 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGI-1: Autoregressive Video Generation at Scale
May 19, 2025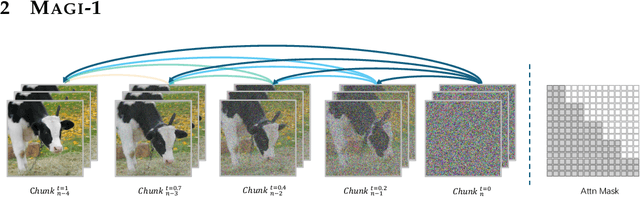
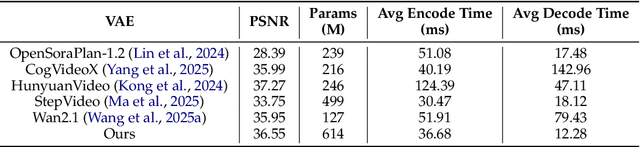
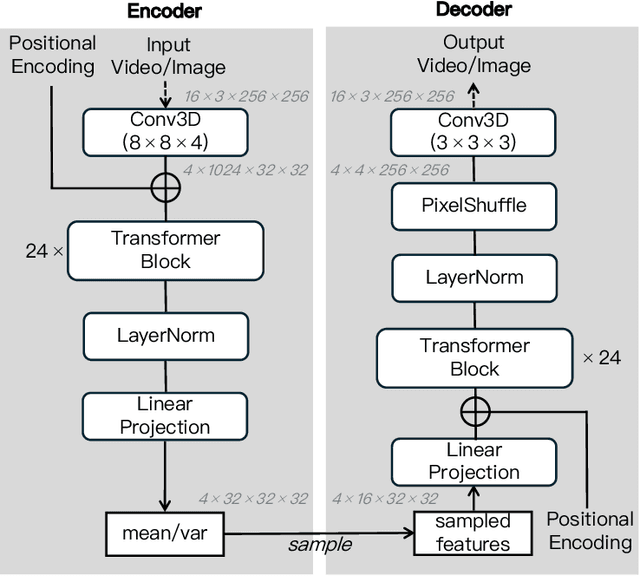
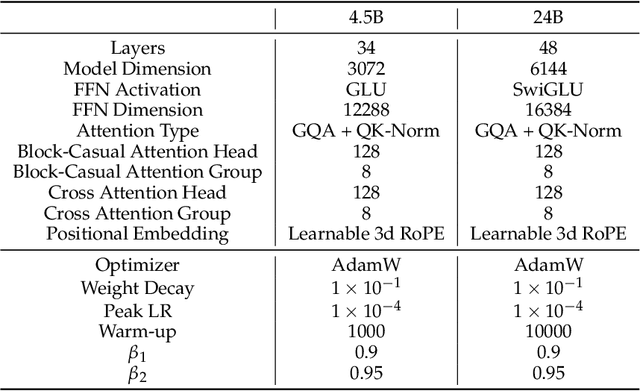
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
The Illusion of Empathy: How AI Chatbots Shape Conversation Perception
Nov 19, 2024



As AI chatbots become more human-like by incorporating empathy, understanding user-centered perceptions of chatbot empathy and its impact on conversation quality remains essential yet under-explored. This study examines how chatbot identity and perceived empathy influence users' overall conversation experience. Analyzing 155 conversations from two datasets, we found that while GPT-based chatbots were rated significantly higher in conversational quality, they were consistently perceived as less empathetic than human conversational partners. Empathy ratings from GPT-4o annotations aligned with users' ratings, reinforcing the perception of lower empathy in chatbots. In contrast, 3 out of 5 empathy models trained on human-human conversations detected no significant differences in empathy language between chatbots and humans. Our findings underscore the critical role of perceived empathy in shaping conversation quality, revealing that achieving high-quality human-AI interactions requires more than simply embedding empathetic language; it necessitates addressing the nuanced ways users interpret and experience empathy in conversations with chatbots.
Attribution Analysis Meets Model Editing: Advancing Knowledge Correction in Vision Language Models with VisEdit
Aug 19, 2024



Model editing aims to correct outdated or erroneous knowledge in large models without costly retraining. Recent research discovered that the mid-layer representation of the subject's final token in a prompt has a strong influence on factual predictions, and developed Large Language Model (LLM) editing techniques based on this observation. However, for Vision-LLMs (VLLMs), how visual representations impact the predictions from a decoder-only language model remains largely unexplored. To the best of our knowledge, model editing for VLLMs has not been extensively studied in the literature. In this work, we employ the contribution allocation and noise perturbation methods to measure the contributions of visual representations for token predictions. Our attribution analysis shows that visual representations in mid-to-later layers that are highly relevant to the prompt contribute significantly to predictions. Based on these insights, we propose VisEdit, a novel model editor for VLLMs that effectively corrects knowledge by editing intermediate visual representations in regions important to the edit prompt. We evaluated VisEdit using multiple VLLM backbones and public VLLM editing benchmark datasets. The results show the superiority of VisEdit over the strong baselines adapted from existing state-of-the-art editors for LLMs.
RADA: Robust and Accurate Feature Learning with Domain Adaptation
Jul 22, 2024Recent advancements in keypoint detection and descriptor extraction have shown impressive performance in local feature learning tasks. However, existing methods generally exhibit suboptimal performance under extreme conditions such as significant appearance changes and domain shifts. In this study, we introduce a multi-level feature aggregation network that incorporates two pivotal components to facilitate the learning of robust and accurate features with domain adaptation. First, we employ domain adaptation supervision to align high-level feature distributions across different domains to achieve invariant domain representations. Second, we propose a Transformer-based booster that enhances descriptor robustness by integrating visual and geometric information through wave position encoding concepts, effectively handling complex conditions. To ensure the accuracy and robustness of features, we adopt a hierarchical architecture to capture comprehensive information and apply meticulous targeted supervision to keypoint detection, descriptor extraction, and their coupled processing. Extensive experiments demonstrate that our method, RADA, achieves excellent results in image matching, camera pose estimation, and visual localization tasks.
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Jun 20, 2024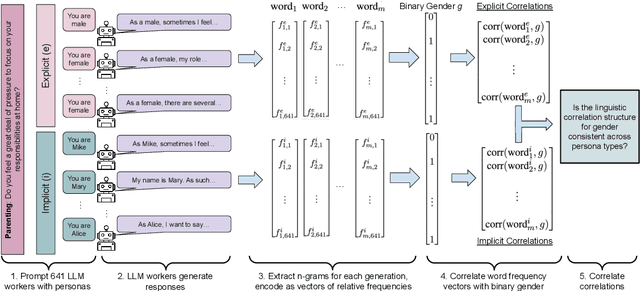



Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
Vernacular? I Barely Know Her: Challenges with Style Control and Stereotyping
Jun 18, 2024



Large Language Models (LLMs) are increasingly being used in educational and learning applications. Research has demonstrated that controlling for style, to fit the needs of the learner, fosters increased understanding, promotes inclusion, and helps with knowledge distillation. To understand the capabilities and limitations of contemporary LLMs in style control, we evaluated five state-of-the-art models: GPT-3.5, GPT-4, GPT-4o, Llama-3, and Mistral-instruct- 7B across two style control tasks. We observed significant inconsistencies in the first task, with model performances averaging between 5th and 8th grade reading levels for tasks intended for first-graders, and standard deviations up to 27.6. For our second task, we observed a statistically significant improvement in performance from 0.02 to 0.26. However, we find that even without stereotypes in reference texts, LLMs often generated culturally insensitive content during their tasks. We provide a thorough analysis and discussion of the results.
Performance Analysis of Uplink/Downlink Decoupled Access in Cellular-V2X Networks
May 10, 2024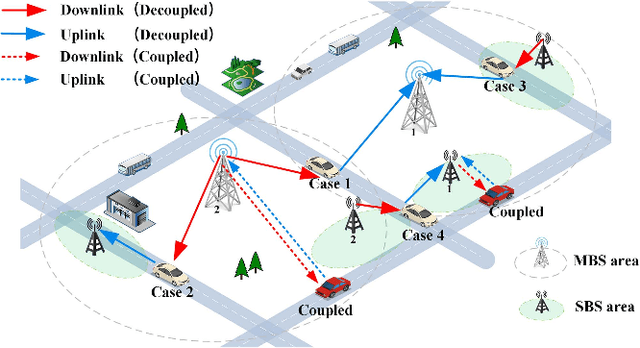
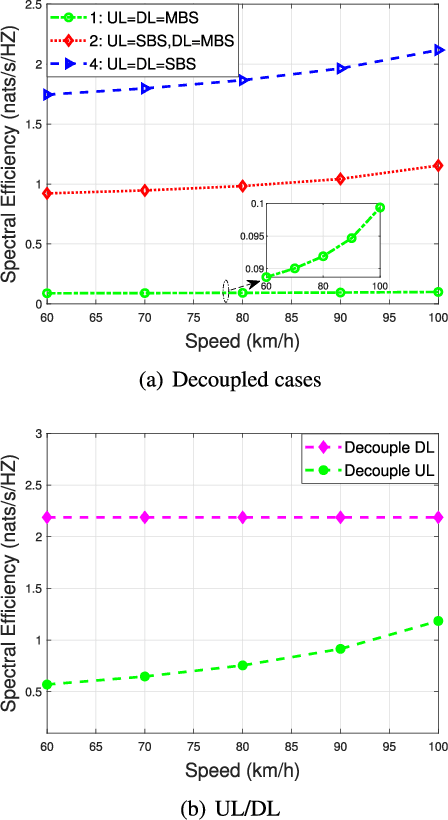
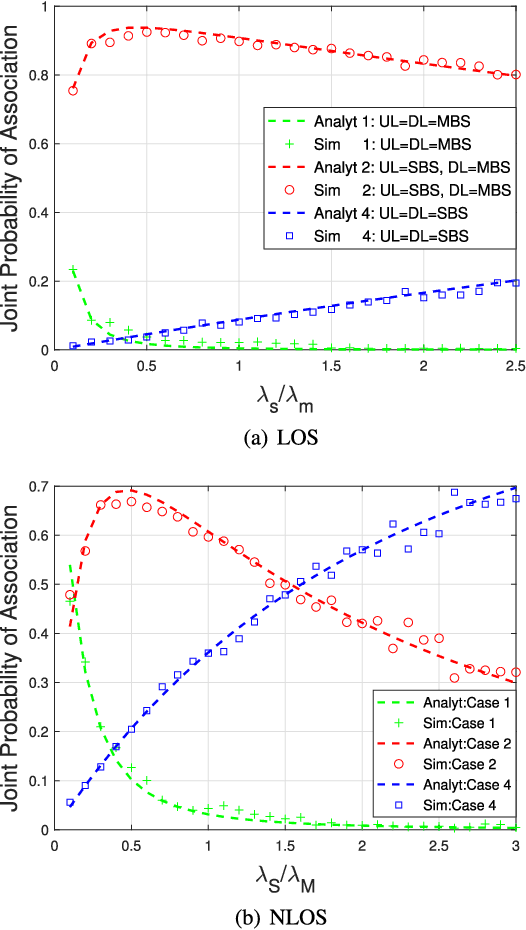
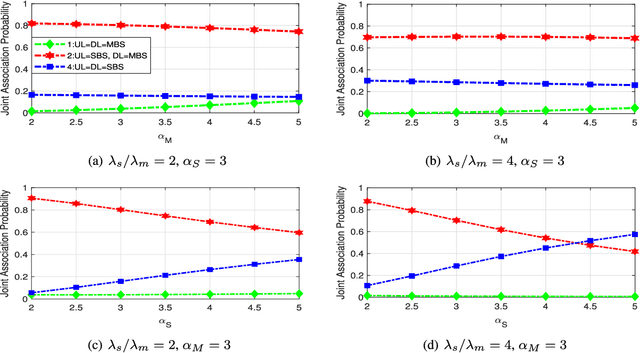
This paper firstly develops an analytical framework to investigate the performance of uplink (UL) / downlink (DL) decoupled access in cellular vehicle-to-everything (C-V2X) networks, in which a vehicle's UL/DL can be connected to different macro/small base stations (MBSs/SBSs) separately. Using the stochastic geometry analytical tool, the UL/DL decoupled access C-V2X is modeled as a Cox process, and we obtain the following theoretical results, i.e., 1) the probability of different UL/DL joint association cases i.e., both the UL and DL are associated with the different MBSs or SBSs, or they are associated with different types of BSs; 2) the distance distribution of a vehicle to its serving BSs in each case; 3) the spectral efficiency of UL/DL in each case; and 4) the UL/DL coverage probability of MBS/SBS. The analyses reveal the insights and performance gain of UL/DL decoupled access. Through extensive simulations, \textcolor{black}{the accuracy of the proposed analytical framework is validated.} Both the analytical and simulation results show that UL/DL decoupled access can improve spectral efficiency. The theoretical results can be directly used for estimating the statistical performance of a UL/DL decoupled access C-V2X network.
* 15 pages, 10 figures
Super-resolution imaging through a multimode fiber: the physical upsampling of speckle-driven
Jul 11, 2023



Following recent advancements in multimode fiber (MMF), miniaturization of imaging endoscopes has proven crucial for minimally invasive surgery in vivo. Recent progress enabled by super-resolution imaging methods with a data-driven deep learning (DL) framework has balanced the relationship between the core size and resolution. However, most of the DL approaches lack attention to the physical properties of the speckle, which is crucial for reconciling the relationship between the magnification of super-resolution imaging and the quality of reconstruction quality. In the paper, we find that the interferometric process of speckle formation is an essential basis for creating DL models with super-resolution imaging. It physically realizes the upsampling of low-resolution (LR) images and enhances the perceptual capabilities of the models. The finding experimentally validates the role played by the physical upsampling of speckle-driven, effectively complementing the lack of information in data-driven. Experimentally, we break the restriction of the poor reconstruction quality at great magnification by inputting the same size of the speckle with the size of the high-resolution (HR) image to the model. The guidance of our research for endoscopic imaging may accelerate the further development of minimally invasive surgery.
Hyperspectral Image Super-Resolution via Dual-domain Network Based on Hybrid Convolution
Apr 20, 2023Since the number of incident energies is limited, it is difficult to directly acquire hyperspectral images (HSI) with high spatial resolution. Considering the high dimensionality and correlation of HSI, super-resolution (SR) of HSI remains a challenge in the absence of auxiliary high-resolution images. Furthermore, it is very important to extract the spatial features effectively and make full use of the spectral information. This paper proposes a novel HSI super-resolution algorithm, termed dual-domain network based on hybrid convolution (SRDNet). Specifically, a dual-domain network is designed to fully exploit the spatial-spectral and frequency information among the hyper-spectral data. To capture inter-spectral self-similarity, a self-attention learning mechanism (HSL) is devised in the spatial domain. Meanwhile the pyramid structure is applied to increase the acceptance field of attention, which further reinforces the feature representation ability of the network. Moreover, to further improve the perceptual quality of HSI, a frequency loss(HFL) is introduced to optimize the model in the frequency domain. The dynamic weighting mechanism drives the network to gradually refine the generated frequency and excessive smoothing caused by spatial loss. Finally, In order to better fully obtain the mapping relationship between high-resolution space and low-resolution space, a hybrid module of 2D and 3D units with progressive upsampling strategy is utilized in our method. Experiments on a widely used benchmark dataset illustrate that the proposed SRDNet method enhances the texture information of HSI and is superior to state-of-the-art methods.
Low-Light Image Enhancement by Learning Contrastive Representations in Spatial and Frequency Domains
Mar 23, 2023



Images taken under low-light conditions tend to suffer from poor visibility, which can decrease image quality and even reduce the performance of the downstream tasks. It is hard for a CNN-based method to learn generalized features that can recover normal images from the ones under various unknow low-light conditions. In this paper, we propose to incorporate the contrastive learning into an illumination correction network to learn abstract representations to distinguish various low-light conditions in the representation space, with the purpose of enhancing the generalizability of the network. Considering that light conditions can change the frequency components of the images, the representations are learned and compared in both spatial and frequency domains to make full advantage of the contrastive learning. The proposed method is evaluated on LOL and LOL-V2 datasets, the results show that the proposed method achieves better qualitative and quantitative results compared with other state-of-the-arts.