 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabelFormer: Object Trajectory Refinement for Offboard Perception from LiDAR Point Clouds
Nov 02, 2023



A major bottleneck to scaling-up training of self-driving perception systems are the human annotations required for supervision. A promising alternative is to leverage "auto-labelling" offboard perception models that are trained to automatically generate annotations from raw LiDAR point clouds at a fraction of the cost. Auto-labels are most commonly generated via a two-stage approach -- first objects are detected and tracked over time, and then each object trajectory is passed to a learned refinement model to improve accuracy. Since existing refinement models are overly complex and lack advanced temporal reasoning capabilities, in this work we propose LabelFormer, a simple, efficient, and effective trajectory-level refinement approach. Our approach first encodes each frame's observations separately, then exploits self-attention to reason about the trajectory with full temporal context, and finally decodes the refined object size and per-frame poses. Evaluation on both urban and highway datasets demonstrates that LabelFormer outperforms existing works by a large margin. Finally, we show that training on a dataset augmented with auto-labels generated by our method leads to improved downstream detection performance compared to existing methods. Please visit the project website for details https://waabi.ai/labelformer
* 20 pages, 8 figures, 7 tables
Just Label What You Need: Fine-Grained Active Selection for Perception and Prediction through Partially Labeled Scenes
Apr 08, 2021
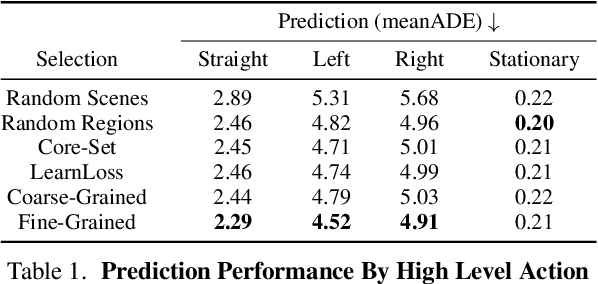
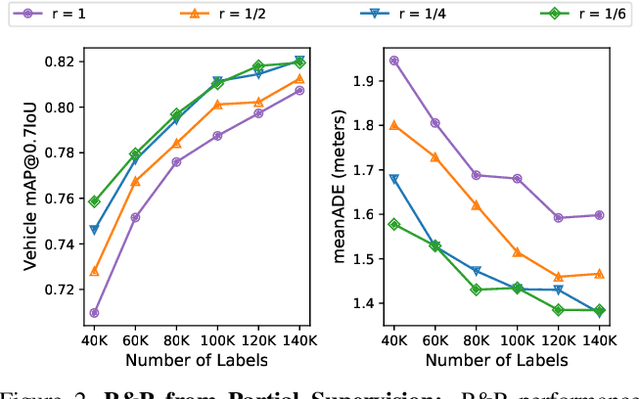
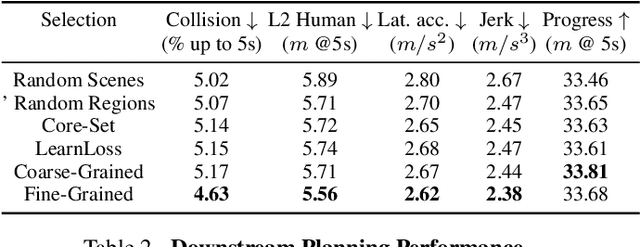
Self-driving vehicles must perceive and predict the future positions of nearby actors in order to avoid collisions and drive safely. A learned deep learning module is often responsible for this task, requiring large-scale, high-quality training datasets. As data collection is often significantly cheaper than labeling in this domain, the decision of which subset of examples to label can have a profound impact on model performance. Active learning techniques, which leverage the state of the current model to iteratively select examples for labeling, offer a promising solution to this problem. However, despite the appeal of this approach, there has been little scientific analysis of active learning approaches for the perception and prediction (P&P) problem. In this work, we study active learning techniques for P&P and find that the traditional active learning formulation is ill-suited for the P&P setting. We thus introduce generalizations that ensure that our approach is both cost-aware and allows for fine-grained selection of examples through partially labeled scenes. Our experiments on a real-world, large-scale self-driving dataset suggest that fine-grained selection can improve the performance across perception, prediction, and downstream planning tasks.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021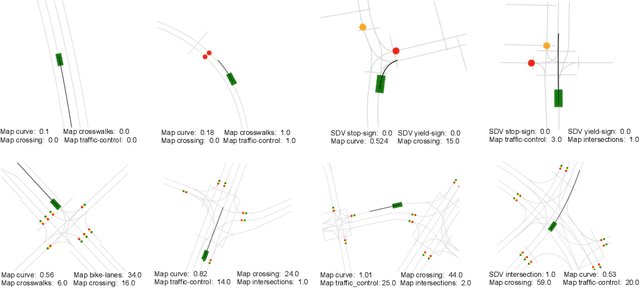
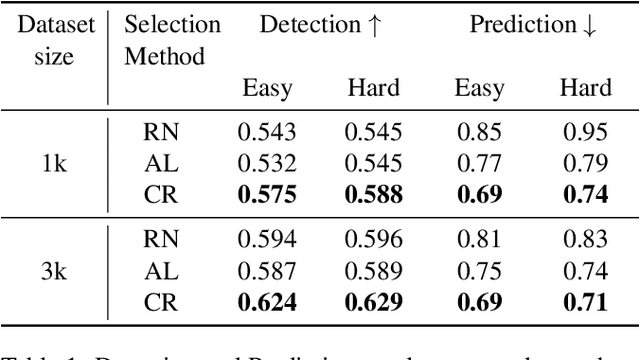

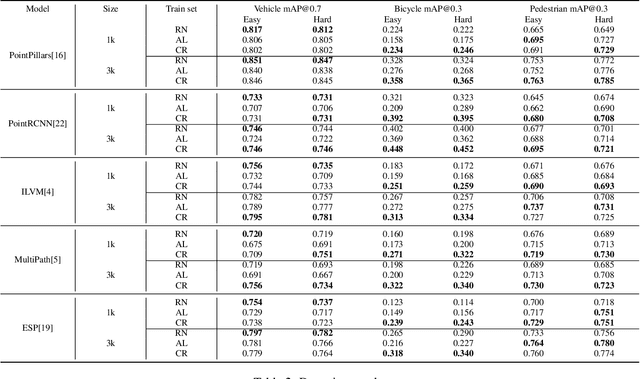
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
Universal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
Nov 12, 2020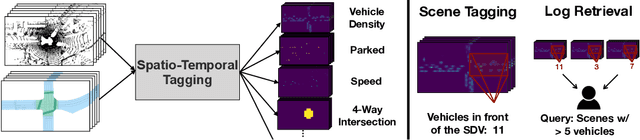
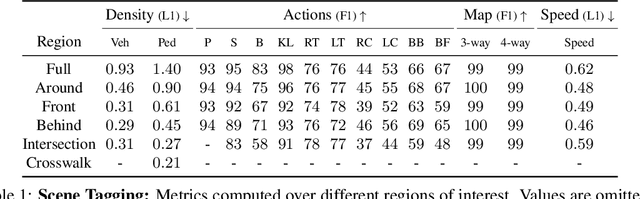
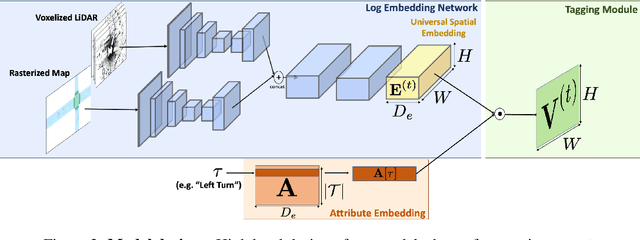

In this paper, we tackle the problem of spatio-temporal tagging of self-driving scenes from raw sensor data. Our approach learns a universal embedding for all tags, enabling efficient tagging of many attributes and faster learning of new attributes with limited data. Importantly, the embedding is spatio-temporally aware, allowing the model to naturally output spatio-temporal tag values. Values can then be pooled over arbitrary regions, in order to, for example, compute the pedestrian density in front of the SDV, or determine if a car is blocking another car at a 4-way intersection. We demonstrate the effectiveness of our approach on a new large scale self-driving dataset, SDVScenes, containing 15 attributes relating to vehicle and pedestrian density, the actions of each actor, the speed of each actor, interactions between actors, and the topology of the road map.
End-to-end Contextual Perception and Prediction with Interaction Transformer
Aug 13, 2020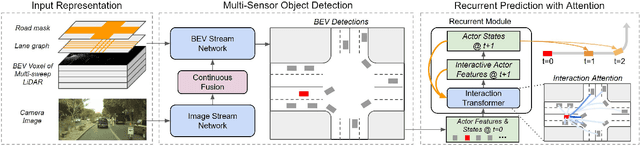
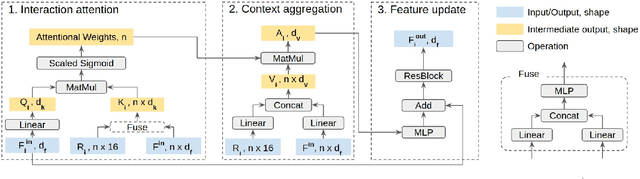
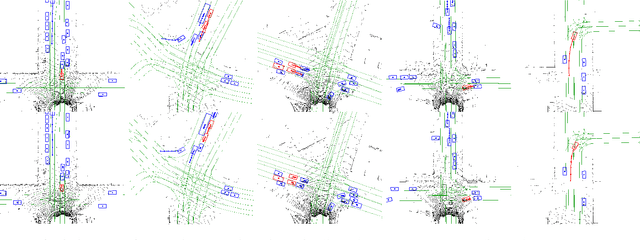
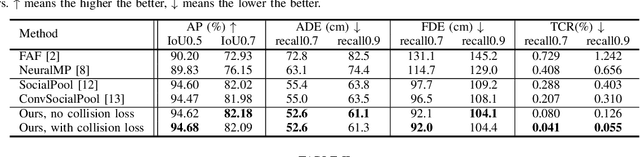
In this paper, we tackle the problem of detecting objects in 3D and forecasting their future motion in the context of self-driving. Towards this goal, we design a novel approach that explicitly takes into account the interactions between actors. To capture their spatial-temporal dependencies, we propose a recurrent neural network with a novel Transformer architecture, which we call the Interaction Transformer. Importantly, our model can be trained end-to-end, and runs in real-time. We validate our approach on two challenging real-world datasets: ATG4D and nuScenes. We show that our approach can outperform the state-of-the-art on both datasets. In particular, we significantly improve the social compliance between the estimated future trajectories, resulting in far fewer collisions between the predicted actors.
Discrete Residual Flow for Probabilistic Pedestrian Behavior Prediction
Oct 17, 2019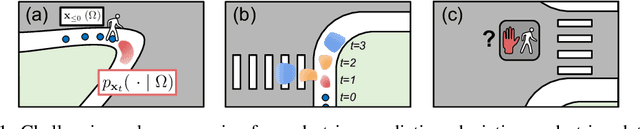
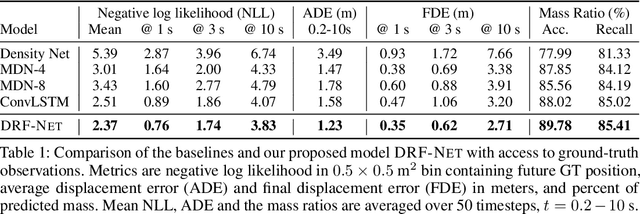
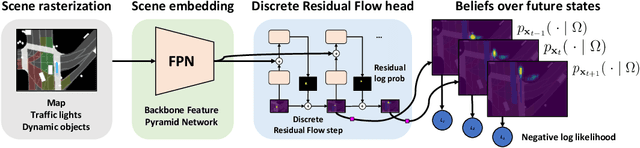
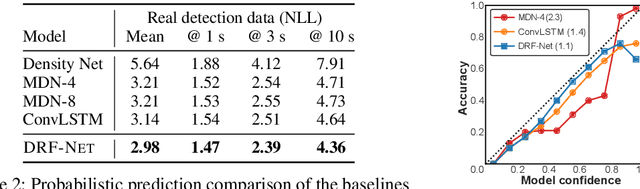
Self-driving vehicles plan around both static and dynamic objects, applying predictive models of behavior to estimate future locations of the objects in the environment. However, future behavior is inherently uncertain, and models of motion that produce deterministic outputs are limited to short timescales. Particularly difficult is the prediction of human behavior. In this work, we propose the discrete residual flow network (DRF-Net), a convolutional neural network for human motion prediction that captures the uncertainty inherent in long-range motion forecasting. In particular, our learned network effectively captures multimodal posteriors over future human motion by predicting and updating a discretized distribution over spatial locations. We compare our model against several strong competitors and show that our model outperforms all baselines.