 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
Feb 04, 2026Spatial embodied intelligence requires agents to act to acquire information under partial observability. While multimodal foundation models excel at passive perception, their capacity for active, self-directed exploration remains understudied. We propose Theory of Space, defined as an agent's ability to actively acquire information through self-directed, active exploration and to construct, revise, and exploit a spatial belief from sequential, partial observations. We evaluate this through a benchmark where the goal is curiosity-driven exploration to build an accurate cognitive map. A key innovation is spatial belief probing, which prompts models to reveal their internal spatial representations at each step. Our evaluation of state-of-the-art models reveals several critical bottlenecks. First, we identify an Active-Passive Gap, where performance drops significantly when agents must autonomously gather information. Second, we find high inefficiency, as models explore unsystematically compared to program-based proxies. Through belief probing, we diagnose that while perception is an initial bottleneck, global beliefs suffer from instability that causes spatial knowledge to degrade over time. Finally, using a false belief paradigm, we uncover Belief Inertia, where agents fail to update obsolete priors with new evidence. This issue is present in text-based agents but is particularly severe in vision-based models. Our findings suggest that current foundation models struggle to maintain coherent, revisable spatial beliefs during active exploration.
Spatial Mental Modeling from Limited Views
Jun 26, 2025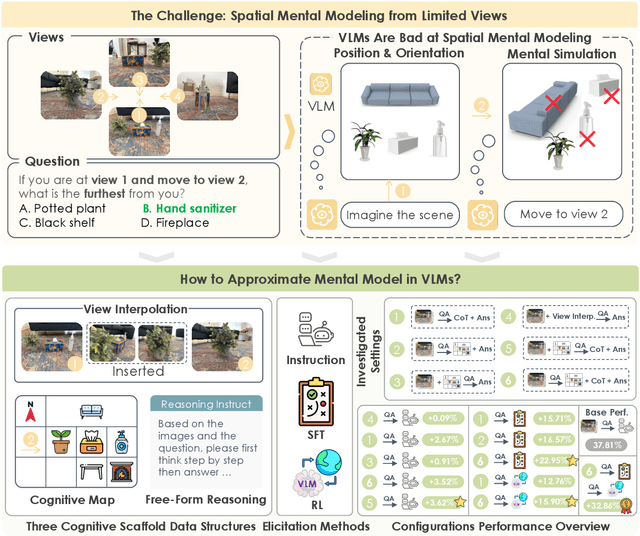

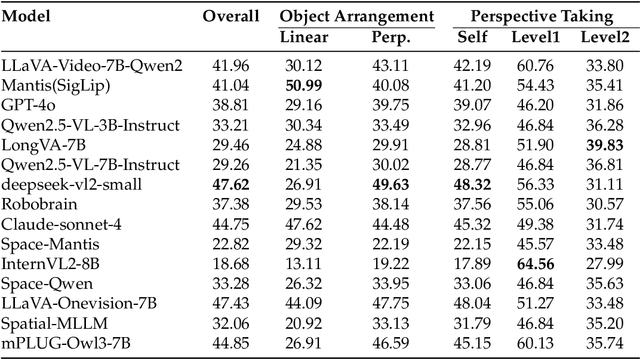
Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
Exploring Diffusion Transformer Designs via Grafting
Jun 06, 2025Designing model architectures requires decisions such as selecting operators (e.g., attention, convolution) and configurations (e.g., depth, width). However, evaluating the impact of these decisions on model quality requires costly pretraining, limiting architectural investigation. Inspired by how new software is built on existing code, we ask: can new architecture designs be studied using pretrained models? To this end, we present grafting, a simple approach for editing pretrained diffusion transformers (DiTs) to materialize new architectures under small compute budgets. Informed by our analysis of activation behavior and attention locality, we construct a testbed based on the DiT-XL/2 design to study the impact of grafting on model quality. Using this testbed, we develop a family of hybrid designs via grafting: replacing softmax attention with gated convolution, local attention, and linear attention, and replacing MLPs with variable expansion ratio and convolutional variants. Notably, many hybrid designs achieve good quality (FID: 2.38-2.64 vs. 2.27 for DiT-XL/2) using <2% pretraining compute. We then graft a text-to-image model (PixArt-Sigma), achieving a 1.43x speedup with less than a 2% drop in GenEval score. Finally, we present a case study that restructures DiT-XL/2 by converting every pair of sequential transformer blocks into parallel blocks via grafting. This reduces model depth by 2x and yields better quality (FID: 2.77) than other models of comparable depth. Together, we show that new diffusion model designs can be explored by grafting pretrained DiTs, with edits ranging from operator replacement to architecture restructuring. Code and grafted models: https://grafting.stanford.edu
Re-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025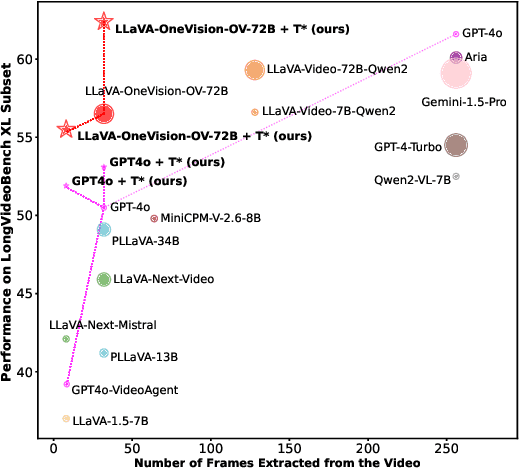
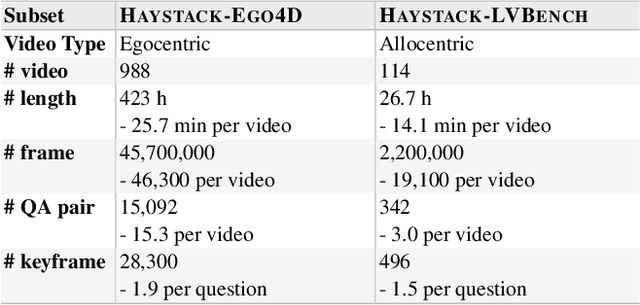
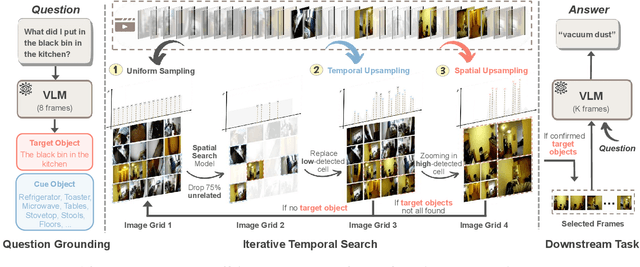
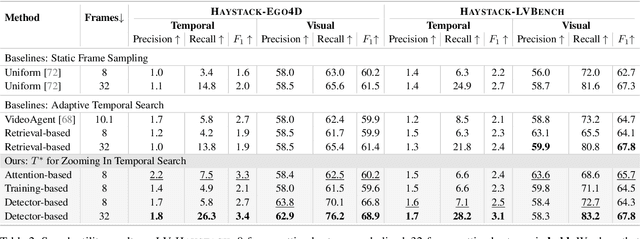
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
HourVideo: 1-Hour Video-Language Understanding
Nov 07, 2024
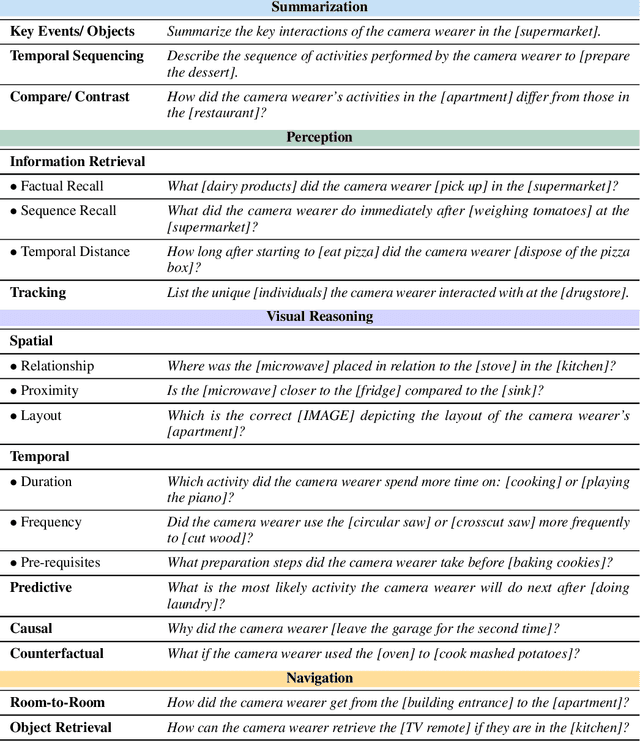

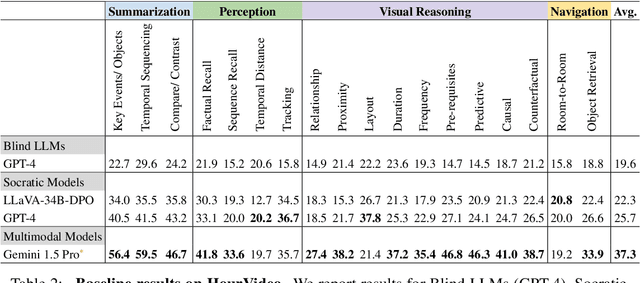
We present HourVideo, a benchmark dataset for hour-long video-language understanding. Our dataset consists of a novel task suite comprising summarization, perception (recall, tracking), visual reasoning (spatial, temporal, predictive, causal, counterfactual), and navigation (room-to-room, object retrieval) tasks. HourVideo includes 500 manually curated egocentric videos from the Ego4D dataset, spanning durations of 20 to 120 minutes, and features 12,976 high-quality, five-way multiple-choice questions. Benchmarking results reveal that multimodal models, including GPT-4 and LLaVA-NeXT, achieve marginal improvements over random chance. In stark contrast, human experts significantly outperform the state-of-the-art long-context multimodal model, Gemini Pro 1.5 (85.0% vs. 37.3%), highlighting a substantial gap in multimodal capabilities. Our benchmark, evaluation toolkit, prompts, and documentation are available at https://hourvideo.stanford.edu
Model Inversion Robustness: Can Transfer Learning Help?
May 09, 2024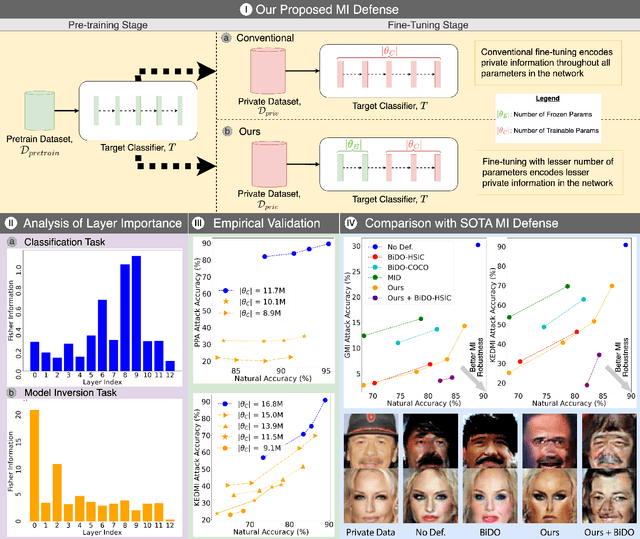

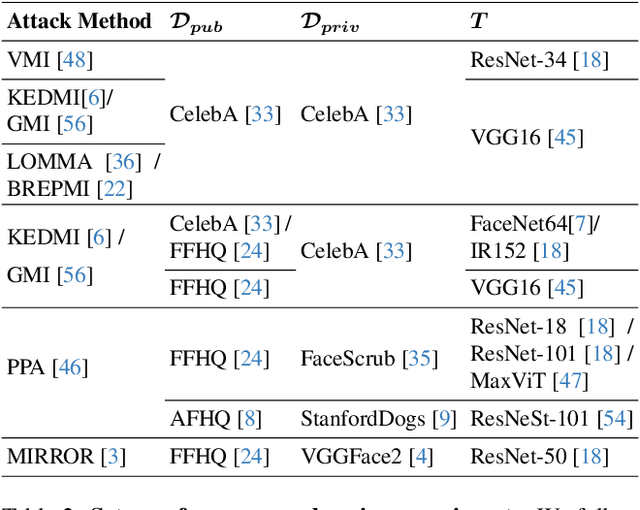
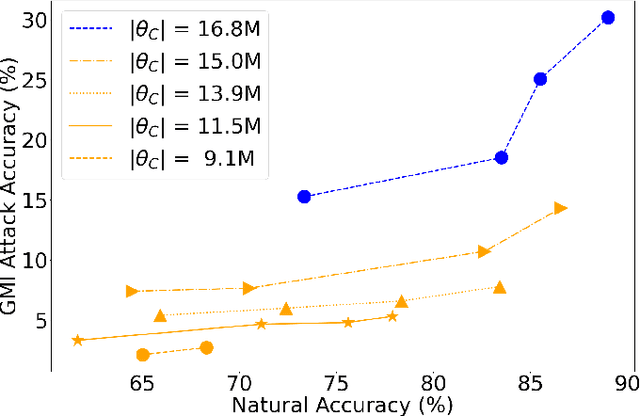
Model Inversion (MI) attacks aim to reconstruct private training data by abusing access to machine learning models. Contemporary MI attacks have achieved impressive attack performance, posing serious threats to privacy. Meanwhile, all existing MI defense methods rely on regularization that is in direct conflict with the training objective, resulting in noticeable degradation in model utility. In this work, we take a different perspective, and propose a novel and simple Transfer Learning-based Defense against Model Inversion (TL-DMI) to render MI-robust models. Particularly, by leveraging TL, we limit the number of layers encoding sensitive information from private training dataset, thereby degrading the performance of MI attack. We conduct an analysis using Fisher Information to justify our method. Our defense is remarkably simple to implement. Without bells and whistles, we show in extensive experiments that TL-DMI achieves state-of-the-art (SOTA) MI robustness. Our code, pre-trained models, demo and inverted data are available at: https://hosytuyen.github.io/projects/TL-DMI
Label-Only Model Inversion Attacks via Knowledge Transfer
Oct 30, 2023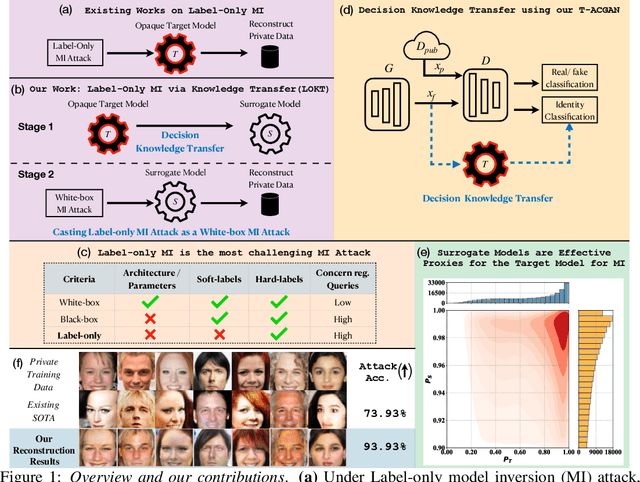
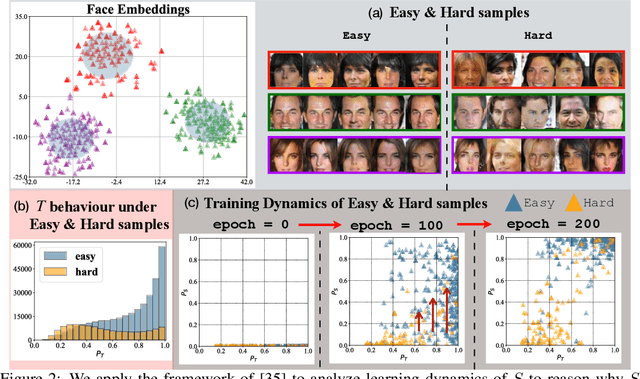
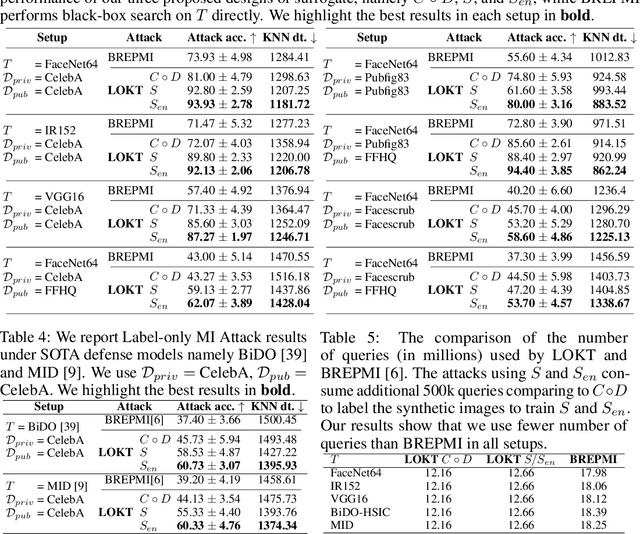

In a model inversion (MI) attack, an adversary abuses access to a machine learning (ML) model to infer and reconstruct private training data. Remarkable progress has been made in the white-box and black-box setups, where the adversary has access to the complete model or the model's soft output respectively. However, there is very limited study in the most challenging but practically important setup: Label-only MI attacks, where the adversary only has access to the model's predicted label (hard label) without confidence scores nor any other model information. In this work, we propose LOKT, a novel approach for label-only MI attacks. Our idea is based on transfer of knowledge from the opaque target model to surrogate models. Subsequently, using these surrogate models, our approach can harness advanced white-box attacks. We propose knowledge transfer based on generative modelling, and introduce a new model, Target model-assisted ACGAN (T-ACGAN), for effective knowledge transfer. Our method casts the challenging label-only MI into the more tractable white-box setup. We provide analysis to support that surrogate models based on our approach serve as effective proxies for the target model for MI. Our experiments show that our method significantly outperforms existing SOTA Label-only MI attack by more than 15% across all MI benchmarks. Furthermore, our method compares favorably in terms of query budget. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our code, demo, models and reconstructed data are available at our project page: https://ngoc-nguyen-0.github.io/lokt/
A Survey on Generative Modeling with Limited Data, Few Shots, and Zero Shot
Jul 26, 2023
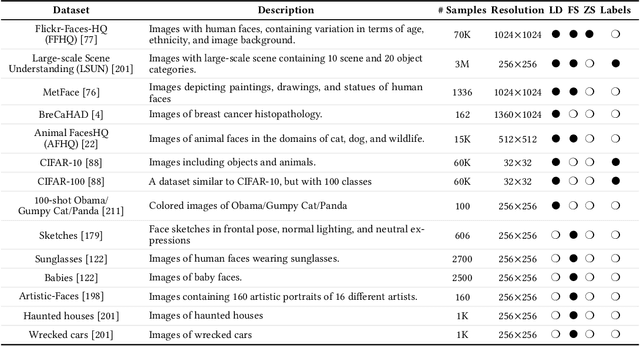

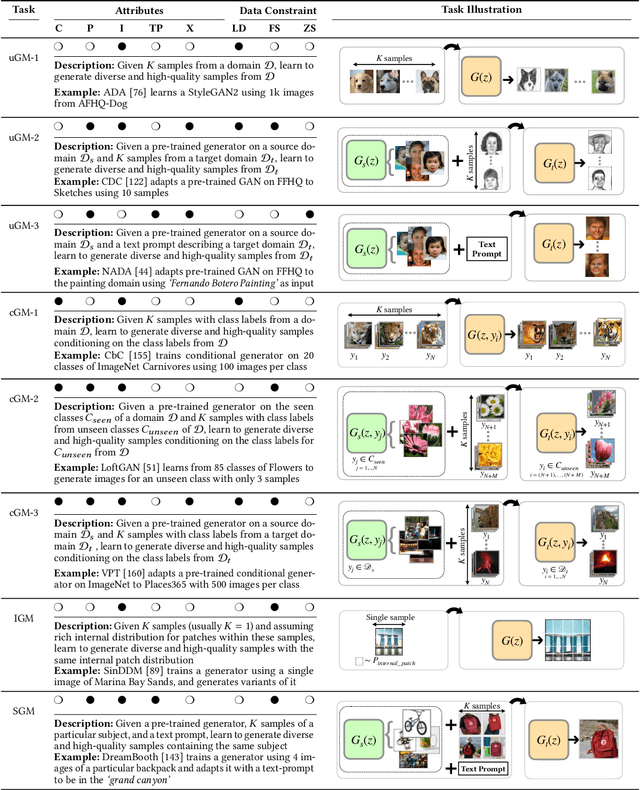
In machine learning, generative modeling aims to learn to generate new data statistically similar to the training data distribution. In this paper, we survey learning generative models under limited data, few shots and zero shot, referred to as Generative Modeling under Data Constraint (GM-DC). This is an important topic when data acquisition is challenging, e.g. healthcare applications. We discuss background, challenges, and propose two taxonomies: one on GM-DC tasks and another on GM-DC approaches. Importantly, we study interactions between different GM-DC tasks and approaches. Furthermore, we highlight research gaps, research trends, and potential avenues for future exploration. Project website: https://gmdc-survey.github.io.
AdAM: Few-Shot Image Generation via Adaptation-Aware Kernel Modulation
Jul 08, 2023Few-shot image generation (FSIG) aims to learn to generate new and diverse images given few (e.g., 10) training samples. Recent work has addressed FSIG by leveraging a GAN pre-trained on a large-scale source domain and adapting it to the target domain with few target samples. Central to recent FSIG methods are knowledge preservation criteria, which select and preserve a subset of source knowledge to the adapted model. However, a major limitation of existing methods is that their knowledge preserving criteria consider only source domain/task and fail to consider target domain/adaptation in selecting source knowledge, casting doubt on their suitability for setups of different proximity between source and target domain. Our work makes two contributions. Firstly, we revisit recent FSIG works and their experiments. We reveal that under setups which assumption of close proximity between source and target domains is relaxed, many existing state-of-the-art (SOTA) methods which consider only source domain in knowledge preserving perform no better than a baseline method. As our second contribution, we propose Adaptation-Aware kernel Modulation (AdAM) for general FSIG of different source-target domain proximity. Extensive experiments show that AdAM consistently achieves SOTA performance in FSIG, including challenging setups where source and target domains are more apart.
Re-thinking Model Inversion Attacks Against Deep Neural Networks
Apr 04, 2023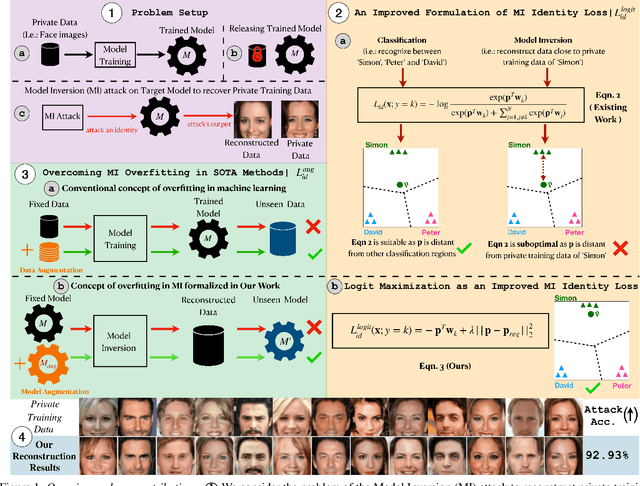

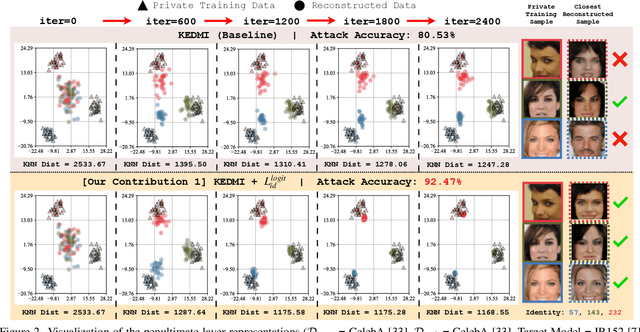
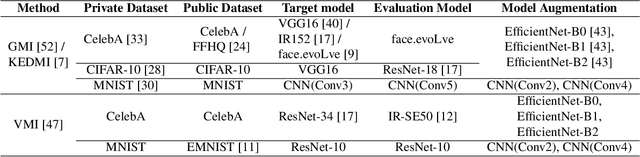
Model inversion (MI) attacks aim to infer and reconstruct private training data by abusing access to a model. MI attacks have raised concerns about the leaking of sensitive information (e.g. private face images used in training a face recognition system). Recently, several algorithms for MI have been proposed to improve the attack performance. In this work, we revisit MI, study two fundamental issues pertaining to all state-of-the-art (SOTA) MI algorithms, and propose solutions to these issues which lead to a significant boost in attack performance for all SOTA MI. In particular, our contributions are two-fold: 1) We analyze the optimization objective of SOTA MI algorithms, argue that the objective is sub-optimal for achieving MI, and propose an improved optimization objective that boosts attack performance significantly. 2) We analyze "MI overfitting", show that it would prevent reconstructed images from learning semantics of training data, and propose a novel "model augmentation" idea to overcome this issue. Our proposed solutions are simple and improve all SOTA MI attack accuracy significantly. E.g., in the standard CelebA benchmark, our solutions improve accuracy by 11.8% and achieve for the first time over 90% attack accuracy. Our findings demonstrate that there is a clear risk of leaking sensitive information from deep learning models. We urge serious consideration to be given to the privacy implications. Our code, demo, and models are available at https://ngoc-nguyen-0.github.io/re-thinking_model_inversion_attacks/