 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Normal Estimation via Shading Sequence Estimation
Feb 11, 2026Monocular normal estimation aims to estimate the normal map from a single RGB image of an object under arbitrary lights. Existing methods rely on deep models to directly predict normal maps. However, they often suffer from 3D misalignment: while the estimated normal maps may appear to have a correct appearance, the reconstructed surfaces often fail to align with the geometric details. We argue that this misalignment stems from the current paradigm: the model struggles to distinguish and reconstruct varying geometry represented in normal maps, as the differences in underlying geometry are reflected only through relatively subtle color variations. To address this issue, we propose a new paradigm that reformulates normal estimation as shading sequence estimation, where shading sequences are more sensitive to various geometric information. Building on this paradigm, we present RoSE, a method that leverages image-to-video generative models to predict shading sequences. The predicted shading sequences are then converted into normal maps by solving a simple ordinary least-squares problem. To enhance robustness and better handle complex objects, RoSE is trained on a synthetic dataset, MultiShade, with diverse shapes, materials, and light conditions. Experiments demonstrate that RoSE achieves state-of-the-art performance on real-world benchmark datasets for object-based monocular normal estimation.
ThinkGen: Generalized Thinking for Visual Generation
Dec 29, 2025Recent progress in Multimodal Large Language Models (MLLMs) demonstrates that Chain-of-Thought (CoT) reasoning enables systematic solutions to complex understanding tasks. However, its extension to generation tasks remains nascent and limited by scenario-specific mechanisms that hinder generalization and adaptation. In this work, we present ThinkGen, the first think-driven visual generation framework that explicitly leverages MLLM's CoT reasoning in various generation scenarios. ThinkGen employs a decoupled architecture comprising a pretrained MLLM and a Diffusion Transformer (DiT), wherein the MLLM generates tailored instructions based on user intent, and DiT produces high-quality images guided by these instructions. We further propose a separable GRPO-based training paradigm (SepGRPO), alternating reinforcement learning between the MLLM and DiT modules. This flexible design enables joint training across diverse datasets, facilitating effective CoT reasoning for a wide range of generative scenarios. Extensive experiments demonstrate that ThinkGen achieves robust, state-of-the-art performance across multiple generation benchmarks. Code is available: https://github.com/jiaosiyuu/ThinkGen
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
AdAM: Few-Shot Image Generation via Adaptation-Aware Kernel Modulation
Jul 08, 2023Few-shot image generation (FSIG) aims to learn to generate new and diverse images given few (e.g., 10) training samples. Recent work has addressed FSIG by leveraging a GAN pre-trained on a large-scale source domain and adapting it to the target domain with few target samples. Central to recent FSIG methods are knowledge preservation criteria, which select and preserve a subset of source knowledge to the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/task and fail to consider target domain/adaptation in selecting source knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. Firstly, we revisit recent FSIG works and their experiments. We reveal that under setups which assumption of close proximity between source and target domains is relaxed, many existing state-of-the-art (SOTA) methods which consider only source domain in knowledge preserving perform no better than a baseline method. As our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) for general FSIG of different source-target domain proximity. Extensive experiments show that AdAM consistently achieves SOTA performance in FSIG, including challenging setups where source and target domains are more apart.
On Evaluating Adversarial Robustness of Large Vision-Language Models
May 26, 2023Large vision-language models (VLMs) such as GPT-4 have achieved unprecedented performance in response generation, especially with visual inputs, enabling more creative and adaptable interaction than large language models such as ChatGPT. Nonetheless, multimodal generation exacerbates safety concerns, since adversaries may successfully evade the entire system by subtly manipulating the most vulnerable modality (e.g., vision). To this end, we propose evaluating the robustness of open-source large VLMs in the most realistic and high-risk setting, where adversaries have only black-box system access and seek to deceive the model into returning the targeted responses. In particular, we first craft targeted adversarial examples against pretrained models such as CLIP and BLIP, and then transfer these adversarial examples to other VLMs such as MiniGPT-4, LLaVA, UniDiffuser, BLIP-2, and Img2Prompt. In addition, we observe that black-box queries on these VLMs can further improve the effectiveness of targeted evasion, resulting in a surprisingly high success rate for generating targeted responses. Our findings provide a quantitative understanding regarding the adversarial vulnerability of large VLMs and call for a more thorough examination of their potential security flaws before deployment in practice. Code is at https://github.com/yunqing-me/AttackVLM.
Exploring Incompatible Knowledge Transfer in Few-shot Image Generation
Apr 15, 2023Few-shot image generation (FSIG) learns to generate diverse and high-fidelity images from a target domain using a few (e.g., 10) reference samples. Existing FSIG methods select, preserve and transfer prior knowledge from a source generator (pretrained on a related domain) to learn the target generator. In this work, we investigate an underexplored issue in FSIG, dubbed as incompatible knowledge transfer, which would significantly degrade the realisticness of synthetic samples. Empirical observations show that the issue stems from the least significant filters from the source generator. To this end, we propose knowledge truncation to mitigate this issue in FSIG, which is a complementary operation to knowledge preservation and is implemented by a lightweight pruning-based method. Extensive experiments show that knowledge truncation is simple and effective, consistently achieving state-of-the-art performance, including challenging setups where the source and target domains are more distant. Project Page: yunqing-me.github.io/RICK.
A Recipe for Watermarking Diffusion Models
Mar 17, 2023



Recently, diffusion models (DMs) have demonstrated their advantageous potential for generative tasks. Widespread interest exists in incorporating DMs into downstream applications, such as producing or editing photorealistic images. However, practical deployment and unprecedented power of DMs raise legal issues, including copyright protection and monitoring of generated content. In this regard, watermarking has been a proven solution for copyright protection and content monitoring, but it is underexplored in the DMs literature. Specifically, DMs generate samples from longer tracks and may have newly designed multimodal structures, necessitating the modification of conventional watermarking pipelines. To this end, we conduct comprehensive analyses and derive a recipe for efficiently watermarking state-of-the-art DMs (e.g., Stable Diffusion), via training from scratch or finetuning. Our recipe is straightforward but involves empirically ablated implementation details, providing a solid foundation for future research on watermarking DMs. Our Code: https://github.com/yunqing-me/WatermarkDM.
Few-shot Image Generation via Adaptation-Aware Kernel Modulation
Nov 13, 2022Few-shot image generation (FSIG) aims to learn to generate new and diverse samples given an extremely limited number of samples from a domain, e.g., 10 training samples. Recent work has addressed the problem using transfer learning approach, leveraging a GAN pretrained on a large-scale source domain dataset and adapting that model to the target domain based on very limited target domain samples. Central to recent FSIG methods are knowledge preserving criteria, which aim to select a subset of source model's knowledge to be preserved into the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/source task, and they fail to consider target domain/adaptation task in selecting source model's knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. As our first contribution, we re-visit recent FSIG works and their experiments. Our important finding is that, under setups which assumption of close proximity between source and target domains is relaxed, existing state-of-the-art (SOTA) methods which consider only source domain/source task in knowledge preserving perform no better than a baseline fine-tuning method. To address the limitation of existing methods, as our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) to address general FSIG of different source-target domain proximity. Extensive experimental results show that the proposed method consistently achieves SOTA performance across source/target domains of different proximity, including challenging setups when source and target domains are more apart. Project Page: https://yunqing-me.github.io/AdAM/
FS-BAN: Born-Again Networks for Domain Generalization Few-Shot Classification
Aug 24, 2022

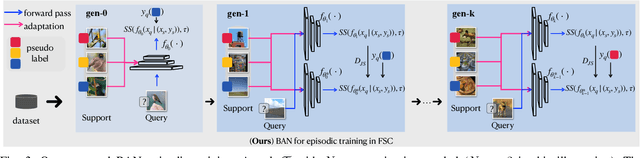
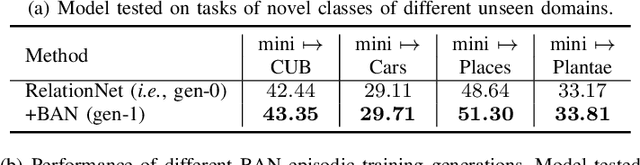
Conventional Few-shot classification (FSC) aims to recognize samples from novel classes given limited labeled data. Recently, domain generalization FSC (DG-FSC) has been proposed with the goal to recognize novel class samples from unseen domains. DG-FSC poses considerable challenges to many models due to the domain shift between base classes (used in training) and novel classes (encountered in evaluation). In this work, we make two novel contributions to tackle DG-FSC. Our first contribution is to propose Born-Again Network (BAN) episodic training and comprehensively investigate its effectiveness for DG-FSC. As a specific form of knowledge distillation, BAN has been shown to achieve improved generalization in conventional supervised classification with a closed-set setup. This improved generalization motivates us to study BAN for DG-FSC, and we show that BAN is promising to address the domain shift encountered in DG-FSC. Building on the encouraging finding, our second (major) contribution is to propose few-shot BAN, FS-BAN, a novel BAN approach for DG-FSC. Our proposed FS-BAN includes novel multi-task learning objectives: Mutual Regularization, Mismatched Teacher and Meta-Control Temperature, each of these is specifically designed to overcome central and unique challenges in DG-FSC, namely overfitting and domain discrepancy. We analyze different design choices of these techniques. We conduct comprehensive quantitative and qualitative analysis and evaluation using six datasets and three baseline models. The results suggest that our proposed FS-BAN consistently improves the generalization performance of baseline models and achieves state-of-the-art accuracy for DG-FSC.
Revisiting Label Smoothing and Knowledge Distillation Compatibility: What was Missing?
Jun 29, 2022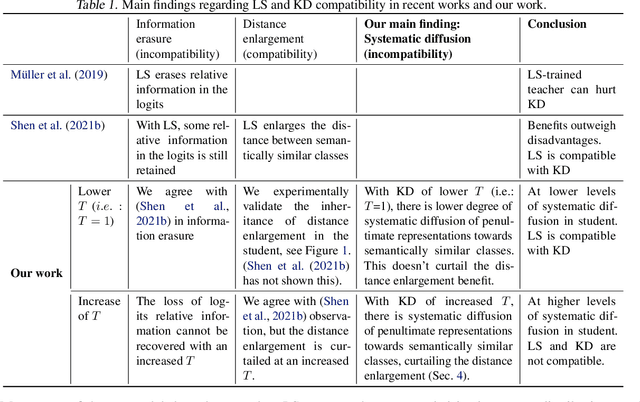
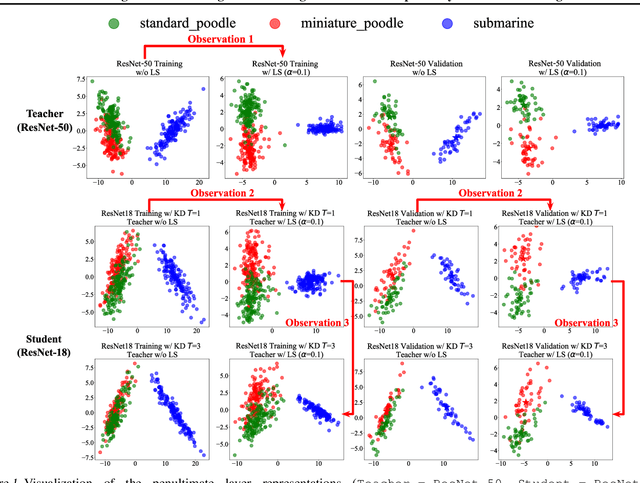

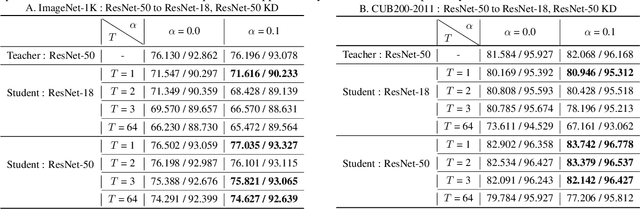
This work investigates the compatibility between label smoothing (LS) and knowledge distillation (KD). Contemporary findings addressing this thesis statement take dichotomous standpoints: Muller et al. (2019) and Shen et al. (2021b). Critically, there is no effort to understand and resolve these contradictory findings, leaving the primal question -- to smooth or not to smooth a teacher network? -- unanswered. The main contributions of our work are the discovery, analysis and validation of systematic diffusion as the missing concept which is instrumental in understanding and resolving these contradictory findings. This systematic diffusion essentially curtails the benefits of distilling from an LS-trained teacher, thereby rendering KD at increased temperatures ineffective. Our discovery is comprehensively supported by large-scale experiments, analyses and case studies including image classification, neural machine translation and compact student distillation tasks spanning across multiple datasets and teacher-student architectures. Based on our analysis, we suggest practitioners to use an LS-trained teacher with a low-temperature transfer to achieve high performance students. Code and models are available at https://keshik6.github.io/revisiting-ls-kd-compatibility/