 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Upcycling: Inference Inefficient Finetuning
Nov 13, 2024



Small, highly trained, open-source large language models are widely used due to their inference efficiency, but further improving their quality remains a challenge. Sparse upcycling is a promising approach that transforms a pretrained dense model into a Mixture-of-Experts (MoE) architecture, increasing the model's parameter count and quality. In this work, we compare the effectiveness of sparse upcycling against continued pretraining (CPT) across different model sizes, compute budgets, and pretraining durations. Our experiments show that sparse upcycling can achieve better quality, with improvements of over 20% relative to CPT in certain scenarios. However, this comes with a significant inference cost, leading to 40% slowdowns in high-demand inference settings for larger models. Our findings highlight the trade-off between model quality and inference efficiency, offering insights for practitioners seeking to balance model quality and deployment constraints.
LoRA Learns Less and Forgets Less
May 15, 2024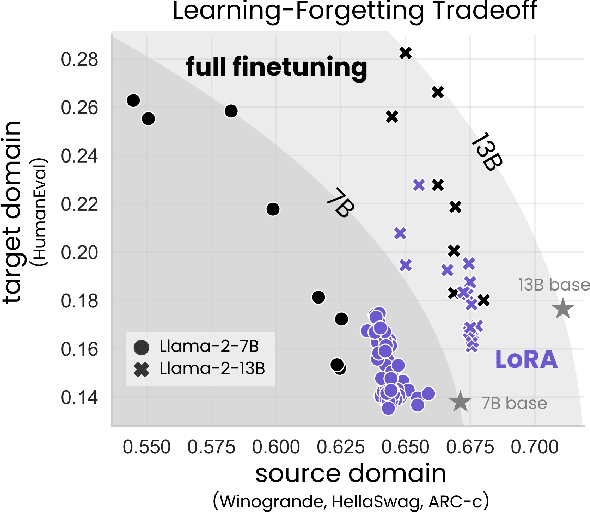

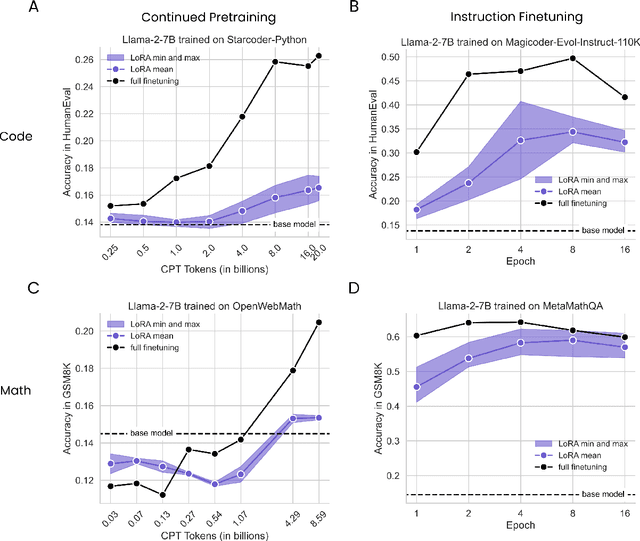

Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning ($\approx$100K prompt-response pairs) and continued pretraining ($\approx$10B unstructured tokens) data regimes. Our results show that, in most settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA exhibits a desirable form of regularization: it better maintains the base model's performance on tasks outside the target domain. We show that LoRA provides stronger regularization compared to common techniques such as weight decay and dropout; it also helps maintain more diverse generations. We show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
RevBiFPN: The Fully Reversible Bidirectional Feature Pyramid Network
Jun 28, 2022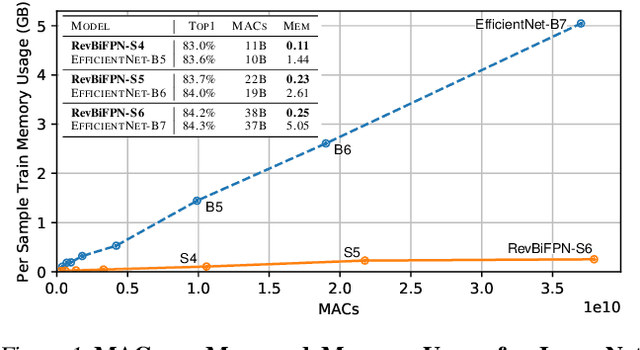
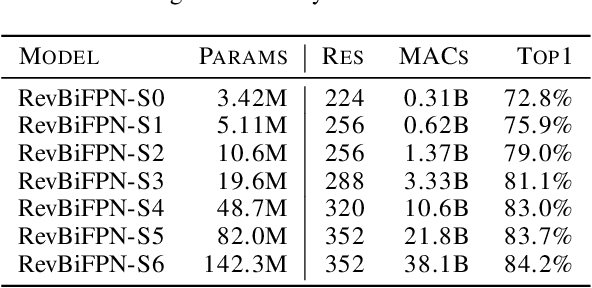
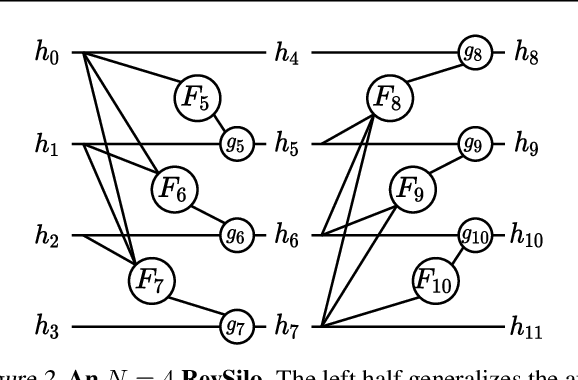
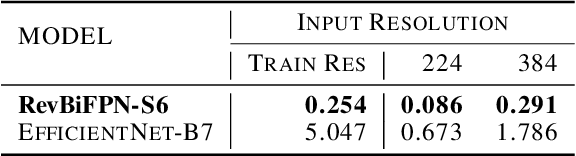
This work introduces the RevSilo, the first reversible module for bidirectional multi-scale feature fusion. Like other reversible methods, RevSilo eliminates the need to store hidden activations by recomputing them. Existing reversible methods, however, do not apply to multi-scale feature fusion and are therefore not applicable to a large class of networks. Bidirectional multi-scale feature fusion promotes local and global coherence and has become a de facto design principle for networks targeting spatially sensitive tasks e.g. HRNet and EfficientDet. When paired with high-resolution inputs, these networks achieve state-of-the-art results across various computer vision tasks, but training them requires substantial accelerator memory for saving large, multi-resolution activations. These memory requirements cap network size and limit progress. Using reversible recomputation, the RevSilo alleviates memory issues while still operating across resolution scales. Stacking RevSilos, we create RevBiFPN, a fully reversible bidirectional feature pyramid network. For classification, RevBiFPN is competitive with networks such as EfficientNet while using up to 19.8x lesser training memory. When fine-tuned on COCO, RevBiFPN provides up to a 2.5% boost in AP over HRNet using fewer MACs and a 2.4x reduction in training-time memory.
Memory Efficient 3D U-Net with Reversible Mobile Inverted Bottlenecks for Brain Tumor Segmentation
Apr 21, 2021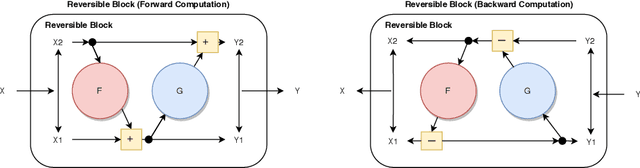

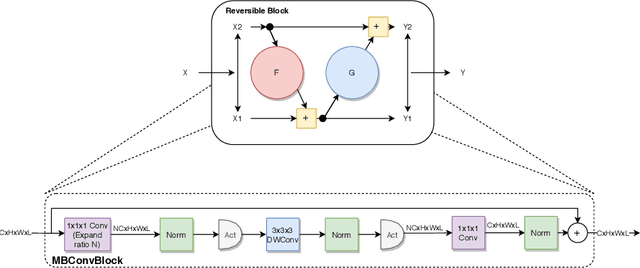
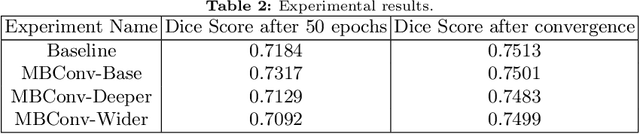
We propose combining memory saving techniques with traditional U-Net architectures to increase the complexity of the models on the Brain Tumor Segmentation (BraTS) challenge. The BraTS challenge consists of a 3D segmentation of a 240x240x155x4 input image into a set of tumor classes. Because of the large volume and need for 3D convolutional layers, this task is very memory intensive. To address this, prior approaches use smaller cropped images while constraining the model's depth and width. Our 3D U-Net uses a reversible version of the mobile inverted bottleneck block defined in MobileNetV2, MnasNet and the more recent EfficientNet architectures to save activation memory during training. Using reversible layers enables the model to recompute input activations given the outputs of that layer, saving memory by eliminating the need to store activations during the forward pass. The inverted residual bottleneck block uses lightweight depthwise separable convolutions to reduce computation by decomposing convolutions into a pointwise convolution and a depthwise convolution. Further, this block inverts traditional bottleneck blocks by placing an intermediate expansion layer between the input and output linear 1x1 convolution, reducing the total number of channels. Given a fixed memory budget, with these memory saving techniques, we are able to train image volumes up to 3x larger, models with 25% more depth, or models with up to 2x the number of channels than a corresponding non-reversible network.
* 11 pages, 5 figures, Published at MICCAI Brainles 2020
Adaptive Braking for Mitigating Gradient Delay
Jul 10, 2020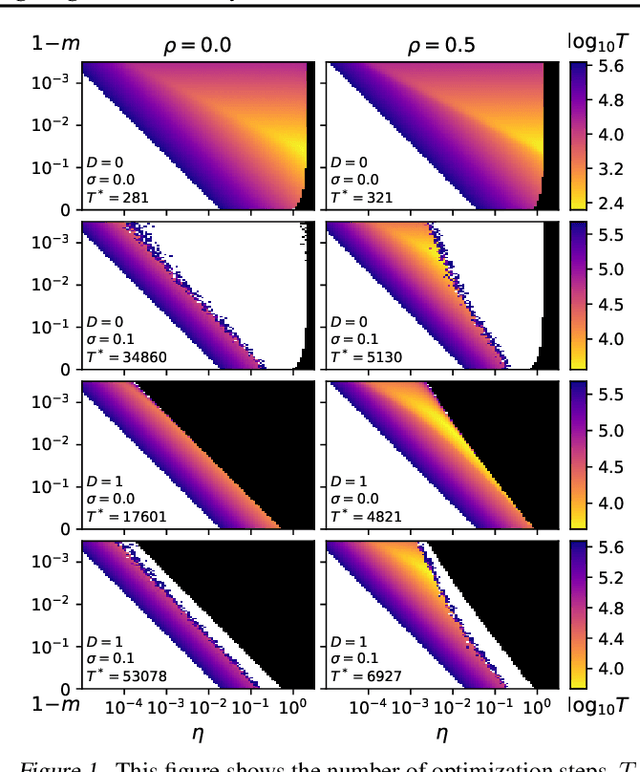
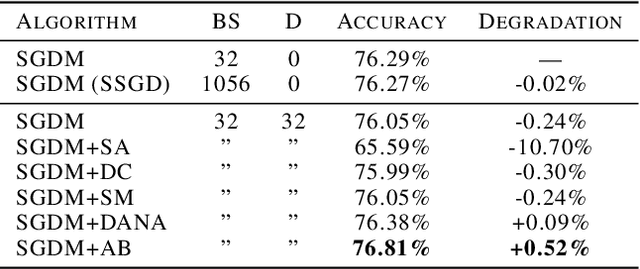
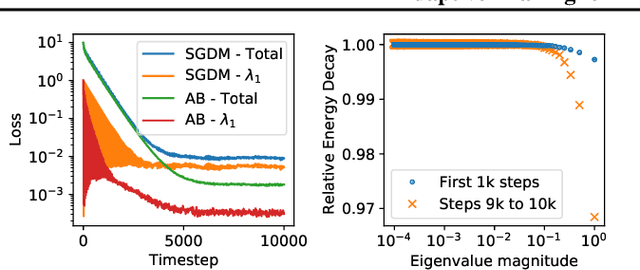

Neural network training is commonly accelerated by using multiple synchronized workers to compute gradient updates in parallel. Asynchronous methods remove synchronization overheads and improve hardware utilization at the cost of introducing gradient delay, which impedes optimization and can lead to lower final model performance. We introduce Adaptive Braking (AB), a modification for momentum-based optimizers that mitigates the effects of gradient delay. AB dynamically scales the gradient based on the alignment of the gradient and the velocity. This can dampen oscillations along high curvature directions of the loss surface, stabilizing and accelerating asynchronous training. We show that applying AB on top of SGD with momentum enables training ResNets on CIFAR-10 and ImageNet-1k with delays $D \geq$ 32 update steps with minimal drop in final test accuracy.
Pipelined Backpropagation at Scale: Training Large Models without Batches
Mar 25, 2020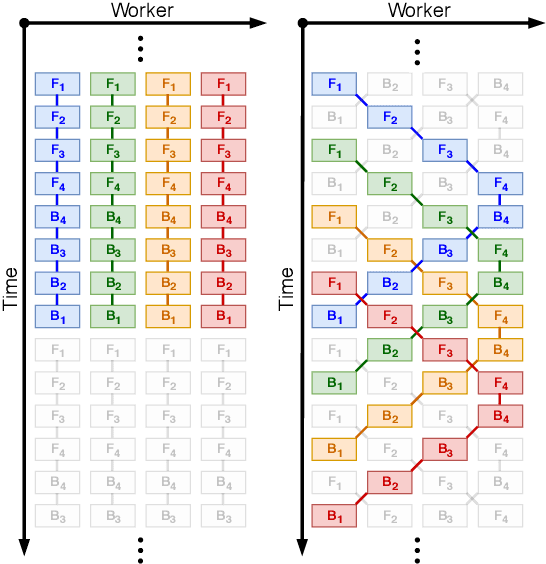
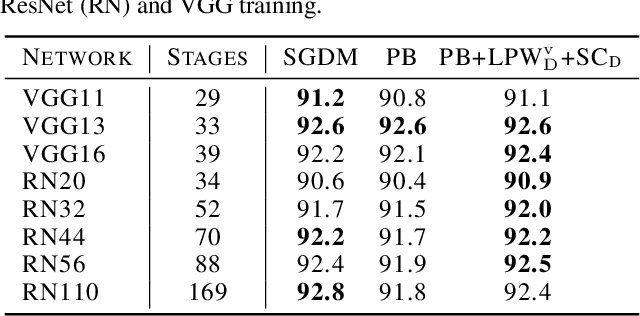
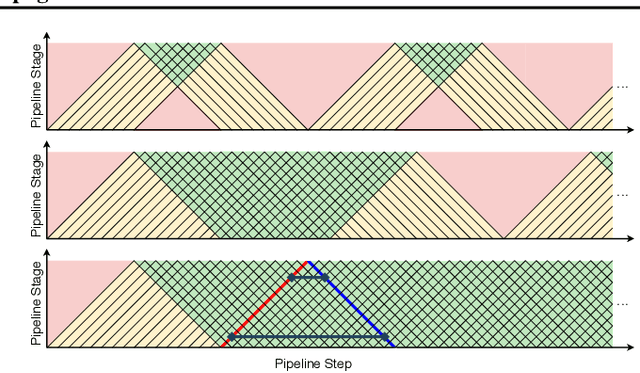
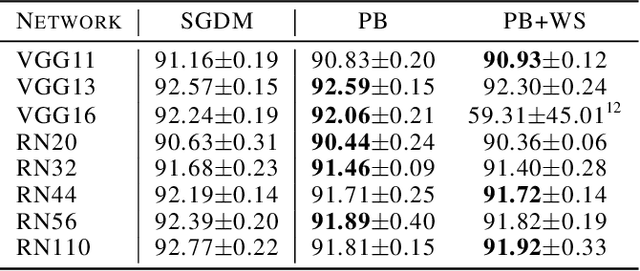
Parallelism is crucial for accelerating the training of deep neural networks. Pipeline parallelism can provide an efficient alternative to traditional data parallelism by allowing workers to specialize. Performing mini-batch SGD using pipeline parallelism has the overhead of filling and draining the pipeline. Pipelined Backpropagation updates the model parameters without draining the pipeline. This removes the overhead but introduces stale gradients and inconsistency between the weights used on the forward and backward passes, reducing final accuracy and the stability of training. We introduce Spike Compensation and Linear Weight Prediction to mitigate these effects. Analysis on a convex quadratic shows that both methods effectively counteract staleness. We train multiple convolutional networks at a batch size of one, completely replacing batch parallelism with fine-grained pipeline parallelism. With our methods, Pipelined Backpropagation achieves full accuracy on CIFAR-10 and ImageNet without hyperparameter tuning.
Online Normalization for Training Neural Networks
May 28, 2019
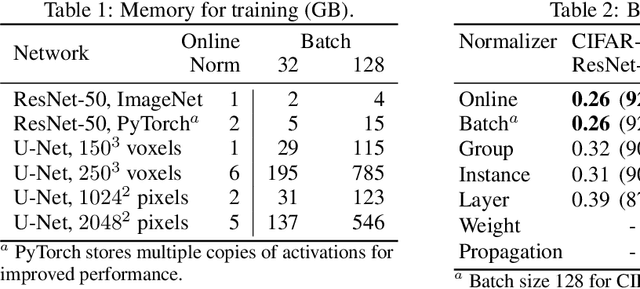
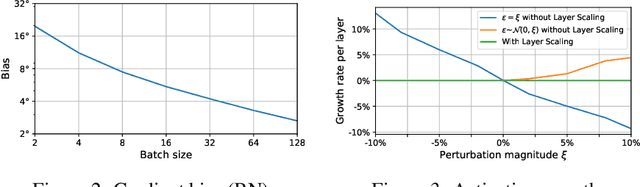
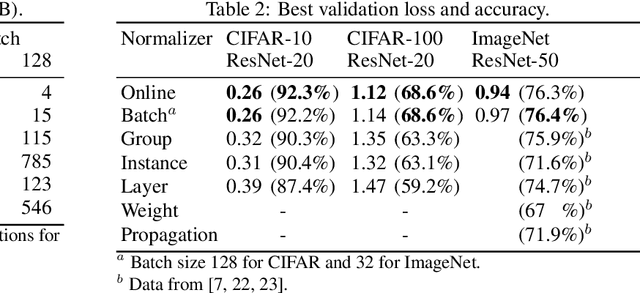
Online Normalization is a new technique for normalizing the hidden activations of a neural network. Like Batch Normalization, it normalizes the sample dimension. While Online Normalization does not use batches, it is as accurate as Batch Normalization. We resolve a theoretical limitation of Batch Normalization by introducing an unbiased technique for computing the gradient of normalized activations. Online Normalization works with automatic differentiation by adding statistical normalization as a primitive. This technique can be used in cases not covered by some other normalizers, such as recurrent networks, fully connected networks, and networks with activation memory requirements prohibitive for batching. We show its applications to image classification, image segmentation, and language modeling. We present formal proofs and experimental results on ImageNet, CIFAR, and PTB datasets.