 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Capabilities of Large Language Models Scale with Pretraining FLOPs
Aug 24, 2025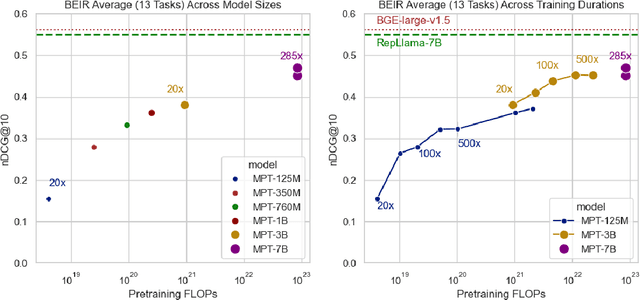
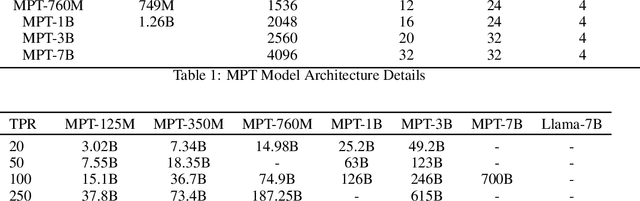


How does retrieval performance scale with pretraining FLOPs? We benchmark retrieval performance across LLM model sizes from 125 million parameters to 7 billion parameters pretrained on datasets ranging from 1 billion tokens to more than 2 trillion tokens. We find that retrieval performance on zero-shot BEIR tasks predictably scales with LLM size, training duration, and estimated FLOPs. We also show that In-Context Learning scores are strongly correlated with retrieval scores across retrieval tasks. Finally, we highlight the implications this has for the development of LLM-based retrievers.
Sparse Upcycling: Inference Inefficient Finetuning
Nov 13, 2024



Small, highly trained, open-source large language models are widely used due to their inference efficiency, but further improving their quality remains a challenge. Sparse upcycling is a promising approach that transforms a pretrained dense model into a Mixture-of-Experts (MoE) architecture, increasing the model's parameter count and quality. In this work, we compare the effectiveness of sparse upcycling against continued pretraining (CPT) across different model sizes, compute budgets, and pretraining durations. Our experiments show that sparse upcycling can achieve better quality, with improvements of over 20% relative to CPT in certain scenarios. However, this comes with a significant inference cost, leading to 40% slowdowns in high-demand inference settings for larger models. Our findings highlight the trade-off between model quality and inference efficiency, offering insights for practitioners seeking to balance model quality and deployment constraints.
Scalable Neural Data Server: A Data Recommender for Transfer Learning
Jun 19, 2022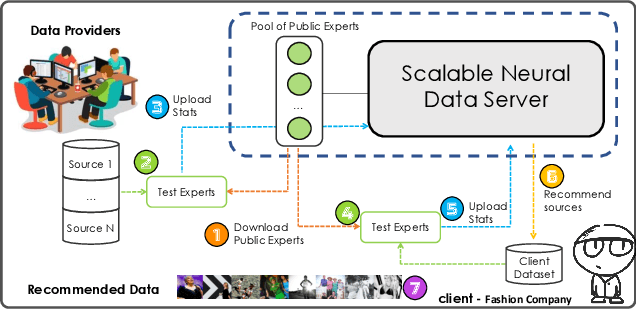
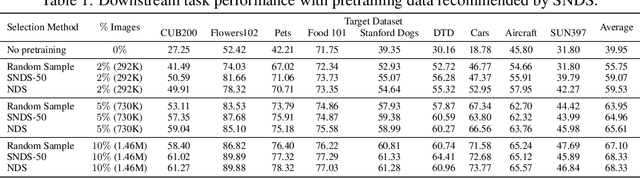
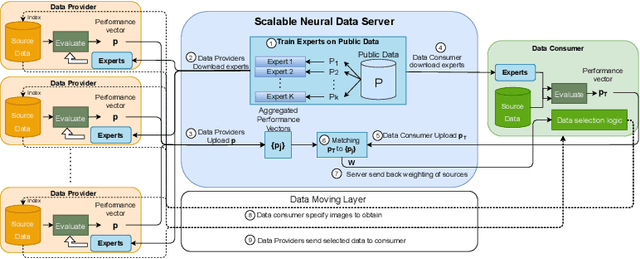
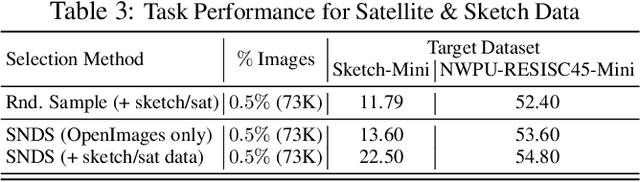
Absence of large-scale labeled data in the practitioner's target domain can be a bottleneck to applying machine learning algorithms in practice. Transfer learning is a popular strategy for leveraging additional data to improve the downstream performance, but finding the most relevant data to transfer from can be challenging. Neural Data Server (NDS), a search engine that recommends relevant data for a given downstream task, has been previously proposed to address this problem. NDS uses a mixture of experts trained on data sources to estimate similarity between each source and the downstream task. Thus, the computational cost to each user grows with the number of sources. To address these issues, we propose Scalable Neural Data Server (SNDS), a large-scale search engine that can theoretically index thousands of datasets to serve relevant ML data to end users. SNDS trains the mixture of experts on intermediary datasets during initialization, and represents both data sources and downstream tasks by their proximity to the intermediary datasets. As such, computational cost incurred by SNDS users remains fixed as new datasets are added to the server. We validate SNDS on a plethora of real world tasks and find that data recommended by SNDS improves downstream task performance over baselines. We also demonstrate the scalability of SNDS by showing its ability to select relevant data for transfer outside of the natural image setting.
* Neurips 2021
Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars
Dec 23, 2020



We are interested in understanding whether retrieval-based localization approaches are good enough in the context of self-driving vehicles. Towards this goal, we introduce Pit30M, a new image and LiDAR dataset with over 30 million frames, which is 10 to 100 times larger than those used in previous work. Pit30M is captured under diverse conditions (i.e., season, weather, time of the day, traffic), and provides accurate localization ground truth. We also automatically annotate our dataset with historical weather and astronomical data, as well as with image and LiDAR semantic segmentation as a proxy measure for occlusion. We benchmark multiple existing methods for image and LiDAR retrieval and, in the process, introduce a simple, yet effective convolutional network-based LiDAR retrieval method that is competitive with the state of the art. Our work provides, for the first time, a benchmark for sub-metre retrieval-based localization at city scale. The dataset, additional experimental results, as well as more information about the sensors, calibration, and metadata, are available on the project website: https://uber.com/atg/datasets/pit30m