 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
Mar 27, 2024Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
MosaicBERT: A Bidirectional Encoder Optimized for Fast Pretraining
Jan 16, 2024



Although BERT-style encoder models are heavily used in NLP research, many researchers do not pretrain their own BERTs from scratch due to the high cost of training. In the past half-decade since BERT first rose to prominence, many advances have been made with other transformer architectures and training configurations that have yet to be systematically incorporated into BERT. Here, we introduce MosaicBERT, a BERT-style encoder architecture and training recipe that is empirically optimized for fast pretraining. This efficient architecture incorporates FlashAttention, Attention with Linear Biases (ALiBi), Gated Linear Units (GLU), a module to dynamically remove padded tokens, and low precision LayerNorm into the classic transformer encoder block. The training recipe includes a 30% masking ratio for the Masked Language Modeling (MLM) objective, bfloat16 precision, and vocabulary size optimized for GPU throughput, in addition to best-practices from RoBERTa and other encoder models. When pretrained from scratch on the C4 dataset, this base model achieves a downstream average GLUE (dev) score of 79.6 in 1.13 hours on 8 A100 80 GB GPUs at a cost of roughly $20. We plot extensive accuracy vs. pretraining speed Pareto curves and show that MosaicBERT base and large are consistently Pareto optimal when compared to a competitive BERT base and large. This empirical speed up in pretraining enables researchers and engineers to pretrain custom BERT-style models at low cost instead of finetune on existing generic models. We open source our model weights and code.
* 10 pages, 4 figures in main text. 25 pages total
Representation range needs for 16-bit neural network training
Apr 06, 2021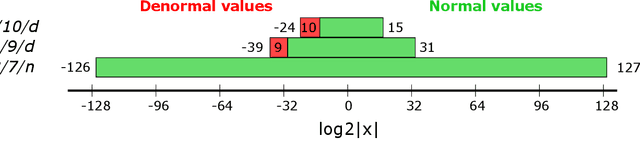

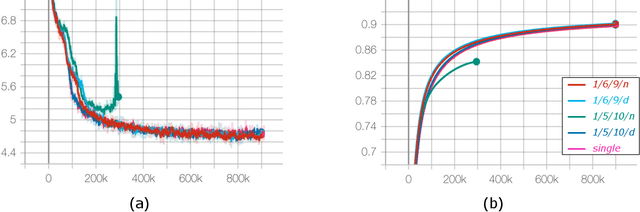
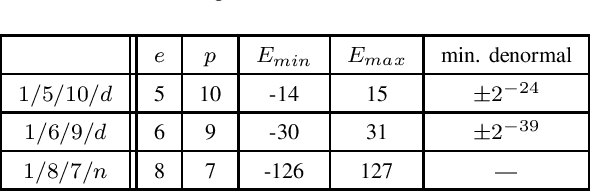
Deep learning has grown rapidly thanks to its state-of-the-art performance across a wide range of real-world applications. While neural networks have been trained using IEEE-754 binary32 arithmetic, the rapid growth of computational demands in deep learning has boosted interest in faster, low precision training. Mixed-precision training that combines IEEE-754 binary16 with IEEE-754 binary32 has been tried, and other $16$-bit formats, for example Google's bfloat16, have become popular. In floating-point arithmetic there is a tradeoff between precision and representation range as the number of exponent bits changes; denormal numbers extend the representation range. This raises questions of how much exponent range is needed, of whether there is a format between binary16 (5 exponent bits) and bfloat16 (8 exponent bits) that works better than either of them, and whether or not denormals are necessary. In the current paper we study the need for denormal numbers for mixed-precision training, and we propose a 1/6/9 format, i.e., 6-bit exponent and 9-bit explicit mantissa, that offers a better range-precision tradeoff. We show that 1/6/9 mixed-precision training is able to speed up training on hardware that incurs a performance slowdown on denormal operations or eliminates the need for denormal numbers altogether. And, for a number of fully connected and convolutional neural networks in computer vision and natural language processing, 1/6/9 achieves numerical parity to standard mixed-precision.
Adaptive Braking for Mitigating Gradient Delay
Jul 10, 2020
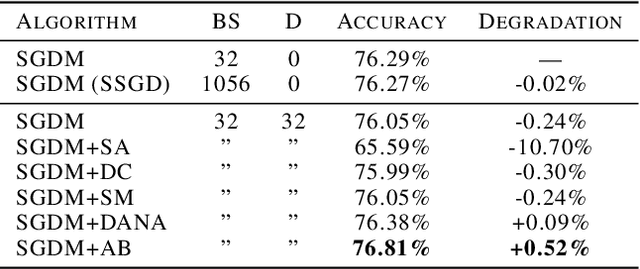
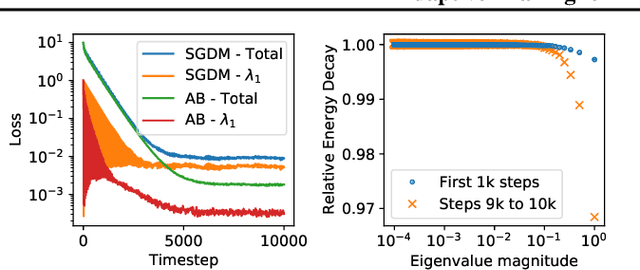

Neural network training is commonly accelerated by using multiple synchronized workers to compute gradient updates in parallel. Asynchronous methods remove synchronization overheads and improve hardware utilization at the cost of introducing gradient delay, which impedes optimization and can lead to lower final model performance. We introduce Adaptive Braking (AB), a modification for momentum-based optimizers that mitigates the effects of gradient delay. AB dynamically scales the gradient based on the alignment of the gradient and the velocity. This can dampen oscillations along high curvature directions of the loss surface, stabilizing and accelerating asynchronous training. We show that applying AB on top of SGD with momentum enables training ResNets on CIFAR-10 and ImageNet-1k with delays $D \geq$ 32 update steps with minimal drop in final test accuracy.
Pipelined Backpropagation at Scale: Training Large Models without Batches
Mar 25, 2020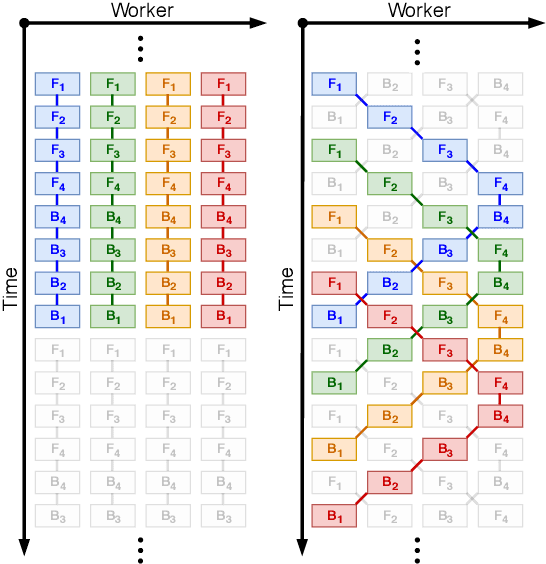
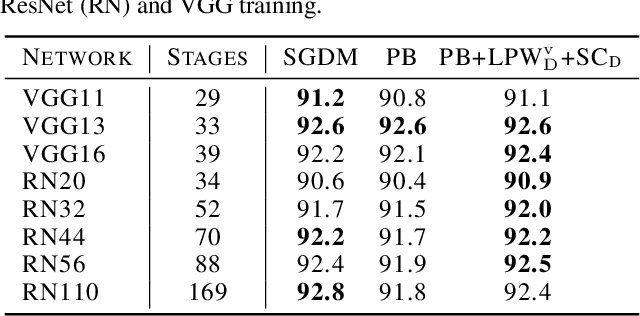
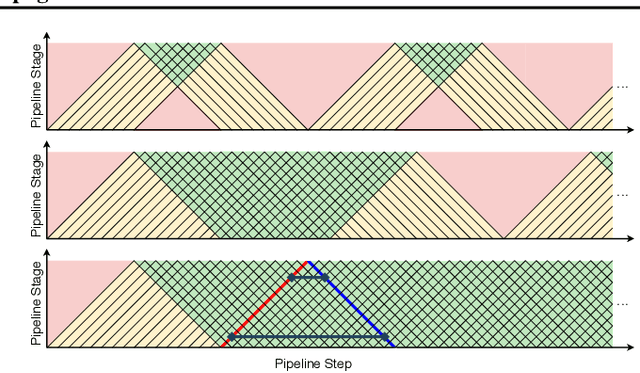
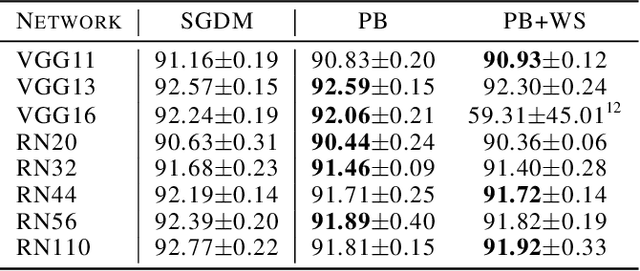
Parallelism is crucial for accelerating the training of deep neural networks. Pipeline parallelism can provide an efficient alternative to traditional data parallelism by allowing workers to specialize. Performing mini-batch SGD using pipeline parallelism has the overhead of filling and draining the pipeline. Pipelined Backpropagation updates the model parameters without draining the pipeline. This removes the overhead but introduces stale gradients and inconsistency between the weights used on the forward and backward passes, reducing final accuracy and the stability of training. We introduce Spike Compensation and Linear Weight Prediction to mitigate these effects. Analysis on a convex quadratic shows that both methods effectively counteract staleness. We train multiple convolutional networks at a batch size of one, completely replacing batch parallelism with fine-grained pipeline parallelism. With our methods, Pipelined Backpropagation achieves full accuracy on CIFAR-10 and ImageNet without hyperparameter tuning.