 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Apr 01, 2024

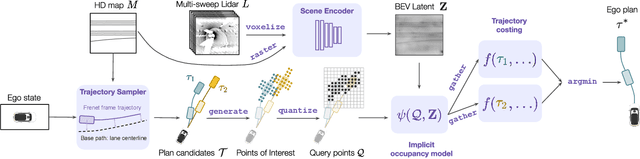

A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
Jan 19, 2021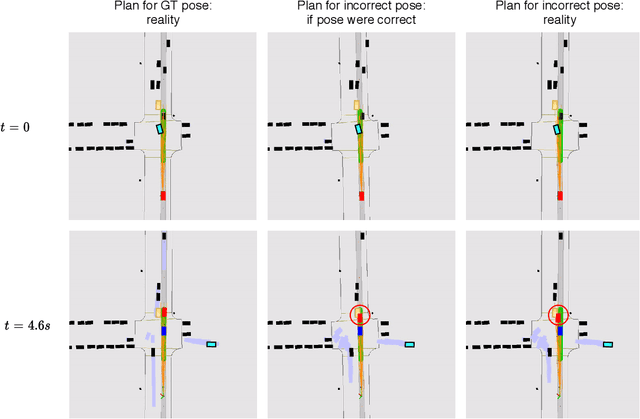

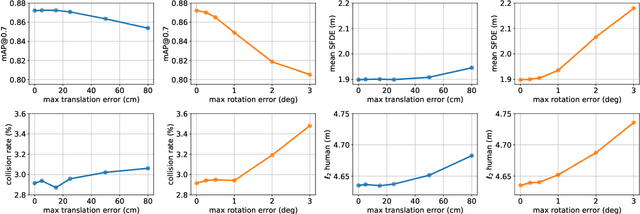

Over the last few years, we have witnessed tremendous progress on many subtasks of autonomous driving, including perception, motion forecasting, and motion planning. However, these systems often assume that the car is accurately localized against a high-definition map. In this paper we question this assumption, and investigate the issues that arise in state-of-the-art autonomy stacks under localization error. Based on our observations, we design a system that jointly performs perception, prediction, and localization. Our architecture is able to reuse computation between both tasks, and is thus able to correct localization errors efficiently. We show experiments on a large-scale autonomy dataset, demonstrating the efficiency and accuracy of our proposed approach.
MP3: A Unified Model to Map, Perceive, Predict and Plan
Jan 18, 2021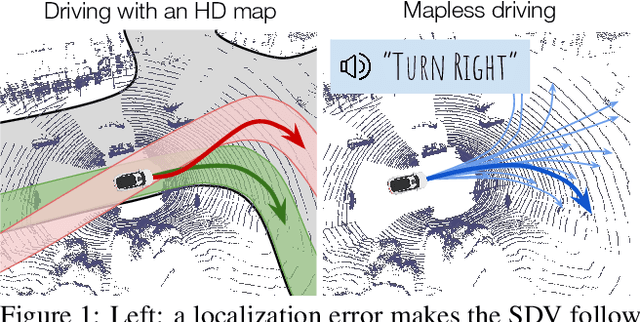
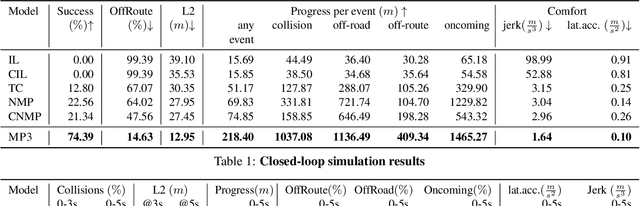
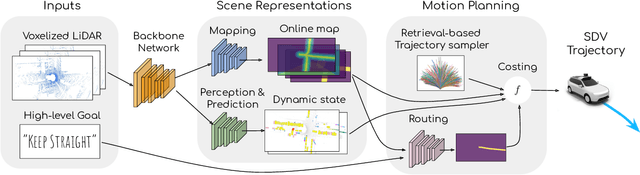

High-definition maps (HD maps) are a key component of most modern self-driving systems due to their valuable semantic and geometric information. Unfortunately, building HD maps has proven hard to scale due to their cost as well as the requirements they impose in the localization system that has to work everywhere with centimeter-level accuracy. Being able to drive without an HD map would be very beneficial to scale self-driving solutions as well as to increase the failure tolerance of existing ones (e.g., if localization fails or the map is not up-to-date). Towards this goal, we propose MP3, an end-to-end approach to mapless driving where the input is raw sensor data and a high-level command (e.g., turn left at the intersection). MP3 predicts intermediate representations in the form of an online map and the current and future state of dynamic agents, and exploits them in a novel neural motion planner to make interpretable decisions taking into account uncertainty. We show that our approach is significantly safer, more comfortable, and can follow commands better than the baselines in challenging long-term closed-loop simulations, as well as when compared to an expert driver in a large-scale real-world dataset.
End-to-end Interpretable Neural Motion Planner
Jan 17, 2021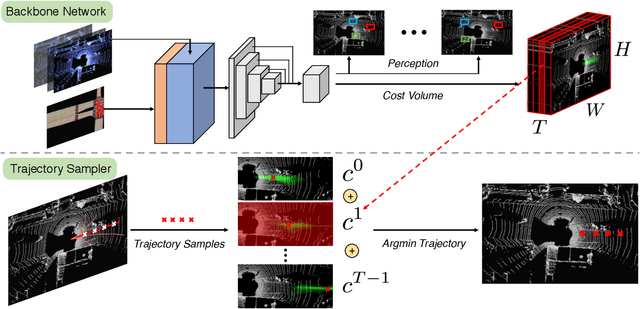
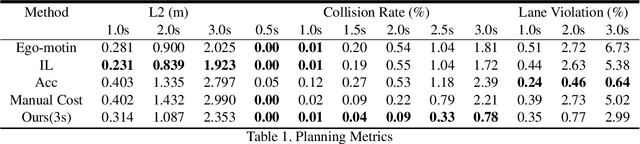
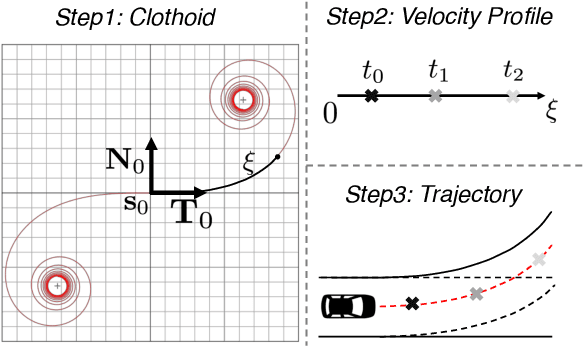

In this paper, we propose a neural motion planner (NMP) for learning to drive autonomously in complex urban scenarios that include traffic-light handling, yielding, and interactions with multiple road-users. Towards this goal, we design a holistic model that takes as input raw LIDAR data and a HD map and produces interpretable intermediate representations in the form of 3D detections and their future trajectories, as well as a cost volume defining the goodness of each position that the self-driving car can take within the planning horizon. We then sample a set of diverse physically possible trajectories and choose the one with the minimum learned cost. Importantly, our cost volume is able to naturally capture multi-modality. We demonstrate the effectiveness of our approach in real-world driving data captured in several cities in North America. Our experiments show that the learned cost volume can generate safer planning than all the baselines.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021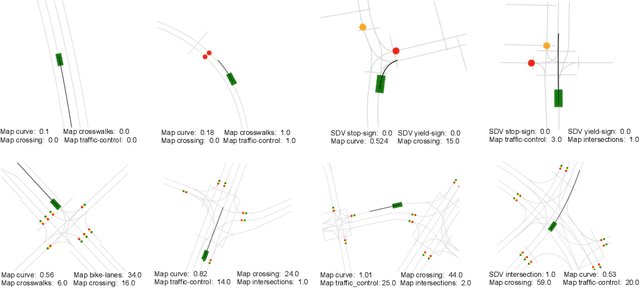
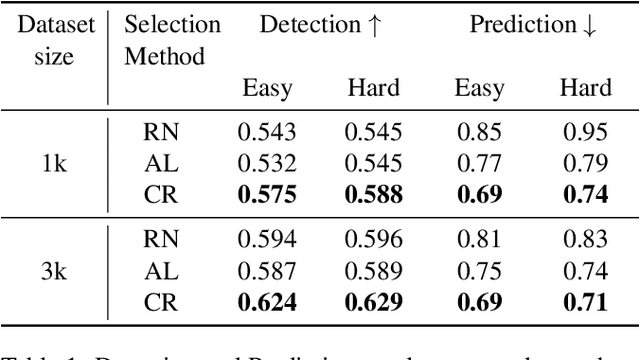

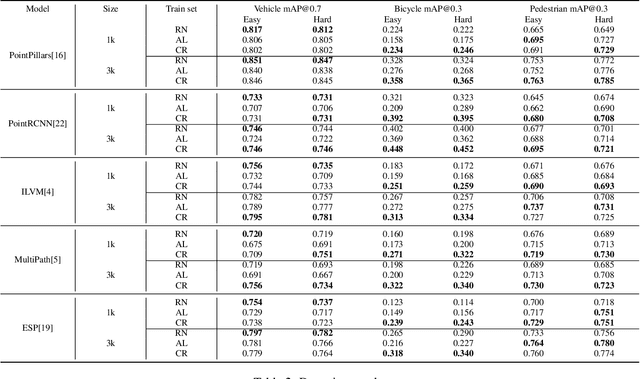
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles
Jan 16, 2021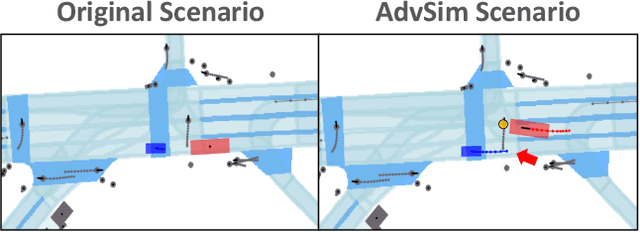
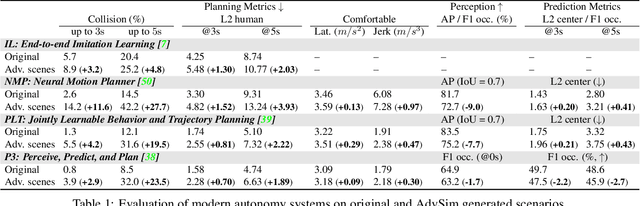

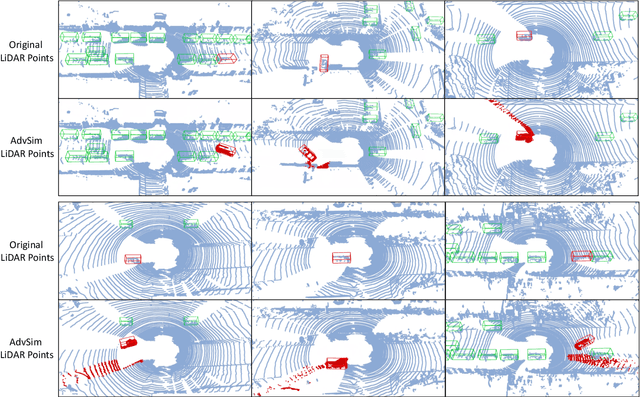
As self-driving systems become better, simulating scenarios where the autonomy stack is likely to fail becomes of key importance. Traditionally, those scenarios are generated for a few scenes with respect to the planning module that takes ground-truth actor states as input. This does not scale and cannot identify all possible autonomy failures, such as perception failures due to occlusion. In this paper, we propose AdvSim, an adversarial framework to generate safety-critical scenarios for any LiDAR-based autonomy system. Given an initial traffic scenario, AdvSim modifies the actors' trajectories in a physically plausible manner and updates the LiDAR sensor data to create realistic observations of the perturbed world. Importantly, by simulating directly from sensor data, we obtain adversarial scenarios that are safety-critical for the full autonomy stack. Our experiments show that our approach is general and can identify thousands of semantically meaningful safety-critical scenarios for a wide range of modern self-driving systems. Furthermore, we show that the robustness and safety of these autonomy systems can be further improved by training them with scenarios generated by AdvSim.
LookOut: Diverse Multi-Future Prediction and Planning for Self-Driving
Jan 16, 2021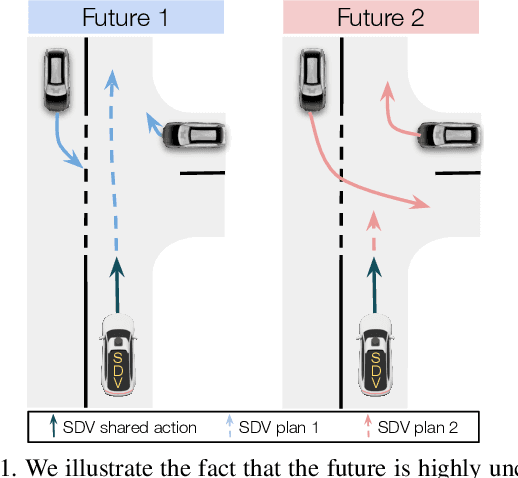
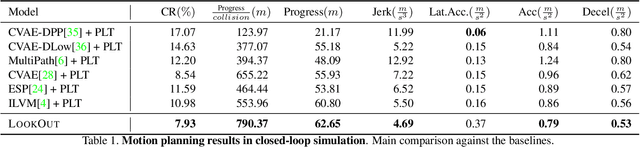

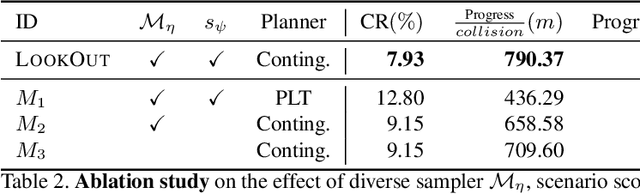
Self-driving vehicles need to anticipate a diverse set of future traffic scenarios in order to safely share the road with other traffic participants that may exhibit rare but dangerous driving. In this paper, we present LookOut, an approach to jointly perceive the environment and predict a diverse set of futures from sensor data, estimate their probability, and optimize a contingency plan over these diverse future realizations. In particular, we learn a diverse joint distribution over multi-agent future trajectories in a traffic scene that allows us to cover a wide range of future modes with high sample efficiency while leveraging the expressive power of generative models. Unlike previous work in diverse motion forecasting, our diversity objective explicitly rewards sampling future scenarios that require distinct reactions from the self-driving vehicle for improved safety. Our contingency planner then finds comfortable trajectories that ensure safe reactions to a wide range of future scenarios. Through extensive evaluations, we show that our model demonstrates significantly more diverse and sample-efficient motion forecasting in a large-scale self-driving dataset as well as safer and more comfortable motion plans in long-term closed-loop simulations than current state-of-the-art models.
Universal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
Nov 12, 2020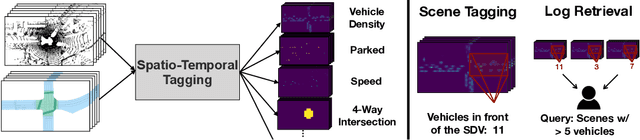
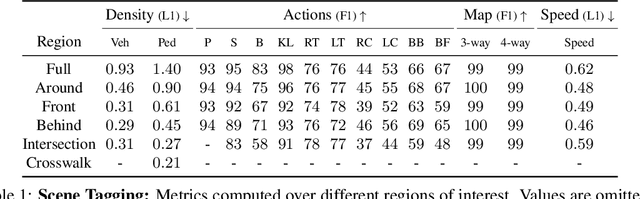
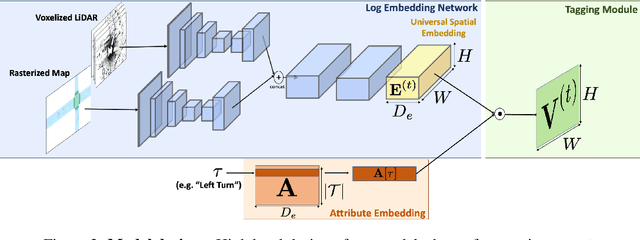

In this paper, we tackle the problem of spatio-temporal tagging of self-driving scenes from raw sensor data. Our approach learns a universal embedding for all tags, enabling efficient tagging of many attributes and faster learning of new attributes with limited data. Importantly, the embedding is spatio-temporally aware, allowing the model to naturally output spatio-temporal tag values. Values can then be pooled over arbitrary regions, in order to, for example, compute the pedestrian density in front of the SDV, or determine if a car is blocking another car at a 4-way intersection. We demonstrate the effectiveness of our approach on a new large scale self-driving dataset, SDVScenes, containing 15 attributes relating to vehicle and pedestrian density, the actions of each actor, the speed of each actor, interactions between actors, and the topology of the road map.
Testing the Safety of Self-driving Vehicles by Simulating Perception and Prediction
Aug 13, 2020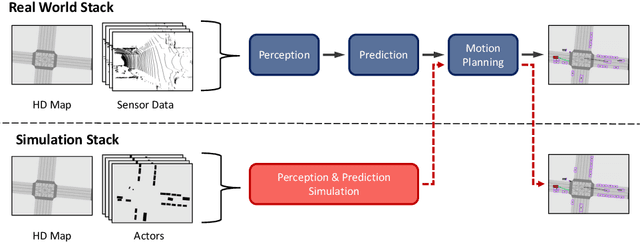
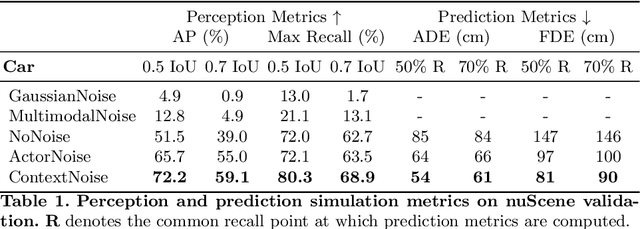
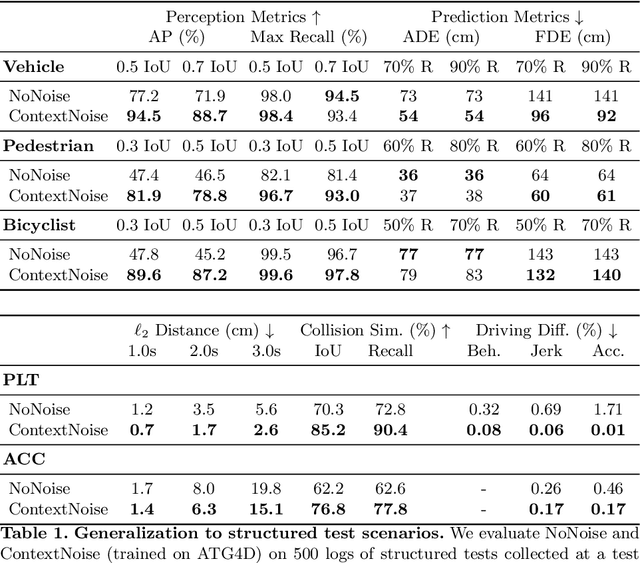
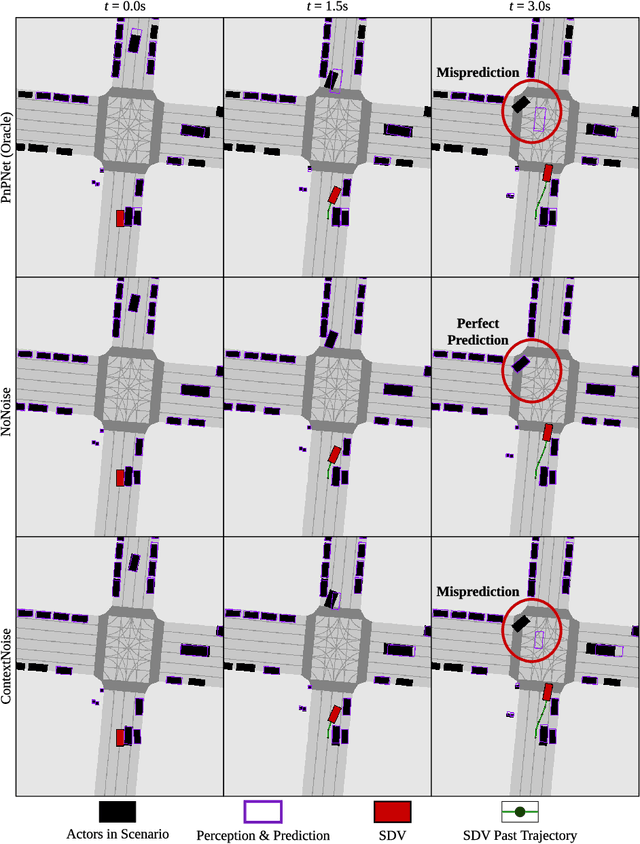
We present a novel method for testing the safety of self-driving vehicles in simulation. We propose an alternative to sensor simulation, as sensor simulation is expensive and has large domain gaps. Instead, we directly simulate the outputs of the self-driving vehicle's perception and prediction system, enabling realistic motion planning testing. Specifically, we use paired data in the form of ground truth labels and real perception and prediction outputs to train a model that predicts what the online system will produce. Importantly, the inputs to our system consists of high definition maps, bounding boxes, and trajectories, which can be easily sketched by a test engineer in a matter of minutes. This makes our approach a much more scalable solution. Quantitative results on two large-scale datasets demonstrate that we can realistically test motion planning using our simulations.
Perceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations
Aug 13, 2020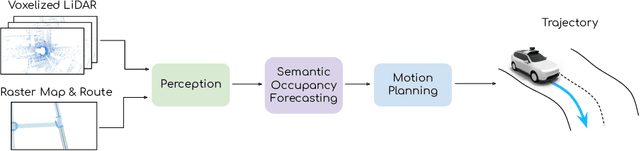
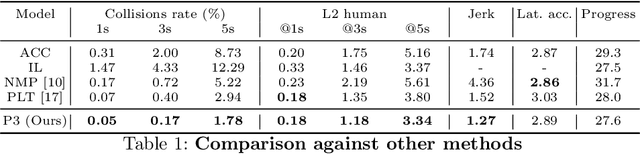
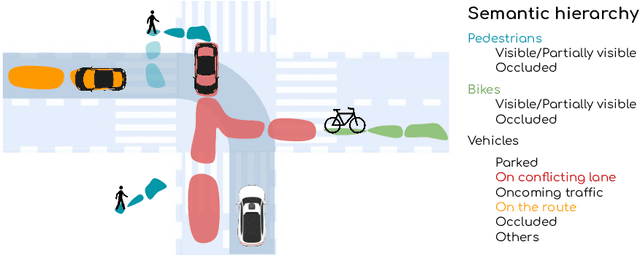
In this paper we propose a novel end-to-end learnable network that performs joint perception, prediction and motion planning for self-driving vehicles and produces interpretable intermediate representations. Unlike existing neural motion planners, our motion planning costs are consistent with our perception and prediction estimates. This is achieved by a novel differentiable semantic occupancy representation that is explicitly used as cost by the motion planning process. Our network is learned end-to-end from human demonstrations. The experiments in a large-scale manual-driving dataset and closed-loop simulation show that the proposed model significantly outperforms state-of-the-art planners in imitating the human behaviors while producing much safer trajectories.