 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervision-free Vision-Language Alignment
Jan 08, 2025Vision-language models (VLMs) have demonstrated remarkable potential in integrating visual and linguistic information, but their performance is often constrained by the need for extensive, high-quality image-text training data. Curation of these image-text pairs is both time-consuming and computationally expensive. To address this challenge, we introduce SVP (Supervision-free Visual Projection), a novel framework that enhances vision-language alignment without relying on curated data or preference annotation. SVP leverages self-captioning and a pre-trained grounding model as a feedback mechanism to elicit latent information in VLMs. We evaluate our approach across six key areas: captioning, referring, visual question answering, multitasking, hallucination control, and object recall. Results demonstrate significant improvements, including a 14% average improvement in captioning tasks, up to 12% increase in object recall, and substantial reduction in hallucination rates. Notably, a small VLM using SVP achieves hallucination reductions comparable to a model five times larger, while a VLM with initially poor referring capabilities more than doubles its performance, approaching parity with a model twice its size.
AdAM: Few-Shot Image Generation via Adaptation-Aware Kernel Modulation
Jul 08, 2023Few-shot image generation (FSIG) aims to learn to generate new and diverse images given few (e.g., 10) training samples. Recent work has addressed FSIG by leveraging a GAN pre-trained on a large-scale source domain and adapting it to the target domain with few target samples. Central to recent FSIG methods are knowledge preservation criteria, which select and preserve a subset of source knowledge to the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/task and fail to consider target domain/adaptation in selecting source knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. Firstly, we revisit recent FSIG works and their experiments. We reveal that under setups which assumption of close proximity between source and target domains is relaxed, many existing state-of-the-art (SOTA) methods which consider only source domain in knowledge preserving perform no better than a baseline method. As our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) for general FSIG of different source-target domain proximity. Extensive experiments show that AdAM consistently achieves SOTA performance in FSIG, including challenging setups where source and target domains are more apart.
Estimating Reflectance Layer from A Single Image: Integrating Reflectance Guidance and Shadow/Specular Aware Learning
Nov 27, 2022Estimating reflectance layer from a single image is a challenging task. It becomes more challenging when the input image contains shadows or specular highlights, which often render an inaccurate estimate of the reflectance layer. Therefore, we propose a two-stage learning method, including reflectance guidance and a Shadow/Specular-Aware (S-Aware) network to tackle the problem. In the first stage, an initial reflectance layer free from shadows and specularities is obtained with the constraint of novel losses that are guided by prior-based shadow-free and specular-free images. To further enforce the reflectance layer to be independent from shadows and specularities in the second-stage refinement, we introduce an S-Aware network that distinguishes the reflectance image from the input image. Our network employs a classifier to categorize shadow/shadow-free, specular/specular-free classes, enabling the activation features to function as attention maps that focus on shadow/specular regions. Our quantitative and qualitative evaluations show that our method outperforms the state-of-the-art methods in the reflectance layer estimation that is free from shadows and specularities.
* Accepted to AAAI2023
Object Tracking Using Spatio-Temporal Future Prediction
Oct 15, 2020

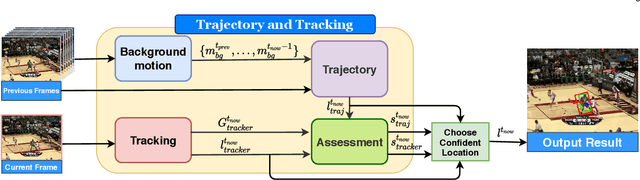
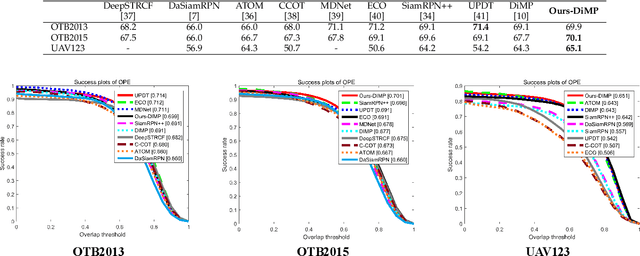
Occlusion is a long-standing problem that causes many modern tracking methods to be erroneous. In this paper, we address the occlusion problem by exploiting the current and future possible locations of the target object from its past trajectory. To achieve this, we introduce a learning-based tracking method that takes into account background motion modeling and trajectory prediction. Our trajectory prediction module predicts the target object's locations in the current and future frames based on the object's past trajectory. Since, in the input video, the target object's trajectory is not only affected by the object motion but also the camera motion, our background motion module estimates the camera motion. So that the object's trajectory can be made independent from it. To dynamically switch between the appearance-based tracker and the trajectory prediction, we employ a network that can assess how good a tracking prediction is, and we use the assessment scores to choose between the appearance-based tracker's prediction and the trajectory-based prediction. Comprehensive evaluations show that the proposed method sets a new state-of-the-art performance on commonly used tracking benchmarks.
Learning to Dehaze From Realistic Scene with A Fast Physics Based Dehazing Network
Apr 18, 2020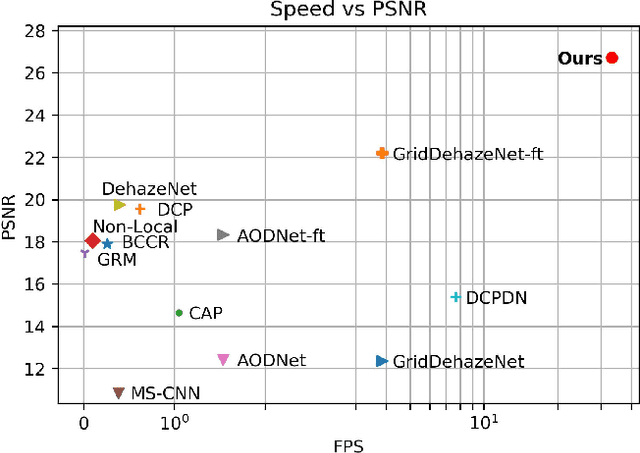


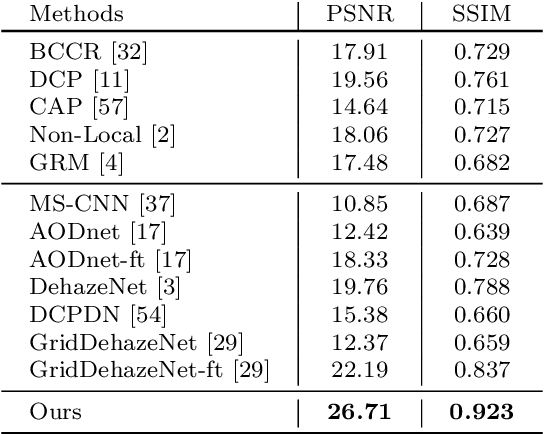
Dehaze is one of the popular computer vision research topics for long. A realtime method with reliable performance is highly desired for a lot of applications such as autonomous driving. In recent years, while learning based methods require datasets containing pairs of hazy images and clean ground truth references, it is generally impossible to capture this kind of data in real. Many existing researches compromise this difficulty to generate hazy images by rendering the haze from depth on common RGBD datasets using the haze imaging model. However, there is still a gap between the synthetic datasets and real hazy images as large datasets with high quality depth are mostly indoor and depth maps for outdoor are imprecise. In this paper, we complement the exiting datasets with a new, large, and diverse dehazing dataset containing real outdoor scenes from HD 3D videos. We select large number of high quality frames of real outdoor scenes and render haze on them using depth from stereo. Our dataset is more realistic than existing ones and we demonstrate that using this dataset greatly improves the dehazing performance on real scenes. In addition to the dataset, inspired by the physics model, we also propose a light and reliable dehaze network. Our approach outperforms other methods by a large margin and becomes the new state-of-the-art method. Moreover, the light design of the network enables our methods to run at realtime speed that is much faster than other methods.
Deep Reflection Prior
Dec 08, 2019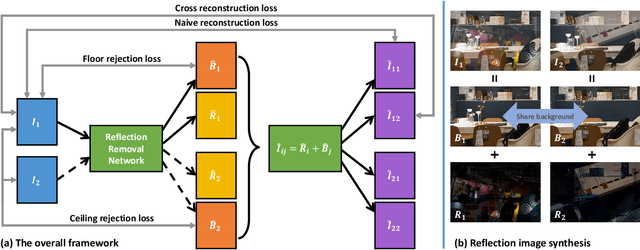
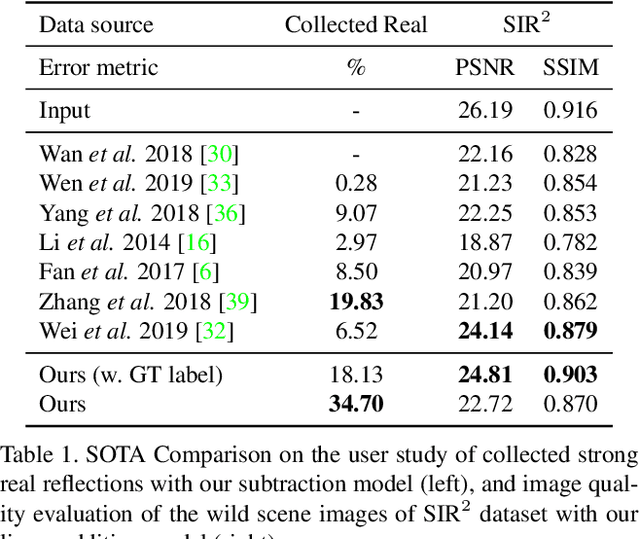
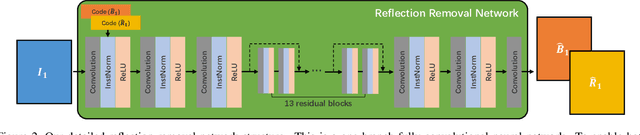

Reflections are very common phenomena in our daily photography, which distract people's attention from the scene behind the glass. The problem of removing reflection artifacts is important but challenging due to its ill-posed nature. Recent learning-based approaches have demonstrated a significant improvement in removing reflections. However, these methods are limited as they require a large number of synthetic reflection/clean image pairs for supervision, at the risk of overfitting in the synthetic image domain. In this paper, we propose a learning-based approach that captures the reflection statistical prior for single image reflection removal. Our algorithm is driven by optimizing the target with joint constraints enhanced between multiple input images during the training stage, but is able to eliminate reflections only from a single input for evaluation. Our framework allows to predict both background and reflection via a one-branch deep neural network, which is implemented by the controllable latent code that indicates either the background or reflection output. We demonstrate superior performance over the state-of-the-art methods on a large range of real-world images. We further provide insightful analysis behind the learned latent code, which may inspire more future work.
GraphX$^{NET}-$ Chest X-Ray Classification Under Extreme Minimal Supervision
Jul 25, 2019
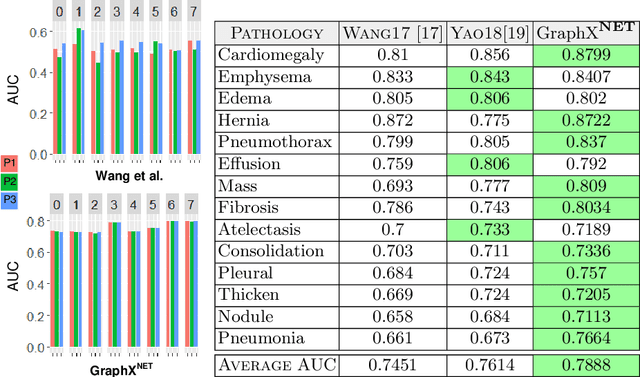
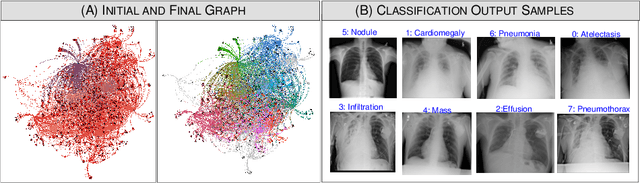

The task of classifying X-ray data is a problem of both theoretical and clinical interest. Whilst supervised deep learning methods rely upon huge amounts of labelled data, the critical problem of achieving a good classification accuracy when an extremely small amount of labelled data is available has yet to be tackled. In this work, we introduce a novel semi-supervised framework for X-ray classification which is based on a graph-based optimisation model. To the best of our knowledge, this is the first method that exploits graph-based semi-supervised learning for X-ray data classification. Furthermore, we introduce a new multi-class classification functional with carefully selected class priors which allows for a smooth solution that strengthens the synergy between the limited number of labels and the huge amount of unlabelled data. We demonstrate, through a set of numerical and visual experiments, that our method produces highly competitive results on the ChestX-ray14 data set whilst drastically reducing the need for annotated data.
Beyond Supervised Classification: Extreme Minimal Supervision with the Graph 1-Laplacian
Jun 20, 2019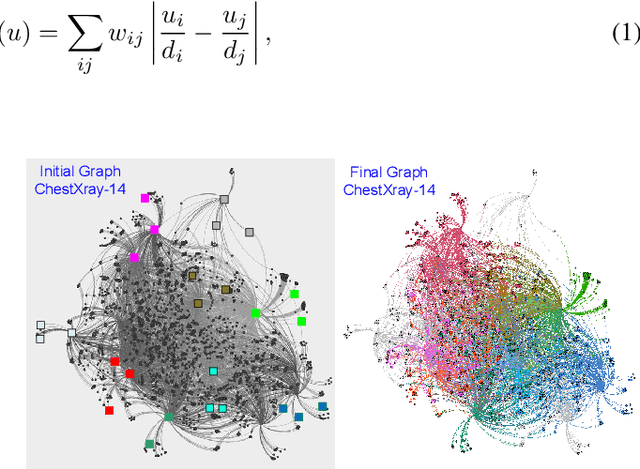
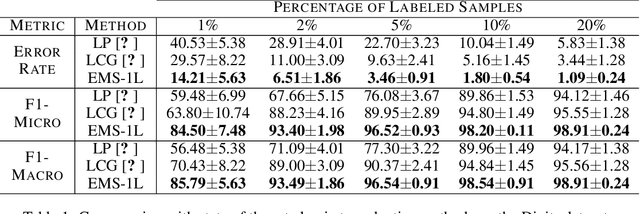
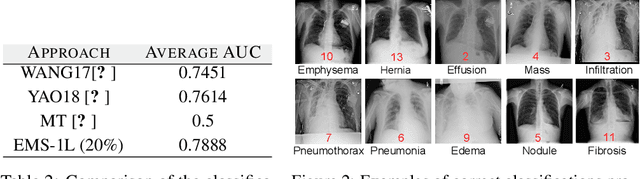
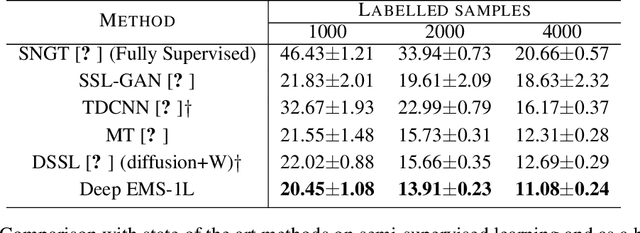
We consider the task of classifying when an extremely reduced amount of labelled data is available. This problem is of a great interest, in several real-world problems, as obtaining large amounts of labelled data is expensive and time consuming. We present a novel semi-supervised framework for multi-class classification that is based on the normalised and non-smooth graph 1-Laplacian. Our transductive framework is framed under a novel functional with carefully selected class priors - that enforces a sufficiently smooth solution that strengthens the intrinsic relation between the labelled and unlabelled data. We demonstrate through extensive experimental results on large datasets CIFAR-10 and ChestX-ray14, that our method outperforms classic methods and readily competes with recent deep-learning approaches.
Single Image Deraining using Scale-Aware Multi-Stage Recurrent Network
Dec 19, 2017
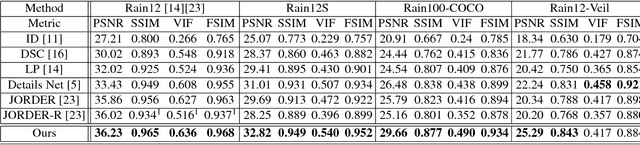


Given a single input rainy image, our goal is to visually remove rain streaks and the veiling effect caused by scattering and transmission of rain streaks and rain droplets. We are particularly concerned with heavy rain, where rain streaks of various sizes and directions can overlap each other and the veiling effect reduces contrast severely. To achieve our goal, we introduce a scale-aware multi-stage convolutional neural network. Our main idea here is that different sizes of rain-streaks visually degrade the scene in different ways. Large nearby streaks obstruct larger regions and are likely to reflect specular highlights more prominently than smaller distant streaks. These different effects of different streaks have their own characteristics in their image features, and thus need to be treated differently. To realize this, we create parallel sub-networks that are trained and made aware of these different scales of rain streaks. To our knowledge, this idea of parallel sub-networks that treats the same class of objects according to their unique sub-classes is novel, particularly in the context of rain removal. To verify our idea, we conducted experiments on both synthetic and real images, and found that our method is effective and outperforms the state-of-the-art methods.
Robust Optical Flow Estimation in Rainy Scenes
Nov 28, 2017



Optical flow estimation in the rainy scenes is challenging due to background degradation introduced by rain streaks and rain accumulation effects in the scene. Rain accumulation effect refers to poor visibility of remote objects due to the intense rainfall. Most existing optical flow methods are erroneous when applied to rain sequences because the conventional brightness constancy constraint (BCC) and gradient constancy constraint (GCC) generally break down in this situation. Based on the observation that the RGB color channels receive raindrop radiance equally, we introduce a residue channel as a new data constraint to reduce the effect of rain streaks. To handle rain accumulation, our method decomposes the image into a piecewise-smooth background layer and a high-frequency detail layer. It also enforces the BCC on the background layer only. Results on both synthetic dataset and real images show that our algorithm outperforms existing methods on different types of rain sequences. To our knowledge, this is the first optical flow method specifically dealing with rain.