 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2025 Foundation Model Transparency Index
Dec 11, 2025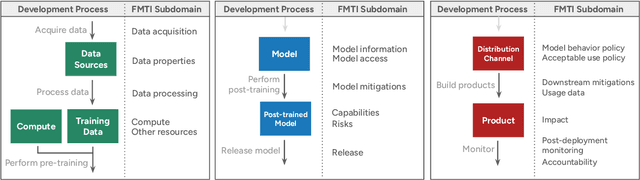
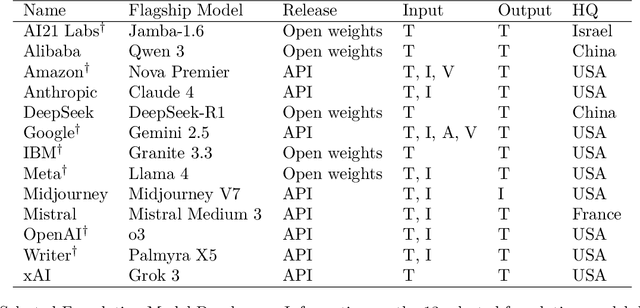
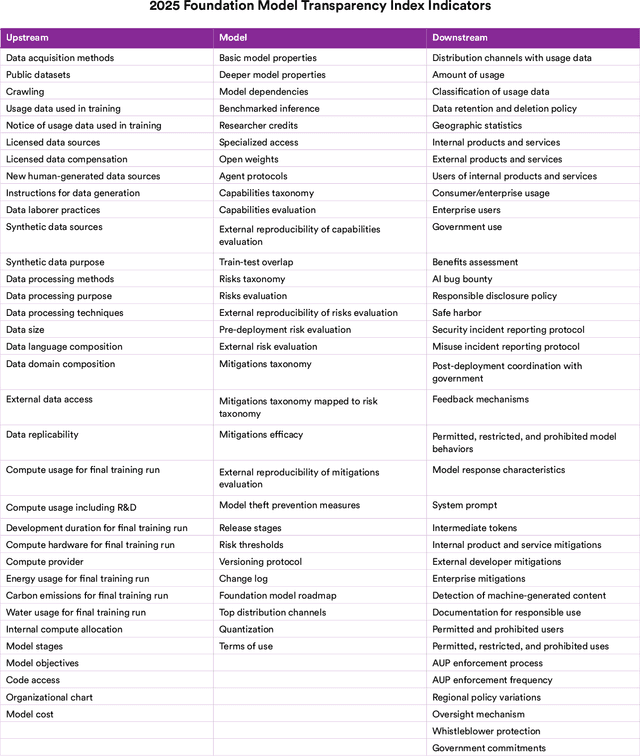
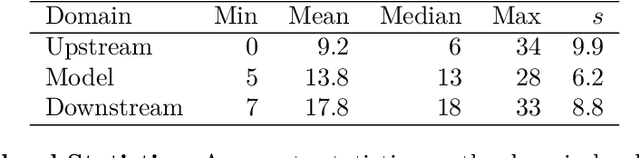
Foundation model developers are among the world's most important companies. As these companies become increasingly consequential, how do their transparency practices evolve? The 2025 Foundation Model Transparency Index is the third edition of an annual effort to characterize and quantify the transparency of foundation model developers. The 2025 FMTI introduces new indicators related to data acquisition, usage data, and monitoring and evaluates companies like Alibaba, DeepSeek, and xAI for the first time. The 2024 FMTI reported that transparency was improving, but the 2025 FMTI finds this progress has deteriorated: the average score out of 100 fell from 58 in 2024 to 40 in 2025. Companies are most opaque about their training data and training compute as well as the post-deployment usage and impact of their flagship models. In spite of this general trend, IBM stands out as a positive outlier, scoring 95, in contrast to the lowest scorers, xAI and Midjourney, at just 14. The five members of the Frontier Model Forum we score end up in the middle of the Index: we posit that these companies avoid reputational harms from low scores but lack incentives to be transparency leaders. As policymakers around the world increasingly mandate certain types of transparency, this work reveals the current state of transparency for foundation model developers, how it may change given newly enacted policy, and where more aggressive policy interventions are necessary to address critical information deficits.
The Foundation Model Transparency Index v1.1: May 2024
Jul 17, 2024Foundation models are increasingly consequential yet extremely opaque. To characterize the status quo, the Foundation Model Transparency Index was launched in October 2023 to measure the transparency of leading foundation model developers. The October 2023 Index (v1.0) assessed 10 major foundation model developers (e.g. OpenAI, Google) on 100 transparency indicators (e.g. does the developer disclose the wages it pays for data labor?). At the time, developers publicly disclosed very limited information with the average score being 37 out of 100. To understand how the status quo has changed, we conduct a follow-up study (v1.1) after 6 months: we score 14 developers against the same 100 indicators. While in v1.0 we searched for publicly available information, in v1.1 developers submit reports on the 100 transparency indicators, potentially including information that was not previously public. We find that developers now score 58 out of 100 on average, a 21 point improvement over v1.0. Much of this increase is driven by developers disclosing information during the v1.1 process: on average, developers disclosed information related to 16.6 indicators that was not previously public. We observe regions of sustained (i.e. across v1.0 and v1.1) and systemic (i.e. across most or all developers) opacity such as on copyright status, data access, data labor, and downstream impact. We publish transparency reports for each developer that consolidate information disclosures: these reports are based on the information disclosed to us via developers. Our findings demonstrate that transparency can be improved in this nascent ecosystem, the Foundation Model Transparency Index likely contributes to these improvements, and policymakers should consider interventions in areas where transparency has not improved.
Assessing The Potential Of Mid-Sized Language Models For Clinical QA
Apr 24, 2024



Large language models, such as GPT-4 and Med-PaLM, have shown impressive performance on clinical tasks; however, they require access to compute, are closed-source, and cannot be deployed on device. Mid-size models such as BioGPT-large, BioMedLM, LLaMA 2, and Mistral 7B avoid these drawbacks, but their capacity for clinical tasks has been understudied. To help assess their potential for clinical use and help researchers decide which model they should use, we compare their performance on two clinical question-answering (QA) tasks: MedQA and consumer query answering. We find that Mistral 7B is the best performing model, winning on all benchmarks and outperforming models trained specifically for the biomedical domain. While Mistral 7B's MedQA score of 63.0% approaches the original Med-PaLM, and it often can produce plausible responses to consumer health queries, room for improvement still exists. This study provides the first head-to-head assessment of open source mid-sized models on clinical tasks.
BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
Mar 27, 2024Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
Foundation Model Transparency Reports
Feb 26, 2024Foundation models are critical digital technologies with sweeping societal impact that necessitates transparency. To codify how foundation model developers should provide transparency about the development and deployment of their models, we propose Foundation Model Transparency Reports, drawing upon the transparency reporting practices in social media. While external documentation of societal harms prompted social media transparency reports, our objective is to institutionalize transparency reporting for foundation models while the industry is still nascent. To design our reports, we identify 6 design principles given the successes and shortcomings of social media transparency reporting. To further schematize our reports, we draw upon the 100 transparency indicators from the Foundation Model Transparency Index. Given these indicators, we measure the extent to which they overlap with the transparency requirements included in six prominent government policies (e.g., the EU AI Act, the US Executive Order on Safe, Secure, and Trustworthy AI). Well-designed transparency reports could reduce compliance costs, in part due to overlapping regulatory requirements across different jurisdictions. We encourage foundation model developers to regularly publish transparency reports, building upon recommendations from the G7 and the White House.
The Foundation Model Transparency Index
Oct 19, 2023Foundation models have rapidly permeated society, catalyzing a wave of generative AI applications spanning enterprise and consumer-facing contexts. While the societal impact of foundation models is growing, transparency is on the decline, mirroring the opacity that has plagued past digital technologies (e.g. social media). Reversing this trend is essential: transparency is a vital precondition for public accountability, scientific innovation, and effective governance. To assess the transparency of the foundation model ecosystem and help improve transparency over time, we introduce the Foundation Model Transparency Index. The Foundation Model Transparency Index specifies 100 fine-grained indicators that comprehensively codify transparency for foundation models, spanning the upstream resources used to build a foundation model (e.g data, labor, compute), details about the model itself (e.g. size, capabilities, risks), and the downstream use (e.g. distribution channels, usage policies, affected geographies). We score 10 major foundation model developers (e.g. OpenAI, Google, Meta) against the 100 indicators to assess their transparency. To facilitate and standardize assessment, we score developers in relation to their practices for their flagship foundation model (e.g. GPT-4 for OpenAI, PaLM 2 for Google, Llama 2 for Meta). We present 10 top-level findings about the foundation model ecosystem: for example, no developer currently discloses significant information about the downstream impact of its flagship model, such as the number of users, affected market sectors, or how users can seek redress for harm. Overall, the Foundation Model Transparency Index establishes the level of transparency today to drive progress on foundation model governance via industry standards and regulatory intervention.