 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Saliency Guided Image Enhancement
Jun 09, 2023



Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
Universal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
Nov 12, 2020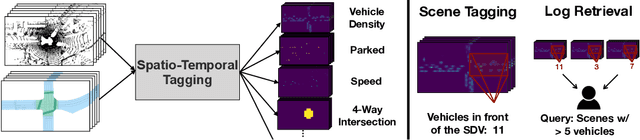
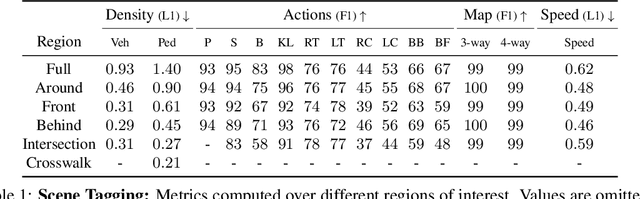
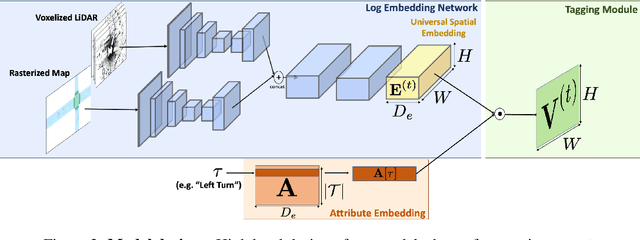

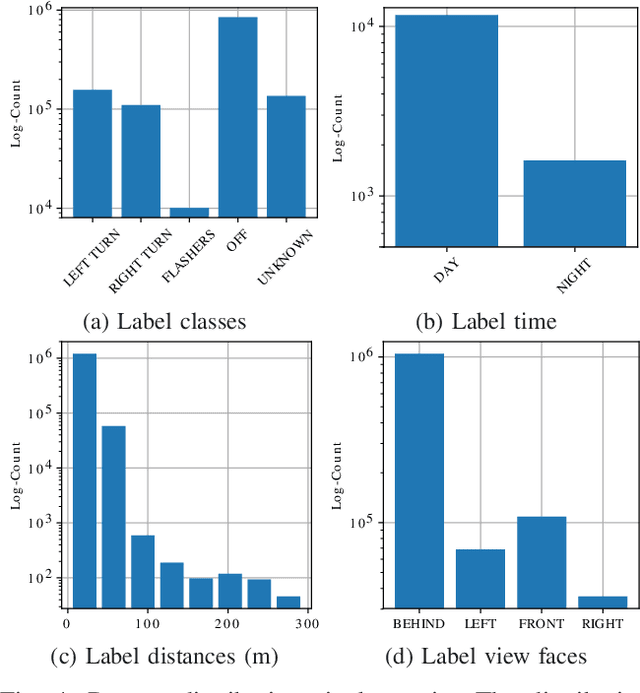
In this paper, we tackle the problem of spatio-temporal tagging of self-driving scenes from raw sensor data. Our approach learns a universal embedding for all tags, enabling efficient tagging of many attributes and faster learning of new attributes with limited data. Importantly, the embedding is spatio-temporally aware, allowing the model to naturally output spatio-temporal tag values. Values can then be pooled over arbitrary regions, in order to, for example, compute the pedestrian density in front of the SDV, or determine if a car is blocking another car at a 4-way intersection. We demonstrate the effectiveness of our approach on a new large scale self-driving dataset, SDVScenes, containing 15 attributes relating to vehicle and pedestrian density, the actions of each actor, the speed of each actor, interactions between actors, and the topology of the road map.
DeepSignals: Predicting Intent of Drivers Through Visual Signals
May 03, 2019

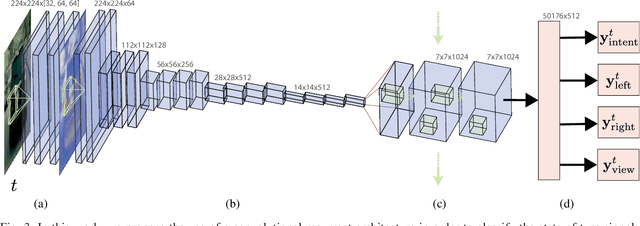
Detecting the intention of drivers is an essential task in self-driving, necessary to anticipate sudden events like lane changes and stops. Turn signals and emergency flashers communicate such intentions, providing seconds of potentially critical reaction time. In this paper, we propose to detect these signals in video sequences by using a deep neural network that reasons about both spatial and temporal information. Our experiments on more than a million frames show high per-frame accuracy in very challenging scenarios.
LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
Mar 20, 2019

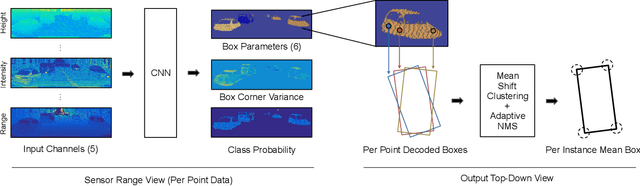
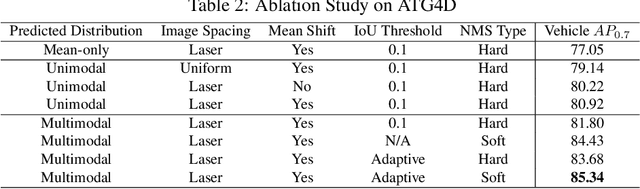
In this paper, we present LaserNet, a computationally efficient method for 3D object detection from LiDAR data for autonomous driving. The efficiency results from processing LiDAR data in the native range view of the sensor, where the input data is naturally compact. Operating in the range view involves well known challenges for learning, including occlusion and scale variation, but it also provides contextual information based on how the sensor data was captured. Our approach uses a fully convolutional network to predict a multimodal distribution over 3D boxes for each point and then it efficiently fuses these distributions to generate a prediction for each object. Experiments show that modeling each detection as a distribution rather than a single deterministic box leads to better overall detection performance. Benchmark results show that this approach has significantly lower runtime than other recent detectors and that it achieves state-of-the-art performance when compared on a large dataset that has enough data to overcome the challenges of training on the range view.
Uniform Transformation of Non-Separable Probability Distributions
Aug 16, 2016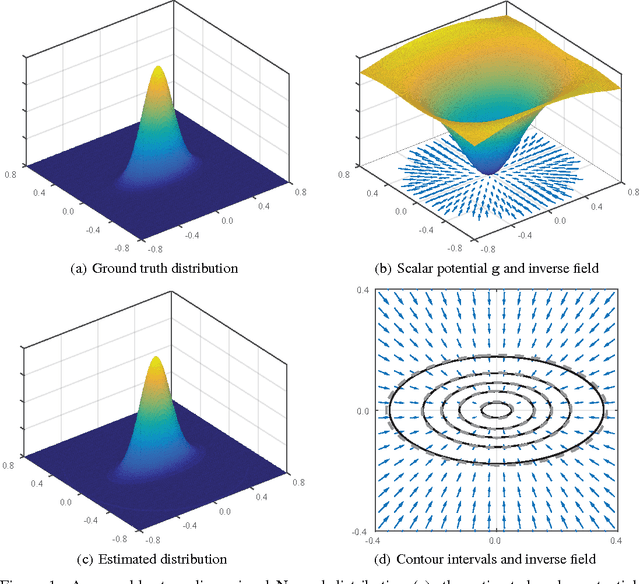
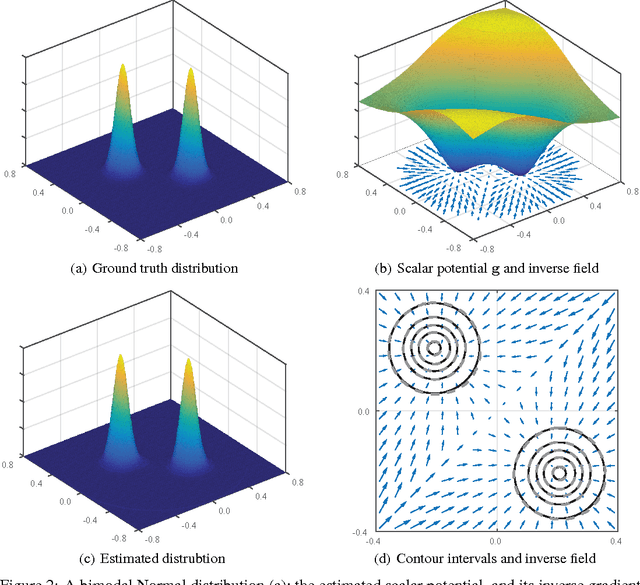
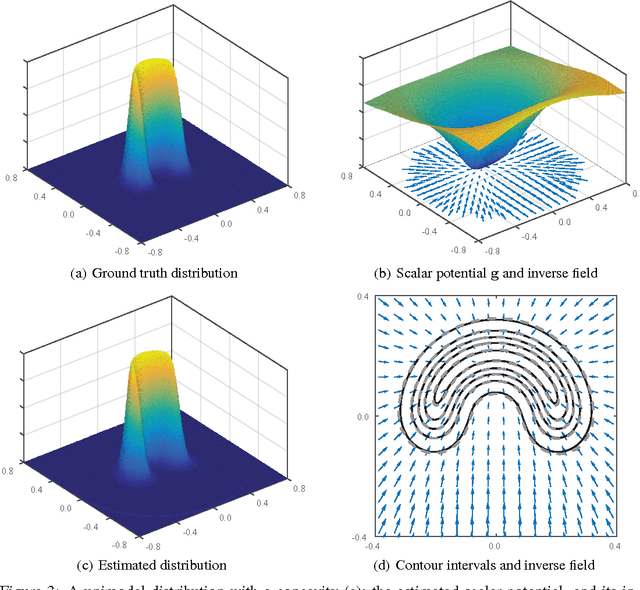

A theoretical framework is developed to describe the transformation that distributes probability density functions uniformly over space. In one dimension, the cumulative distribution can be used, but does not generalize to higher dimensions, or non-separable distributions. A potential function is shown to link probability density functions to their transformation, and to generalize the cumulative. A numerical method is developed to compute the potential, and examples are shown in two dimensions.