 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajLoom: Dense Future Trajectory Generation from Video
Mar 23, 2026Predicting future motion is crucial in video understanding and controllable video generation. Dense point trajectories are a compact, expressive motion representation, but modeling their future evolution from observed video remains challenging. We propose a framework that predicts future trajectories and visibility from past trajectories and video context. Our method has three components: (1) Grid-Anchor Offset Encoding, which reduces location-dependent bias by representing each point as an offset from its pixel-center anchor; (2) TrajLoom-VAE, which learns a compact spatiotemporal latent space for dense trajectories with masked reconstruction and a spatiotemporal consistency regularizer; and (3) TrajLoom-Flow, which generates future trajectories in latent space via flow matching, with boundary cues and on-policy K-step fine-tuning for stable sampling. We also introduce TrajLoomBench, a unified benchmark spanning real and synthetic videos with a standardized setup aligned with video-generation benchmarks. Compared with state-of-the-art methods, our approach extends the prediction horizon from 24 to 81 frames while improving motion realism and stability across datasets. The predicted trajectories directly support downstream video generation and editing. Code, model checkpoints, and datasets are available at https://trajloom.github.io/.
EGSS: Entropy-guided Stepwise Scaling for Reliable Software Engineering
Feb 05, 2026Agentic Test-Time Scaling (TTS) has delivered state-of-the-art (SOTA) performance on complex software engineering tasks such as code generation and bug fixing. However, its practical adoption remains limited due to significant computational overhead, primarily driven by two key challenges: (1) the high cost associated with deploying excessively large ensembles, and (2) the lack of a reliable mechanism for selecting the optimal candidate solution, ultimately constraining the performance gains that can be realized. To address these challenges, we propose Entropy-Guided Stepwise Scaling (EGSS), a novel TTS framework that dynamically balances efficiency and effectiveness through entropy-guided adaptive search and robust test-suite augmentation. Extensive experiments on SWE-Bench-Verified demonstrate that EGSS consistently boosts performance by 5-10% across all evaluated models. Specifically, it increases the resolved ratio of Kimi-K2-Intruct from 63.2% to 72.2%, and GLM-4.6 from 65.8% to 74.6%. Furthermore, when paired with GLM-4.6, EGSS achieves a new state-of-the-art among open-source large language models. In addition to these accuracy improvements, EGSS reduces inference-time token usage by over 28% compared to existing TTS methods, achieving simultaneous gains in both effectiveness and computational efficiency.
Learning Adaptive Parallel Execution for Efficient Code Localization
Jan 27, 2026Code localization constitutes a key bottleneck in automated software development pipelines. While concurrent tool execution can enhance discovery speed, current agents demonstrate a 34.9\% redundant invocation rate, which negates parallelism benefits. We propose \textbf{FuseSearch}, reformulating parallel code localization as a \textbf{joint quality-efficiency optimization} task. Through defining \textbf{tool efficiency} -- the ratio of unique information gain to invocation count -- we utilize a two-phase SFT and RL training approach for learning adaptive parallel strategies. Different from fixed-breadth approaches, FuseSearch dynamically modulates search breadth according to task context, evolving from exploration phases to refinement stages. Evaluated on SWE-bench Verified, FuseSearch-4B achieves SOTA-level performance (84.7\% file-level and 56.4\% function-level $F_1$ scores) with 93.6\% speedup, utilizing 67.7\% fewer turns and 68.9\% fewer tokens. Results indicate that efficiency-aware training naturally improves quality through eliminating noisy redundant signals, enabling high-performance cost-effective localization agents.
Enhancing Project-Specific Code Completion by Inferring Internal API Information
Jul 28, 2025Project-specific code completion is a critical task that leverages context from a project to generate accurate code. State-of-the-art methods use retrieval-augmented generation (RAG) with large language models (LLMs) and project information for code completion. However, they often struggle to incorporate internal API information, which is crucial for accuracy, especially when APIs are not explicitly imported in the file. To address this, we propose a method to infer internal API information without relying on imports. Our method extends the representation of APIs by constructing usage examples and semantic descriptions, building a knowledge base for LLMs to generate relevant completions. We also introduce ProjBench, a benchmark that avoids leaked imports and consists of large-scale real-world projects. Experiments on ProjBench and CrossCodeEval show that our approach significantly outperforms existing methods, improving code exact match by 22.72% and identifier exact match by 18.31%. Additionally, integrating our method with existing baselines boosts code match by 47.80% and identifier match by 35.55%.
REPOFUSE: Repository-Level Code Completion with Fused Dual Context
Feb 23, 2024


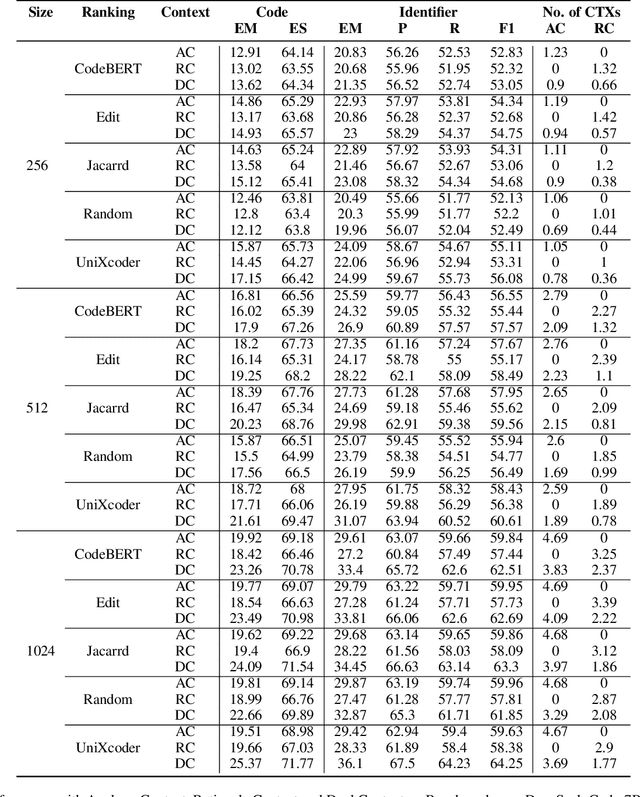
The success of language models in code assistance has spurred the proposal of repository-level code completion as a means to enhance prediction accuracy, utilizing the context from the entire codebase. However, this amplified context can inadvertently increase inference latency, potentially undermining the developer experience and deterring tool adoption - a challenge we termed the Context-Latency Conundrum. This paper introduces REPOFUSE, a pioneering solution designed to enhance repository-level code completion without the latency trade-off. REPOFUSE uniquely fuses two types of context: the analogy context, rooted in code analogies, and the rationale context, which encompasses in-depth semantic relationships. We propose a novel rank truncated generation (RTG) technique that efficiently condenses these contexts into prompts with restricted size. This enables REPOFUSE to deliver precise code completions while maintaining inference efficiency. Through testing with the CrossCodeEval suite, REPOFUSE has demonstrated a significant leap over existing models, achieving a 40.90% to 59.75% increase in exact match (EM) accuracy for code completions and a 26.8% enhancement in inference speed. Beyond experimental validation, REPOFUSE has been integrated into the workflow of a large enterprise, where it actively supports various coding tasks.
MFTCoder: Boosting Code LLMs with Multitask Fine-Tuning
Nov 04, 2023Code LLMs have emerged as a specialized research field, with remarkable studies dedicated to enhancing model's coding capabilities through fine-tuning on pre-trained models. Previous fine-tuning approaches were typically tailored to specific downstream tasks or scenarios, which meant separate fine-tuning for each task, requiring extensive training resources and posing challenges in terms of deployment and maintenance. Furthermore, these approaches failed to leverage the inherent interconnectedness among different code-related tasks. To overcome these limitations, we present a multi-task fine-tuning framework, MFTcoder, that enables simultaneous and parallel fine-tuning on multiple tasks. By incorporating various loss functions, we effectively address common challenges in multi-task learning, such as data imbalance, varying difficulty levels, and inconsistent convergence speeds. Extensive experiments have conclusively demonstrated that our multi-task fine-tuning approach outperforms both individual fine-tuning on single tasks and fine-tuning on a mixed ensemble of tasks. Moreover, MFTcoder offers efficient training capabilities, including efficient data tokenization modes and PEFT fine-tuning, resulting in significantly improved speed compared to traditional fine-tuning methods. MFTcoder seamlessly integrates with several mainstream open-source LLMs, such as CodeLLama and Qwen. Leveraging the CodeLLama foundation, our MFTcoder fine-tuned model, \textsc{CodeFuse-CodeLLama-34B}, achieves an impressive pass@1 score of 74.4\% on the HumaneEval benchmark, surpassing GPT-4 performance (67\%, zero-shot). MFTCoder is open-sourced at \url{https://github.com/codefuse-ai/MFTCOder}
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
Exploring Adversarial Robustness of Multi-Sensor Perception Systems in Self Driving
Jan 26, 2021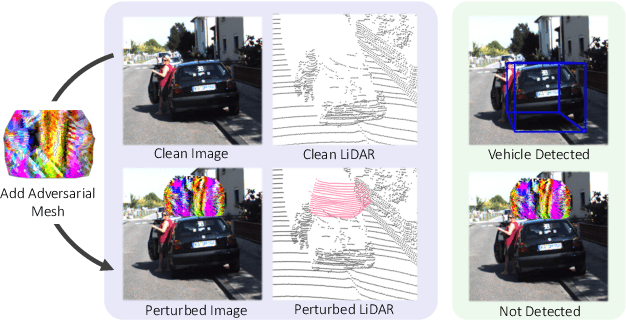
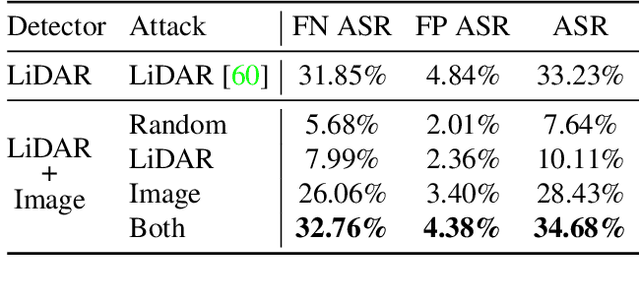
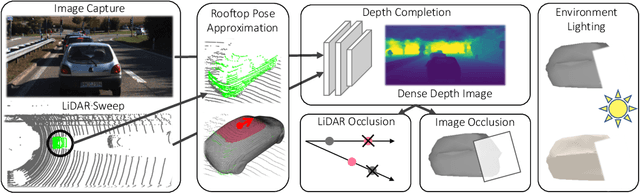
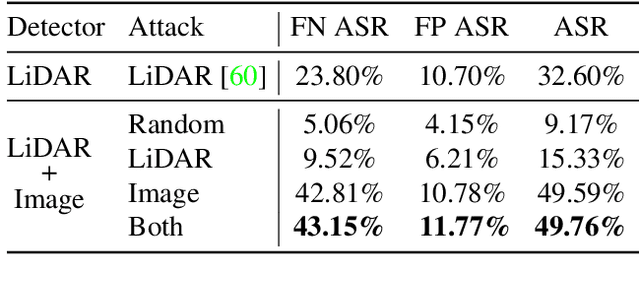
Modern self-driving perception systems have been shown to improve upon processing complementary inputs such as LiDAR with images. In isolation, 2D images have been found to be extremely vulnerable to adversarial attacks. Yet, there have been limited studies on the adversarial robustness of multi-modal models that fuse LiDAR features with image features. Furthermore, existing works do not consider physically realizable perturbations that are consistent across the input modalities. In this paper, we showcase practical susceptibilities of multi-sensor detection by placing an adversarial object on top of a host vehicle. We focus on physically realizable and input-agnostic attacks as they are feasible to execute in practice, and show that a single universal adversary can hide different host vehicles from state-of-the-art multi-modal detectors. Our experiments demonstrate that successful attacks are primarily caused by easily corrupted image features. Furthermore, we find that in modern sensor fusion methods which project image features into 3D, adversarial attacks can exploit the projection process to generate false positives across distant regions in 3D. Towards more robust multi-modal perception systems, we show that adversarial training with feature denoising can boost robustness to such attacks significantly. However, we find that standard adversarial defenses still struggle to prevent false positives which are also caused by inaccurate associations between 3D LiDAR points and 2D pixels.
A multi-perspective combined recall and rank framework for Chinese procedure terminology normalization
Jan 22, 2021


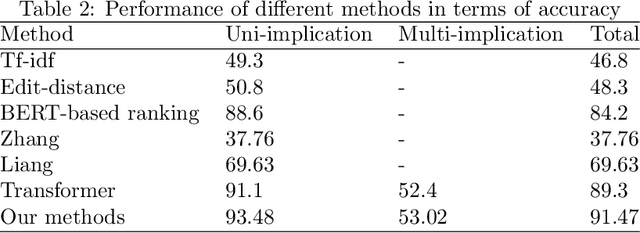
Medical terminology normalization aims to map the clinical mention to terminologies come from a knowledge base, which plays an important role in analyzing Electronic Health Record(EHR) and many downstream tasks. In this paper, we focus on Chinese procedure terminology normalization. The expression of terminologies are various and one medical mention may be linked to multiple terminologies. Previous study explores some methods such as multi-class classification or learning to rank(LTR) to sort the terminologies by literature and semantic information. However, these information is inadequate to find the right terminologies, particularly in multi-implication cases. In this work, we propose a combined recall and rank framework to solve the above problems. This framework is composed of a multi-task candidate generator(MTCG), a keywords attentive ranker(KAR) and a fusion block(FB). MTCG is utilized to predict the mention implication number and recall candidates with semantic similarity. KAR is based on Bert with a keywords attentive mechanism which focuses on keywords such as procedure sites and procedure types. FB merges the similarity come from MTCG and KAR to sort the terminologies from different perspectives. Detailed experimental analysis shows our proposed framework has a remarkable improvement on both performance and efficiency.
LaneRCNN: Distributed Representations for Graph-Centric Motion Forecasting
Jan 17, 2021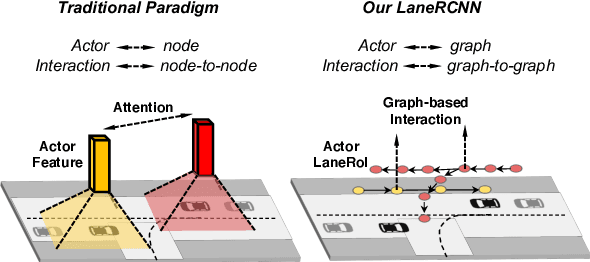
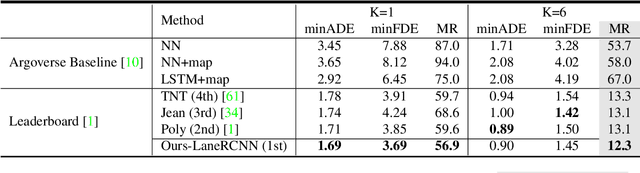
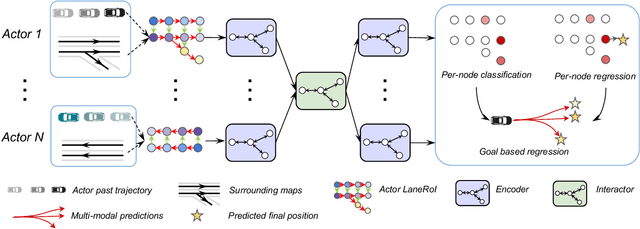
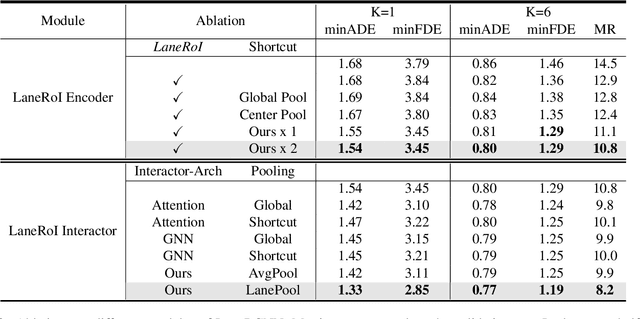
Forecasting the future behaviors of dynamic actors is an important task in many robotics applications such as self-driving. It is extremely challenging as actors have latent intentions and their trajectories are governed by complex interactions between the other actors, themselves, and the maps. In this paper, we propose LaneRCNN, a graph-centric motion forecasting model. Importantly, relying on a specially designed graph encoder, we learn a local lane graph representation per actor (LaneRoI) to encode its past motions and the local map topology. We further develop an interaction module which permits efficient message passing among local graph representations within a shared global lane graph. Moreover, we parameterize the output trajectories based on lane graphs, a more amenable prediction parameterization. Our LaneRCNN captures the actor-to-actor and the actor-to-map relations in a distributed and map-aware manner. We demonstrate the effectiveness of our approach on the large-scale Argoverse Motion Forecasting Benchmark. We achieve the 1st place on the leaderboard and significantly outperform previous best results.