 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADA: Robust and Accurate Feature Learning with Domain Adaptation
Jul 22, 2024Recent advancements in keypoint detection and descriptor extraction have shown impressive performance in local feature learning tasks. However, existing methods generally exhibit suboptimal performance under extreme conditions such as significant appearance changes and domain shifts. In this study, we introduce a multi-level feature aggregation network that incorporates two pivotal components to facilitate the learning of robust and accurate features with domain adaptation. First, we employ domain adaptation supervision to align high-level feature distributions across different domains to achieve invariant domain representations. Second, we propose a Transformer-based booster that enhances descriptor robustness by integrating visual and geometric information through wave position encoding concepts, effectively handling complex conditions. To ensure the accuracy and robustness of features, we adopt a hierarchical architecture to capture comprehensive information and apply meticulous targeted supervision to keypoint detection, descriptor extraction, and their coupled processing. Extensive experiments demonstrate that our method, RADA, achieves excellent results in image matching, camera pose estimation, and visual localization tasks.
REPOFUSE: Repository-Level Code Completion with Fused Dual Context
Feb 23, 2024


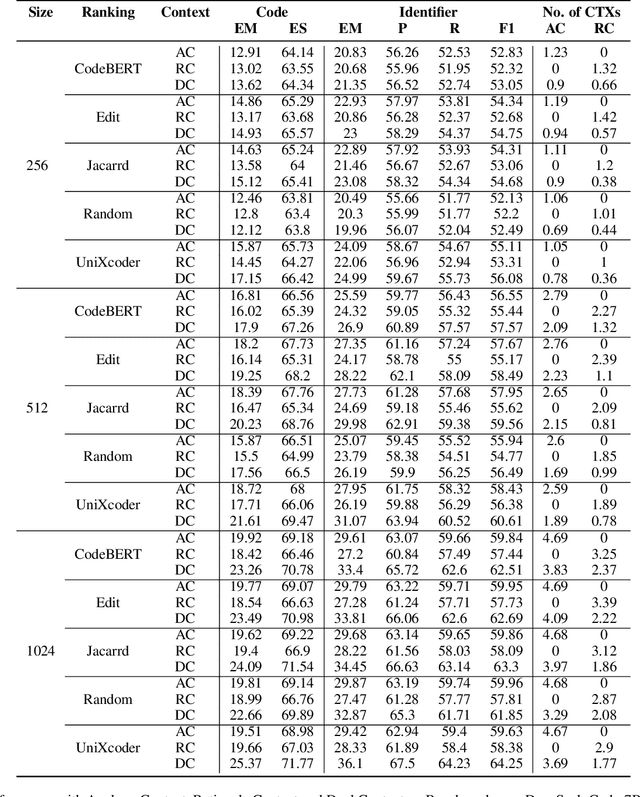
The success of language models in code assistance has spurred the proposal of repository-level code completion as a means to enhance prediction accuracy, utilizing the context from the entire codebase. However, this amplified context can inadvertently increase inference latency, potentially undermining the developer experience and deterring tool adoption - a challenge we termed the Context-Latency Conundrum. This paper introduces REPOFUSE, a pioneering solution designed to enhance repository-level code completion without the latency trade-off. REPOFUSE uniquely fuses two types of context: the analogy context, rooted in code analogies, and the rationale context, which encompasses in-depth semantic relationships. We propose a novel rank truncated generation (RTG) technique that efficiently condenses these contexts into prompts with restricted size. This enables REPOFUSE to deliver precise code completions while maintaining inference efficiency. Through testing with the CrossCodeEval suite, REPOFUSE has demonstrated a significant leap over existing models, achieving a 40.90% to 59.75% increase in exact match (EM) accuracy for code completions and a 26.8% enhancement in inference speed. Beyond experimental validation, REPOFUSE has been integrated into the workflow of a large enterprise, where it actively supports various coding tasks.
The neural network models with delays for solving absolute value equations
Oct 17, 2023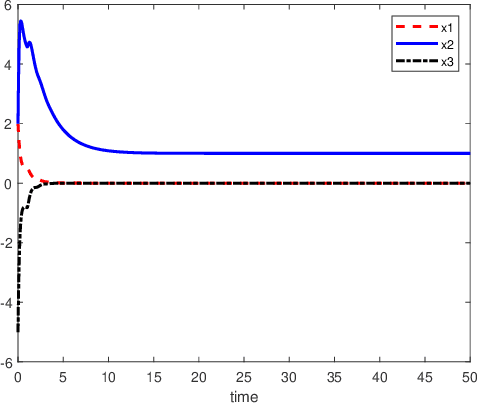
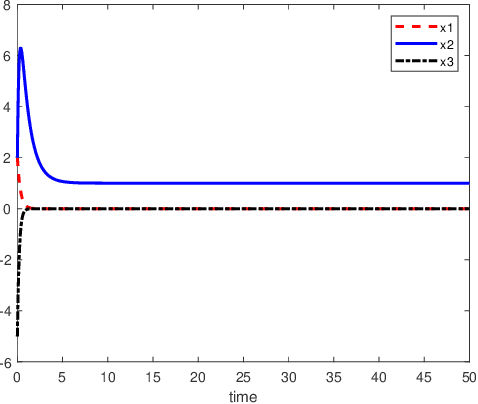
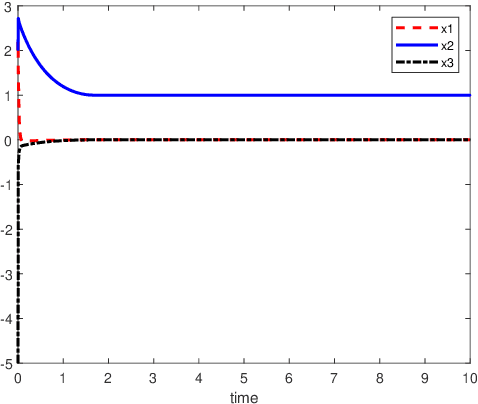
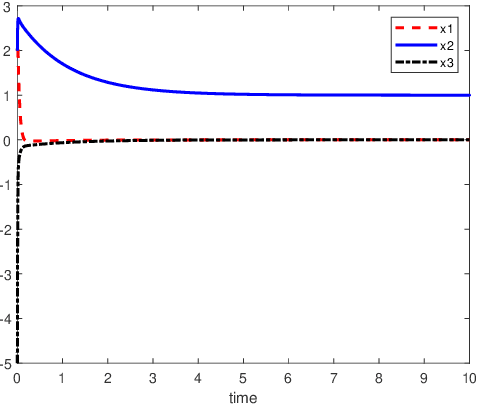
An inverse-free neural network model with mixed delays is proposed for solving the absolute value equation (AVE) $Ax -|x| - b =0$, which includes an inverse-free neural network model with discrete delay as a special case. By using the Lyapunov-Krasovskii theory and the linear matrix inequality (LMI) method, the developed neural network models are proved to be exponentially convergent to the solution of the AVE. Compared with the existing neural network models for solving the AVE, the proposed models feature the ability of solving a class of AVE with $\|A^{-1}\|>1$. Numerical simulations are given to show the effectiveness of the two delayed neural network models.
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.