 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapiens2
Apr 23, 2026We present Sapiens2, a model family of high-resolution transformers for human-centric vision focused on generalization, versatility, and high-fidelity outputs. Our model sizes range from 0.4 to 5 billion parameters, with native 1K resolution and hierarchical variants that support 4K. Sapiens2 substantially improves over its predecessor in both pretraining and post-training. First, to learn features that capture low-level details (for dense prediction) and high-level semantics (for zero-shot or few-label settings), we combine masked image reconstruction with self-distilled contrastive objectives. Our evaluations show that this unified pretraining objective is better suited for a wider range of downstream tasks. Second, along the data axis, we pretrain on a curated dataset of 1 billion high-quality human images and improve the quality and quantity of task annotations. Third, architecturally, we incorporate advances from frontier models that enable longer training schedules with improved stability. Our 4K models adopt windowed attention to reason over longer spatial context and are pretrained with 2K output resolution. Sapiens2 sets a new state-of-the-art and improves over the first generation on pose (+4 mAP), body-part segmentation (+24.3 mIoU), normal estimation (45.6% lower angular error) and extends to new tasks such as pointmap and albedo estimation. Code: https://github.com/facebookresearch/sapiens2
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
Pippo: High-Resolution Multi-View Humans from a Single Image
Feb 11, 2025
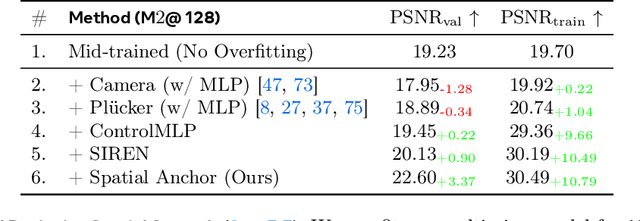
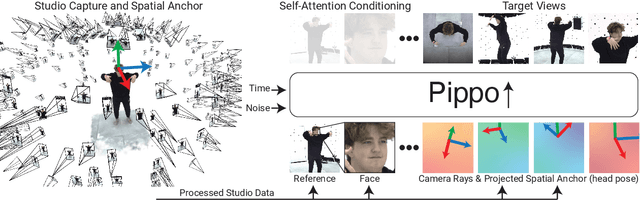

We present Pippo, a generative model capable of producing 1K resolution dense turnaround videos of a person from a single casually clicked photo. Pippo is a multi-view diffusion transformer and does not require any additional inputs - e.g., a fitted parametric model or camera parameters of the input image. We pre-train Pippo on 3B human images without captions, and conduct multi-view mid-training and post-training on studio captured humans. During mid-training, to quickly absorb the studio dataset, we denoise several (up to 48) views at low-resolution, and encode target cameras coarsely using a shallow MLP. During post-training, we denoise fewer views at high-resolution and use pixel-aligned controls (e.g., Spatial anchor and Plucker rays) to enable 3D consistent generations. At inference, we propose an attention biasing technique that allows Pippo to simultaneously generate greater than 5 times as many views as seen during training. Finally, we also introduce an improved metric to evaluate 3D consistency of multi-view generations, and show that Pippo outperforms existing works on multi-view human generation from a single image.
Sapiens: Foundation for Human Vision Models
Aug 22, 2024



We present Sapiens, a family of models for four fundamental human-centric vision tasks - 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. Our models natively support 1K high-resolution inference and are extremely easy to adapt for individual tasks by simply fine-tuning models pretrained on over 300 million in-the-wild human images. We observe that, given the same computational budget, self-supervised pretraining on a curated dataset of human images significantly boosts the performance for a diverse set of human-centric tasks. The resulting models exhibit remarkable generalization to in-the-wild data, even when labeled data is scarce or entirely synthetic. Our simple model design also brings scalability - model performance across tasks improves as we scale the number of parameters from 0.3 to 2 billion. Sapiens consistently surpasses existing baselines across various human-centric benchmarks. We achieve significant improvements over the prior state-of-the-art on Humans-5K (pose) by 7.6 mAP, Humans-2K (part-seg) by 17.1 mIoU, Hi4D (depth) by 22.4% relative RMSE, and THuman2 (normal) by 53.5% relative angular error.
Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
Jan 19, 2021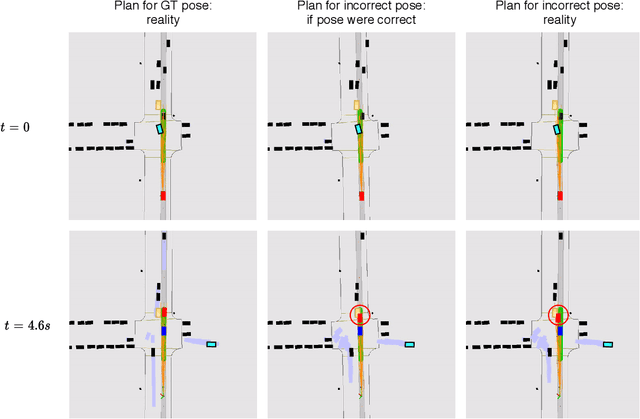

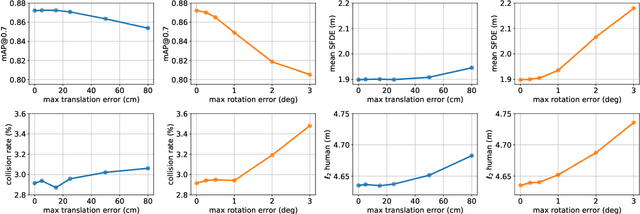

Over the last few years, we have witnessed tremendous progress on many subtasks of autonomous driving, including perception, motion forecasting, and motion planning. However, these systems often assume that the car is accurately localized against a high-definition map. In this paper we question this assumption, and investigate the issues that arise in state-of-the-art autonomy stacks under localization error. Based on our observations, we design a system that jointly performs perception, prediction, and localization. Our architecture is able to reuse computation between both tasks, and is thus able to correct localization errors efficiently. We show experiments on a large-scale autonomy dataset, demonstrating the efficiency and accuracy of our proposed approach.
Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars
Dec 23, 2020



We are interested in understanding whether retrieval-based localization approaches are good enough in the context of self-driving vehicles. Towards this goal, we introduce Pit30M, a new image and LiDAR dataset with over 30 million frames, which is 10 to 100 times larger than those used in previous work. Pit30M is captured under diverse conditions (i.e., season, weather, time of the day, traffic), and provides accurate localization ground truth. We also automatically annotate our dataset with historical weather and astronomical data, as well as with image and LiDAR semantic segmentation as a proxy measure for occlusion. We benchmark multiple existing methods for image and LiDAR retrieval and, in the process, introduce a simple, yet effective convolutional network-based LiDAR retrieval method that is competitive with the state of the art. Our work provides, for the first time, a benchmark for sub-metre retrieval-based localization at city scale. The dataset, additional experimental results, as well as more information about the sensors, calibration, and metadata, are available on the project website: https://uber.com/atg/datasets/pit30m
Learning to Localize Through Compressed Binary Maps
Dec 20, 2020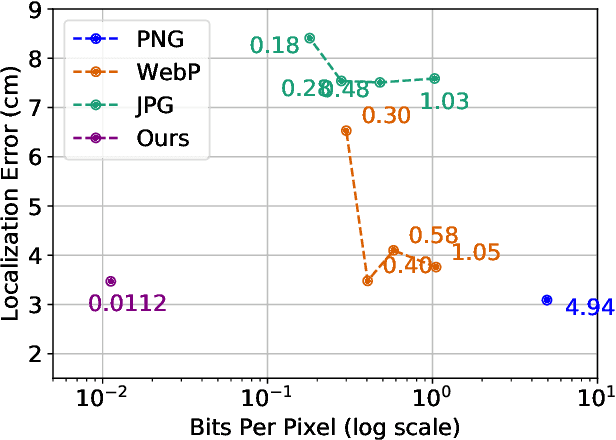
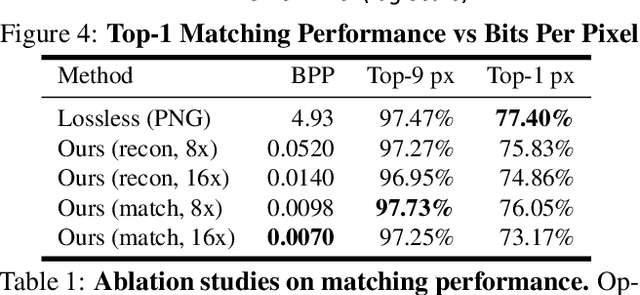
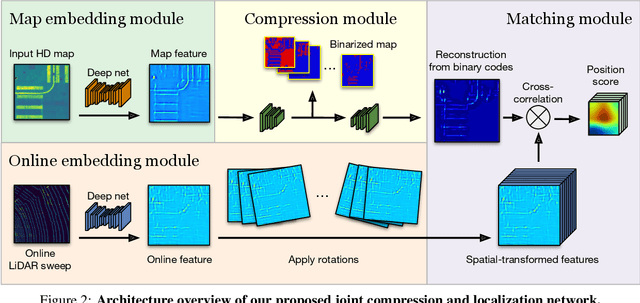
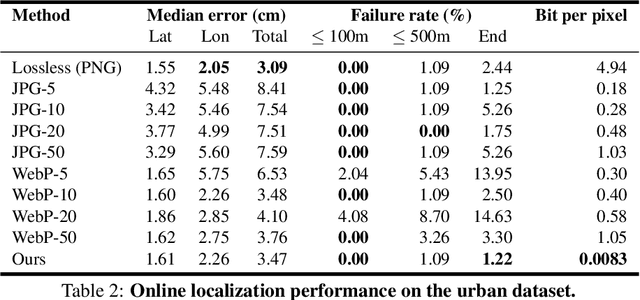
One of the main difficulties of scaling current localization systems to large environments is the on-board storage required for the maps. In this paper we propose to learn to compress the map representation such that it is optimal for the localization task. As a consequence, higher compression rates can be achieved without loss of localization accuracy when compared to standard coding schemes that optimize for reconstruction, thus ignoring the end task. Our experiments show that it is possible to learn a task-specific compression which reduces storage requirements by two orders of magnitude over general-purpose codecs such as WebP without sacrificing performance.
* 18 pages, 12 figures, 6 tables; Presented at CVPR 2019
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
Oct 29, 2020



Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
A simple yet effective baseline for 3d human pose estimation
Aug 04, 2017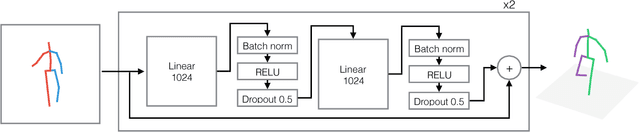
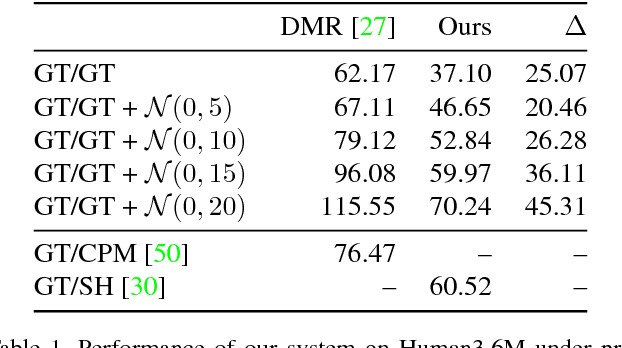
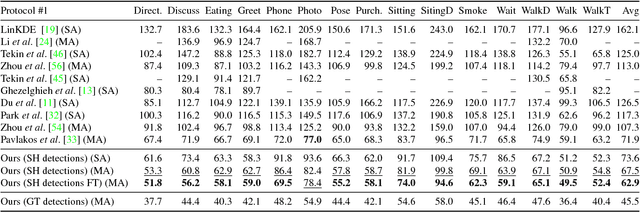
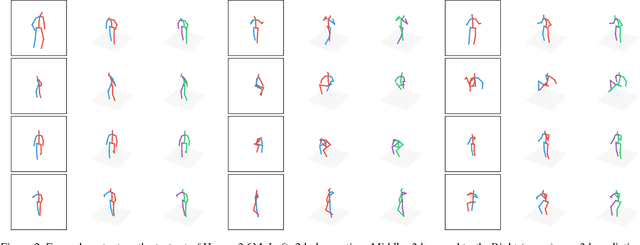
Following the success of deep convolutional networks, state-of-the-art methods for 3d human pose estimation have focused on deep end-to-end systems that predict 3d joint locations given raw image pixels. Despite their excellent performance, it is often not easy to understand whether their remaining error stems from a limited 2d pose (visual) understanding, or from a failure to map 2d poses into 3-dimensional positions. With the goal of understanding these sources of error, we set out to build a system that given 2d joint locations predicts 3d positions. Much to our surprise, we have found that, with current technology, "lifting" ground truth 2d joint locations to 3d space is a task that can be solved with a remarkably low error rate: a relatively simple deep feed-forward network outperforms the best reported result by about 30\% on Human3.6M, the largest publicly available 3d pose estimation benchmark. Furthermore, training our system on the output of an off-the-shelf state-of-the-art 2d detector (\ie, using images as input) yields state of the art results -- this includes an array of systems that have been trained end-to-end specifically for this task. Our results indicate that a large portion of the error of modern deep 3d pose estimation systems stems from their visual analysis, and suggests directions to further advance the state of the art in 3d human pose estimation.
On human motion prediction using recurrent neural networks
May 06, 2017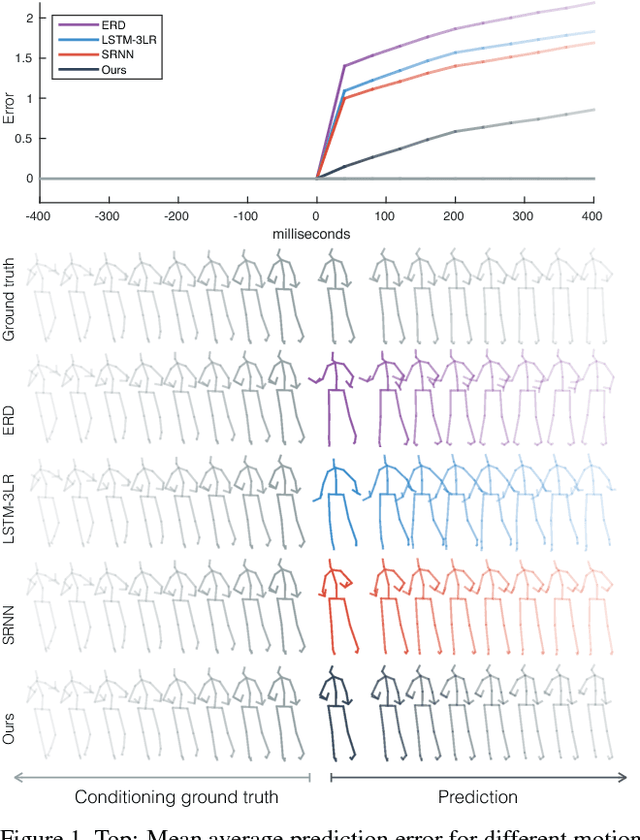
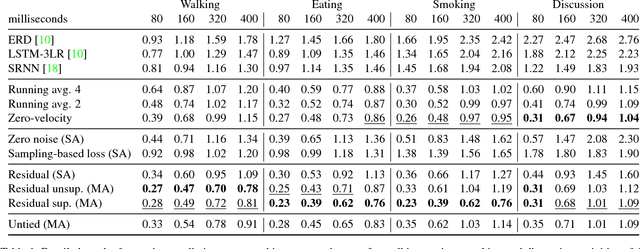
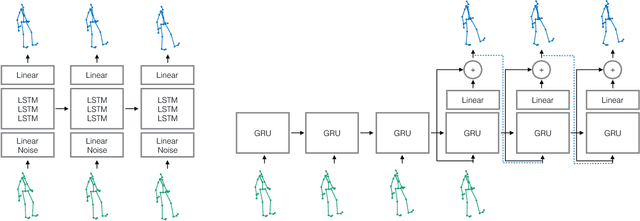
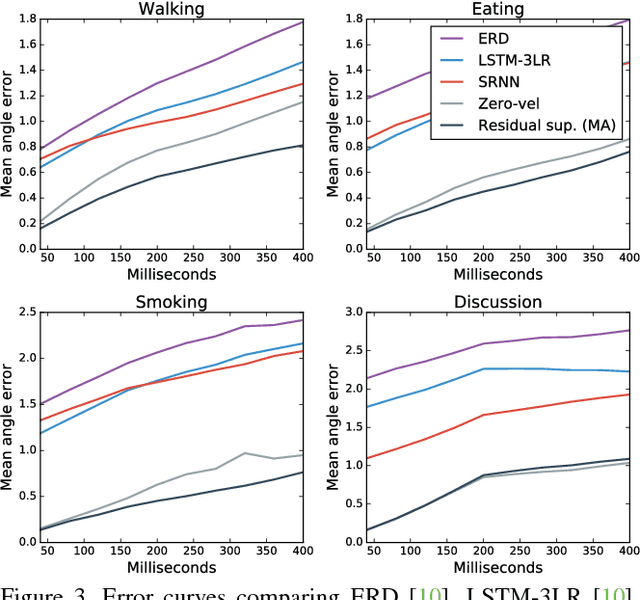
Human motion modelling is a classical problem at the intersection of graphics and computer vision, with applications spanning human-computer interaction, motion synthesis, and motion prediction for virtual and augmented reality. Following the success of deep learning methods in several computer vision tasks, recent work has focused on using deep recurrent neural networks (RNNs) to model human motion, with the goal of learning time-dependent representations that perform tasks such as short-term motion prediction and long-term human motion synthesis. We examine recent work, with a focus on the evaluation methodologies commonly used in the literature, and show that, surprisingly, state-of-the-art performance can be achieved by a simple baseline that does not attempt to model motion at all. We investigate this result, and analyze recent RNN methods by looking at the architectures, loss functions, and training procedures used in state-of-the-art approaches. We propose three changes to the standard RNN models typically used for human motion, which result in a simple and scalable RNN architecture that obtains state-of-the-art performance on human motion prediction.