, we find that warmup helps counteract large angular updates as well as a limited critical batch size early in training. Finally, we show that the need for warmup can be significantly reduced or eliminated by modifying the optimizer to explicitly normalize $\mathbf{u}_t$ based on the aforementioned metrics.
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations
May 29, 2024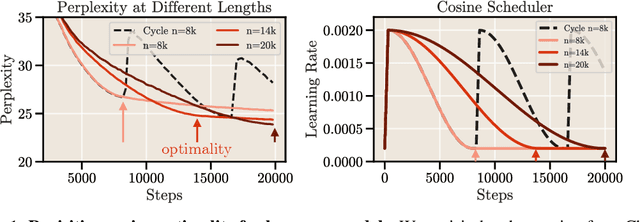
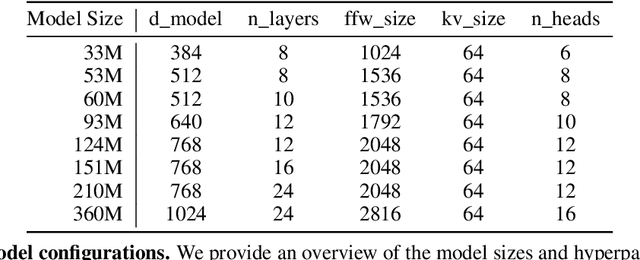
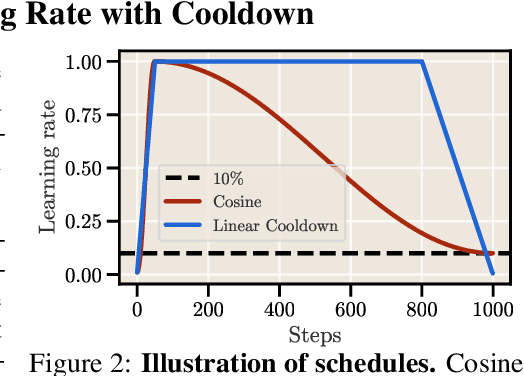
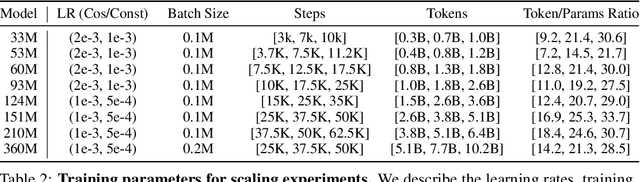
Scale has become a main ingredient in obtaining strong machine learning models. As a result, understanding a model's scaling properties is key to effectively designing both the right training setup as well as future generations of architectures. In this work, we argue that scale and training research has been needlessly complex due to reliance on the cosine schedule, which prevents training across different lengths for the same model size. We investigate the training behavior of a direct alternative - constant learning rate and cooldowns - and find that it scales predictably and reliably similar to cosine. Additionally, we show that stochastic weight averaging yields improved performance along the training trajectory, without additional training costs, across different scales. Importantly, with these findings we demonstrate that scaling experiments can be performed with significantly reduced compute and GPU hours by utilizing fewer but reusable training runs. Our code is available at https://github.com/epfml/schedules-and-scaling.
Memory Efficient Mixed-Precision Optimizers
Sep 21, 2023Traditional optimization methods rely on the use of single-precision floating point arithmetic, which can be costly in terms of memory size and computing power. However, mixed precision optimization techniques leverage the use of both single and half-precision floating point arithmetic to reduce memory requirements while maintaining model accuracy. We provide here an algorithm to further reduce memory usage during the training of a model by getting rid of the floating point copy of the parameters, virtually keeping only half-precision numbers. We also explore the benefits of getting rid of the gradient's value by executing the optimizer step during the back-propagation. In practice, we achieve up to 25% lower peak memory use and 15% faster training while maintaining the same level of accuracy.
Ghost Noise for Regularizing Deep Neural Networks
May 26, 2023Batch Normalization (BN) is widely used to stabilize the optimization process and improve the test performance of deep neural networks. The regularization effect of BN depends on the batch size and explicitly using smaller batch sizes with Batch Normalization, a method known as Ghost Batch Normalization (GBN), has been found to improve generalization in many settings. We investigate the effectiveness of GBN by disentangling the induced "Ghost Noise" from normalization and quantitatively analyzing the distribution of noise as well as its impact on model performance. Inspired by our analysis, we propose a new regularization technique called Ghost Noise Injection (GNI) that imitates the noise in GBN without incurring the detrimental train-test discrepancy effects of small batch training. We experimentally show that GNI can provide a greater generalization benefit than GBN. Ghost Noise Injection can also be beneficial in otherwise non-noisy settings such as layer-normalized networks, providing additional evidence of the usefulness of Ghost Noise in Batch Normalization as a regularizer.
Hardware-Efficient Transformer Training via Piecewise Affine Operations
May 26, 2023Multiplications are responsible for most of the computational cost involved in neural network training and inference. Recent research has thus looked for ways to reduce the cost associated with them. Inspired by Mogami (2020), we replace multiplication with a cheap piecewise affine approximation that is achieved by adding the bit representation of the floating point numbers together as integers. We show that transformers can be trained with the resulting modified matrix multiplications on both vision and language tasks with little to no performance impact, and without changes to the training hyperparameters. We further replace all non-linearities in the networks making them fully and jointly piecewise affine in both inputs and weights. Finally, we show that we can eliminate all multiplications in the entire training process, including operations in the forward pass, backward pass and optimizer update, demonstrating the first successful training of modern neural network architectures in a fully multiplication-free fashion.
Rotational Optimizers: Simple & Robust DNN Training
May 26, 2023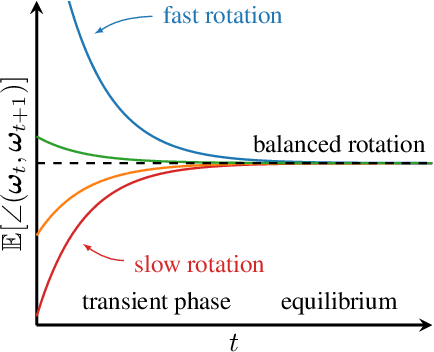

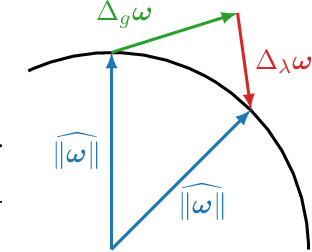
The training dynamics of modern deep neural networks depend on complex interactions between the learning rate, weight decay, initialization, and other hyperparameters. These interactions can give rise to Spherical Motion Dynamics in scale-invariant layers (e.g., normalized layers), which converge to an equilibrium state, where the weight norm and the expected rotational update size are fixed. Our analysis of this equilibrium in AdamW, SGD with momentum, and Lion provides new insights into the effects of different hyperparameters and their interactions on the training process. We propose rotational variants (RVs) of these optimizers that force the expected angular update size to match the equilibrium value throughout training. This simplifies the training dynamics by removing the transient phase corresponding to the convergence to an equilibrium. Our rotational optimizers can match the performance of the original variants, often with minimal or no tuning of the baseline hyperparameters, showing that these transient phases are not needed. Furthermore, we find that the rotational optimizers have a reduced need for learning rate warmup and improve the optimization of poorly normalized networks.
Adaptive Braking for Mitigating Gradient Delay
Jul 10, 2020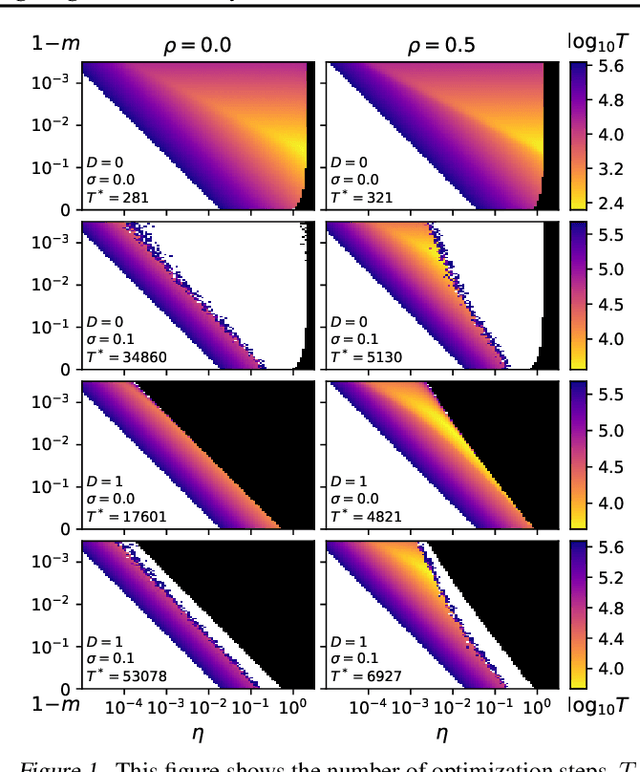
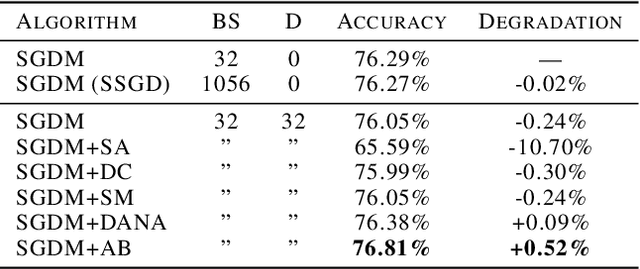
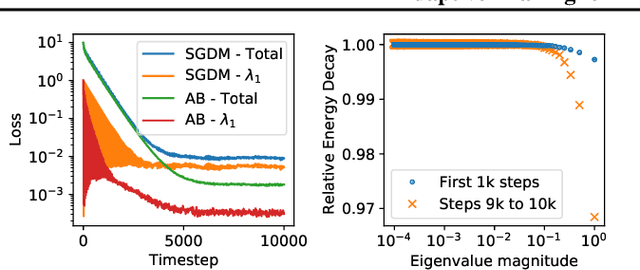

Neural network training is commonly accelerated by using multiple synchronized workers to compute gradient updates in parallel. Asynchronous methods remove synchronization overheads and improve hardware utilization at the cost of introducing gradient delay, which impedes optimization and can lead to lower final model performance. We introduce Adaptive Braking (AB), a modification for momentum-based optimizers that mitigates the effects of gradient delay. AB dynamically scales the gradient based on the alignment of the gradient and the velocity. This can dampen oscillations along high curvature directions of the loss surface, stabilizing and accelerating asynchronous training. We show that applying AB on top of SGD with momentum enables training ResNets on CIFAR-10 and ImageNet-1k with delays $D \geq$ 32 update steps with minimal drop in final test accuracy.
Pipelined Backpropagation at Scale: Training Large Models without Batches
Mar 25, 2020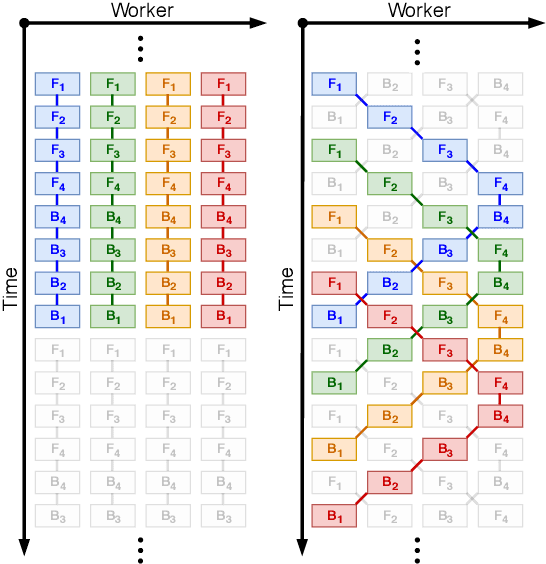
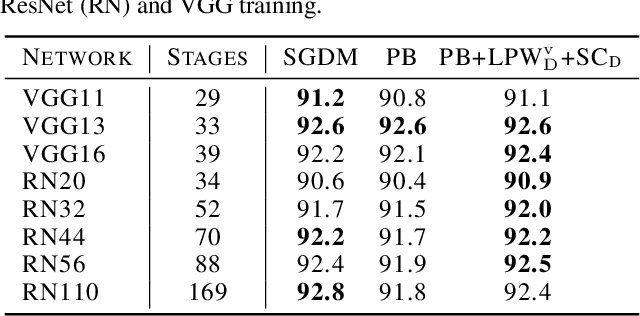
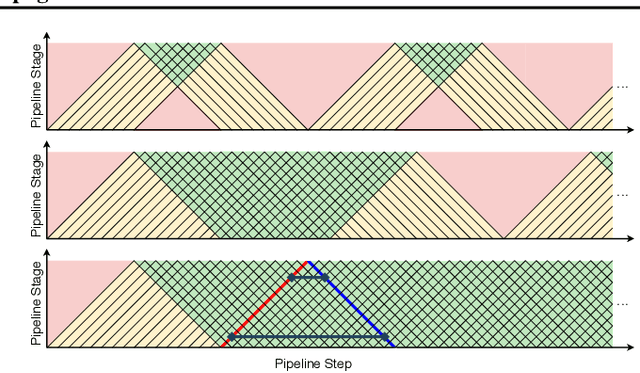
Parallelism is crucial for accelerating the training of deep neural networks. Pipeline parallelism can provide an efficient alternative to traditional data parallelism by allowing workers to specialize. Performing mini-batch SGD using pipeline parallelism has the overhead of filling and draining the pipeline. Pipelined Backpropagation updates the model parameters without draining the pipeline. This removes the overhead but introduces stale gradients and inconsistency between the weights used on the forward and backward passes, reducing final accuracy and the stability of training. We introduce Spike Compensation and Linear Weight Prediction to mitigate these effects. Analysis on a convex quadratic shows that both methods effectively counteract staleness. We train multiple convolutional networks at a batch size of one, completely replacing batch parallelism with fine-grained pipeline parallelism. With our methods, Pipelined Backpropagation achieves full accuracy on CIFAR-10 and ImageNet without hyperparameter tuning.
Online Normalization for Training Neural Networks
May 28, 2019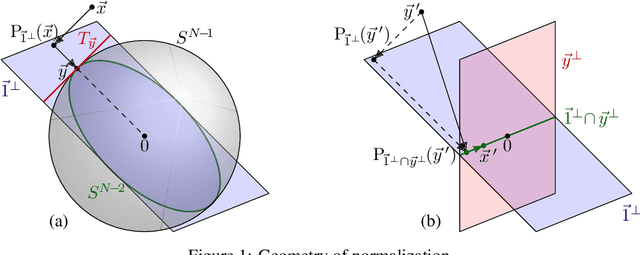
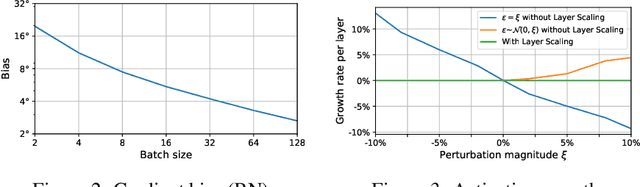
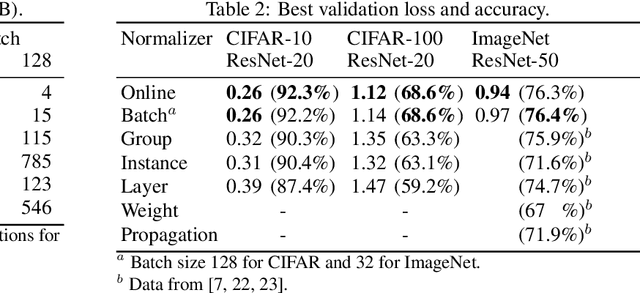
Online Normalization is a new technique for normalizing the hidden activations of a neural network. Like Batch Normalization, it normalizes the sample dimension. While Online Normalization does not use batches, it is as accurate as Batch Normalization. We resolve a theoretical limitation of Batch Normalization by introducing an unbiased technique for computing the gradient of normalized activations. Online Normalization works with automatic differentiation by adding statistical normalization as a primitive. This technique can be used in cases not covered by some other normalizers, such as recurrent networks, fully connected networks, and networks with activation memory requirements prohibitive for batching. We show its applications to image classification, image segmentation, and language modeling. We present formal proofs and experimental results on ImageNet, CIFAR, and PTB datasets.