 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaging through multimode fibres with physical prior
Nov 14, 2023Imaging through perturbed multimode fibres based on deep learning has been widely researched. However, existing methods mainly use target-speckle pairs in different configurations. It is challenging to reconstruct targets without trained networks. In this paper, we propose a physics-assisted, unsupervised, learning-based fibre imaging scheme. The role of the physical prior is to simplify the mapping relationship between the speckle pattern and the target image, thereby reducing the computational complexity. The unsupervised network learns target features according to the optimized direction provided by the physical prior. Therefore, the reconstruction process of the online learning only requires a few speckle patterns and unpaired targets. The proposed scheme also increases the generalization ability of the learning-based method in perturbed multimode fibres. Our scheme has the potential to extend the application of multimode fibre imaging.
ITRE: Low-light Image Enhancement Based on Illumination Transmission Ratio Estimation
Oct 08, 2023



Noise, artifacts, and over-exposure are significant challenges in the field of low-light image enhancement. Existing methods often struggle to address these issues simultaneously. In this paper, we propose a novel Retinex-based method, called ITRE, which suppresses noise and artifacts from the origin of the model, prevents over-exposure throughout the enhancement process. Specifically, we assume that there must exist a pixel which is least disturbed by low light within pixels of same color. First, clustering the pixels on the RGB color space to find the Illumination Transmission Ratio (ITR) matrix of the whole image, which determines that noise is not over-amplified easily. Next, we consider ITR of the image as the initial illumination transmission map to construct a base model for refined transmission map, which prevents artifacts. Additionally, we design an over-exposure module that captures the fundamental characteristics of pixel over-exposure and seamlessly integrate it into the base model. Finally, there is a possibility of weak enhancement when inter-class distance of pixels with same color is too small. To counteract this, we design a Robust-Guard module that safeguards the robustness of the image enhancement process. Extensive experiments demonstrate the effectiveness of our approach in suppressing noise, preventing artifacts, and controlling over-exposure level simultaneously. Our method performs superiority in qualitative and quantitative performance evaluations by comparing with state-of-the-art methods.
Super-resolution imaging through a multimode fiber: the physical upsampling of speckle-driven
Jul 11, 2023



Following recent advancements in multimode fiber (MMF), miniaturization of imaging endoscopes has proven crucial for minimally invasive surgery in vivo. Recent progress enabled by super-resolution imaging methods with a data-driven deep learning (DL) framework has balanced the relationship between the core size and resolution. However, most of the DL approaches lack attention to the physical properties of the speckle, which is crucial for reconciling the relationship between the magnification of super-resolution imaging and the quality of reconstruction quality. In the paper, we find that the interferometric process of speckle formation is an essential basis for creating DL models with super-resolution imaging. It physically realizes the upsampling of low-resolution (LR) images and enhances the perceptual capabilities of the models. The finding experimentally validates the role played by the physical upsampling of speckle-driven, effectively complementing the lack of information in data-driven. Experimentally, we break the restriction of the poor reconstruction quality at great magnification by inputting the same size of the speckle with the size of the high-resolution (HR) image to the model. The guidance of our research for endoscopic imaging may accelerate the further development of minimally invasive surgery.
Hyperspectral Image Super-Resolution via Dual-domain Network Based on Hybrid Convolution
Apr 20, 2023Since the number of incident energies is limited, it is difficult to directly acquire hyperspectral images (HSI) with high spatial resolution. Considering the high dimensionality and correlation of HSI, super-resolution (SR) of HSI remains a challenge in the absence of auxiliary high-resolution images. Furthermore, it is very important to extract the spatial features effectively and make full use of the spectral information. This paper proposes a novel HSI super-resolution algorithm, termed dual-domain network based on hybrid convolution (SRDNet). Specifically, a dual-domain network is designed to fully exploit the spatial-spectral and frequency information among the hyper-spectral data. To capture inter-spectral self-similarity, a self-attention learning mechanism (HSL) is devised in the spatial domain. Meanwhile the pyramid structure is applied to increase the acceptance field of attention, which further reinforces the feature representation ability of the network. Moreover, to further improve the perceptual quality of HSI, a frequency loss(HFL) is introduced to optimize the model in the frequency domain. The dynamic weighting mechanism drives the network to gradually refine the generated frequency and excessive smoothing caused by spatial loss. Finally, In order to better fully obtain the mapping relationship between high-resolution space and low-resolution space, a hybrid module of 2D and 3D units with progressive upsampling strategy is utilized in our method. Experiments on a widely used benchmark dataset illustrate that the proposed SRDNet method enhances the texture information of HSI and is superior to state-of-the-art methods.
Fast optical refocusing through multimode fiber bend using Cake-Cutting Hadamard encoding algorithm to improve robustness
Jul 27, 2022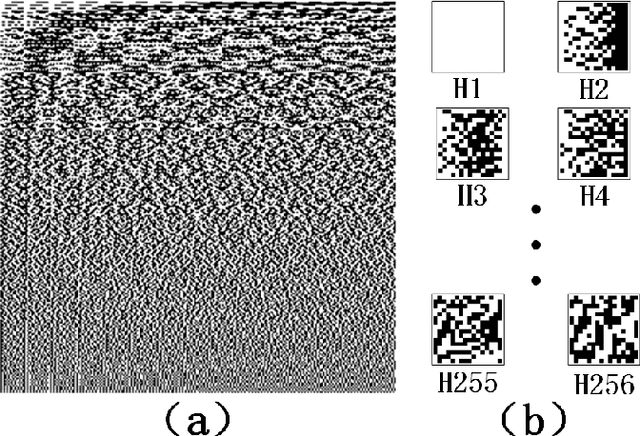

Multimode fibres offer the advantages of high resolution and miniaturization over single mode fibers in the field of optical imaging. However, multimode fibre's imaging is susceptible to perturbations of MMF that can lead to secondary spatial distortions in the transmitted image. Perturbations include random disturbances in the fiber as well as environmental noise. Here, we exploit the fast focusing capability of the Cake-Cutting Hadamard coding algorithm to counteract the effects of perturbations and improve the system's robustness. Simulation shows that it can approach the theoretical enhancement at 2000 measurements. Experimental results show that the algorithm can help the system to refocus in a short time when MMFs are perturbed. This research will further contribute to using multimode fibres in medicine, communication, and detection.
Convolutional Free-space Optical Neural Networks for Image Recognition
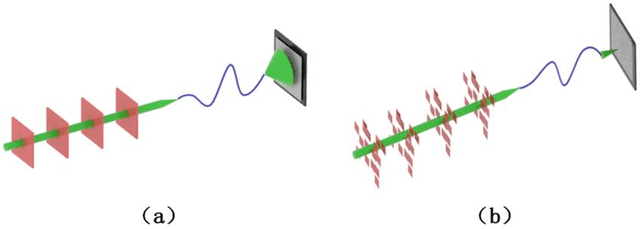
Mar 14, 2021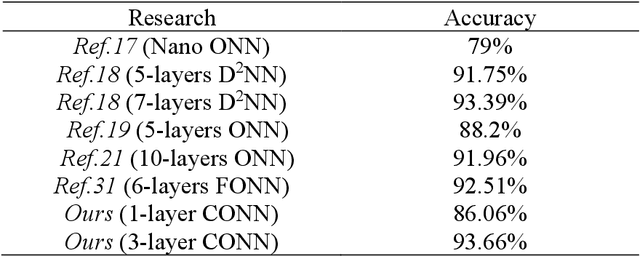
With its unique parallel processing capability, optical neural network has shown low-power consumption in image recognition and speech processing. At present, the manufacturing technology of programmable photonic chip is not mature, and the realization of optical neural network in free-space is still a hot spot of photonic AI. In this letter, based on MNIST datasets and 4f system, one- and three-layer optical neural networks are constructed, whose recognition accuracy can reach 86.06% and 93.66%, respectively. Our network is better than the existing free-space optical neural network in terms of spatial complexity, and the three-layer's accuracy.
Object Tracking Using Spatio-Temporal Future Prediction
Oct 15, 2020

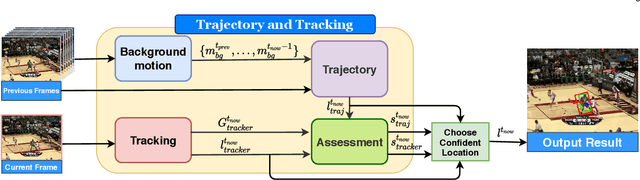
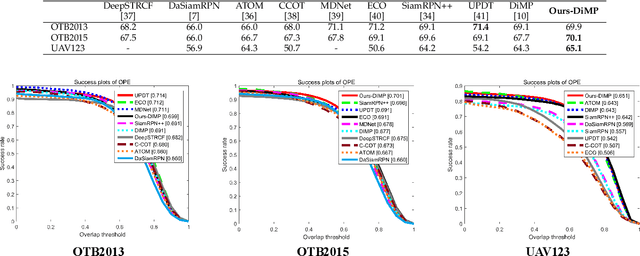
Occlusion is a long-standing problem that causes many modern tracking methods to be erroneous. In this paper, we address the occlusion problem by exploiting the current and future possible locations of the target object from its past trajectory. To achieve this, we introduce a learning-based tracking method that takes into account background motion modeling and trajectory prediction. Our trajectory prediction module predicts the target object's locations in the current and future frames based on the object's past trajectory. Since, in the input video, the target object's trajectory is not only affected by the object motion but also the camera motion, our background motion module estimates the camera motion. So that the object's trajectory can be made independent from it. To dynamically switch between the appearance-based tracker and the trajectory prediction, we employ a network that can assess how good a tracking prediction is, and we use the assessment scores to choose between the appearance-based tracker's prediction and the trajectory-based prediction. Comprehensive evaluations show that the proposed method sets a new state-of-the-art performance on commonly used tracking benchmarks.
Thermal Infrared Colorization via Conditional Generative Adversarial Network
Nov 05, 2018
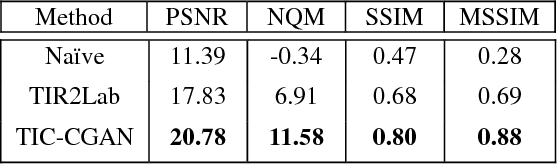
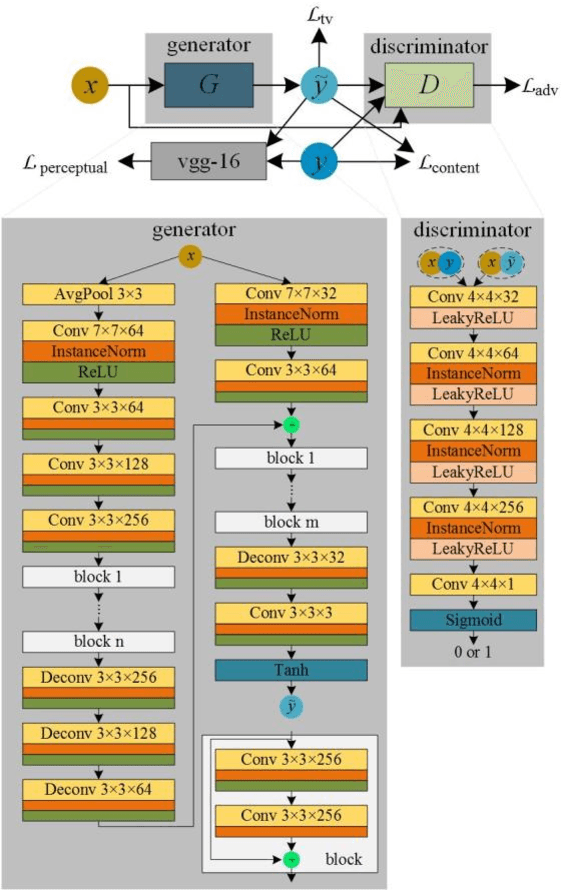

Transforming a thermal infrared image into a realistic RGB image is a challenging task. In this paper we propose a deep learning method to bridge this gap. We propose learning the transformation mapping using a coarse-to-fine generator that preserves the details. Since the standard mean squared loss cannot penalize the distance between colorized and ground truth images well, we propose a composite loss function that combines content, adversarial, perceptual and total variation losses. The content loss is used to recover global image information while the latter three losses are used to synthesize local realistic textures. Quantitative and qualitative experiments demonstrate that our approach significantly outperforms existing approaches.