 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-thinking Temporal Search for Long-Form Video Understanding
Apr 03, 2025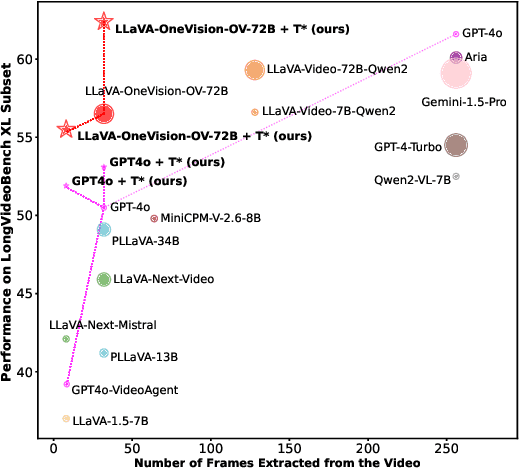
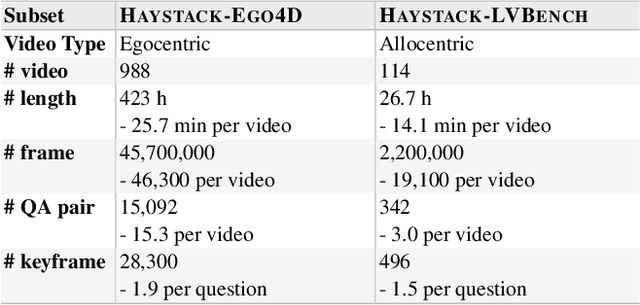
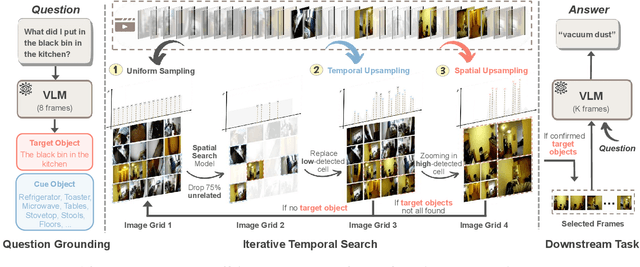
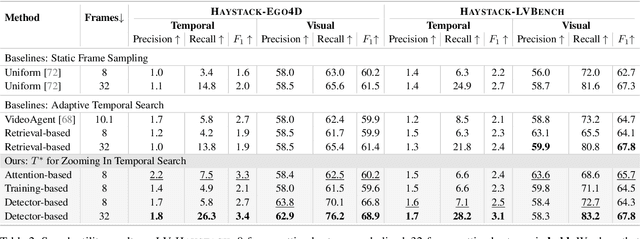
Efficient understanding of long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding, studying a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). In particular, our contributions are two-fold: First, we formulate temporal search as a Long Video Haystack problem, i.e., finding a minimal set of relevant frames (typically one to five) among tens of thousands of frames from real-world long videos given specific queries. To validate our formulation, we create LV-Haystack, the first benchmark containing 3,874 human-annotated instances with fine-grained evaluation metrics for assessing keyframe search quality and computational efficiency. Experimental results on LV-Haystack highlight a significant research gap in temporal search capabilities, with SOTA keyframe selection methods achieving only 2.1% temporal F1 score on the LVBench subset. Next, inspired by visual search in images, we re-think temporal searching and propose a lightweight keyframe searching framework, T*, which casts the expensive temporal search as a spatial search problem. T* leverages superior visual localization capabilities typically used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Our extensive experiments show that when integrated with existing methods, T* significantly improves SOTA long-form video understanding performance. Specifically, under an inference budget of 32 frames, T* improves GPT-4o's performance from 50.5% to 53.1% and LLaVA-OneVision-72B's performance from 56.5% to 62.4% on LongVideoBench XL subset. Our PyTorch code, benchmark dataset and models are included in the Supplementary material.
Logic-in-Frames: Dynamic Keyframe Search via Visual Semantic-Logical Verification for Long Video Understanding
Mar 17, 2025Understanding long video content is a complex endeavor that often relies on densely sampled frame captions or end-to-end feature selectors, yet these techniques commonly overlook the logical relationships between textual queries and visual elements. In practice, computational constraints necessitate coarse frame subsampling, a challenge analogous to ``finding a needle in a haystack.'' To address this issue, we introduce a semantics-driven search framework that reformulates keyframe selection under the paradigm of Visual Semantic-Logical Search. Specifically, we systematically define four fundamental logical dependencies: 1) spatial co-occurrence, 2) temporal proximity, 3) attribute dependency, and 4) causal order. These relations dynamically update frame sampling distributions through an iterative refinement process, enabling context-aware identification of semantically critical frames tailored to specific query requirements. Our method establishes new SOTA performance on the manually annotated benchmark in key-frame selection metrics. Furthermore, when applied to downstream video question-answering tasks, the proposed approach demonstrates the best performance gains over existing methods on LongVideoBench and Video-MME, validating its effectiveness in bridging the logical gap between textual queries and visual-temporal reasoning. The code will be publicly available.
SePer: Measure Retrieval Utility Through The Lens Of Semantic Perplexity Reduction
Mar 05, 2025



Large Language Models (LLMs) have demonstrated improved generation performance by incorporating externally retrieved knowledge, a process known as retrieval-augmented generation (RAG). Despite the potential of this approach, existing studies evaluate RAG effectiveness by 1) assessing retrieval and generation components jointly, which obscures retrieval's distinct contribution, or 2) examining retrievers using traditional metrics such as NDCG, which creates a gap in understanding retrieval's true utility in the overall generation process. To address the above limitations, in this work, we introduce an automatic evaluation method that measures retrieval quality through the lens of information gain within the RAG framework. Specifically, we propose Semantic Perplexity (SePer), a metric that captures the LLM's internal belief about the correctness of the retrieved information. We quantify the utility of retrieval by the extent to which it reduces semantic perplexity post-retrieval. Extensive experiments demonstrate that SePer not only aligns closely with human preferences but also offers a more precise and efficient evaluation of retrieval utility across diverse RAG scenarios.
Improving Gloss-free Sign Language Translation by Reducing Representation Density
May 23, 2024



Gloss-free sign language translation (SLT) aims to develop well-performing SLT systems with no requirement for the costly gloss annotations, but currently still lags behind gloss-based approaches significantly. In this paper, we identify a representation density problem that could be a bottleneck in restricting the performance of gloss-free SLT. Specifically, the representation density problem describes that the visual representations of semantically distinct sign gestures tend to be closely packed together in feature space, which makes gloss-free methods struggle with distinguishing different sign gestures and suffer from a sharp performance drop. To address the representation density problem, we introduce a simple but effective contrastive learning strategy, namely SignCL, which encourages gloss-free models to learn more discriminative feature representation in a self-supervised manner. Our experiments demonstrate that the proposed SignCL can significantly reduce the representation density and improve performance across various translation frameworks. Specifically, SignCL achieves a significant improvement in BLEU score for the Sign Language Transformer and GFSLT-VLP on the CSL-Daily dataset by 39% and 46%, respectively, without any increase of model parameters. Compared to Sign2GPT, a state-of-the-art method based on large-scale pre-trained vision and language models, SignCL achieves better performance with only 35% of its parameters. Implementation and Checkpoints are available at https://github.com/JinhuiYE/SignCL.
GeoDeformer: Geometric Deformable Transformer for Action Recognition
Nov 29, 2023



Vision transformers have recently emerged as an effective alternative to convolutional networks for action recognition. However, vision transformers still struggle with geometric variations prevalent in video data. This paper proposes a novel approach, GeoDeformer, designed to capture the variations inherent in action video by integrating geometric comprehension directly into the ViT architecture. Specifically, at the core of GeoDeformer is the Geometric Deformation Predictor, a module designed to identify and quantify potential spatial and temporal geometric deformations within the given video. Spatial deformations adjust the geometry within individual frames, while temporal deformations capture the cross-frame geometric dynamics, reflecting motion and temporal progression. To demonstrate the effectiveness of our approach, we incorporate it into the established MViTv2 framework, replacing the standard self-attention blocks with GeoDeformer blocks. Our experiments at UCF101, HMDB51, and Mini-K200 achieve significant increases in both Top-1 and Top-5 accuracy, establishing new state-of-the-art results with only a marginal increase in computational cost. Additionally, visualizations affirm that GeoDeformer effectively manifests explicit geometric deformations and minimizes geometric variations. Codes and checkpoints will be released.
Spatial-Temporal Alignment Network for Action Recognition
Aug 19, 2023This paper studies introducing viewpoint invariant feature representations in existing action recognition architecture. Despite significant progress in action recognition, efficiently handling geometric variations in large-scale datasets remains challenging. To tackle this problem, we propose a novel Spatial-Temporal Alignment Network (STAN), which explicitly learns geometric invariant representations for action recognition. Notably, the STAN model is light-weighted and generic, which could be plugged into existing action recognition models (e.g., MViTv2) with a low extra computational cost. We test our STAN model on widely-used datasets like UCF101 and HMDB51. The experimental results show that the STAN model can consistently improve the state-of-the-art models in action recognition tasks in trained-from-scratch settings.
Cross-modality Data Augmentation for End-to-End Sign Language Translation
May 22, 2023



End-to-end sign language translation (SLT) aims to convert sign language videos into spoken language texts directly without intermediate representations. It has been a challenging task due to the modality gap between sign videos and texts and the data scarcity of labeled data. To tackle these challenges, we propose a novel Cross-modality Data Augmentation (XmDA) framework to transfer the powerful gloss-to-text translation capabilities to end-to-end sign language translation (i.e. video-to-text) by exploiting pseudo gloss-text pairs from the sign gloss translation model. Specifically, XmDA consists of two key components, namely, cross-modality mix-up and cross-modality knowledge distillation. The former explicitly encourages the alignment between sign video features and gloss embeddings to bridge the modality gap. The latter utilizes the generation knowledge from gloss-to-text teacher models to guide the spoken language text generation. Experimental results on two widely used SLT datasets, i.e., PHOENIX-2014T and CSL-Daily, demonstrate that the proposed XmDA framework significantly and consistently outperforms the baseline models. Extensive analyses confirm our claim that XmDA enhances spoken language text generation by reducing the representation distance between videos and texts, as well as improving the processing of low-frequency words and long sentences.
Scaling Back-Translation with Domain Text Generation for Sign Language Gloss Translation
Oct 13, 2022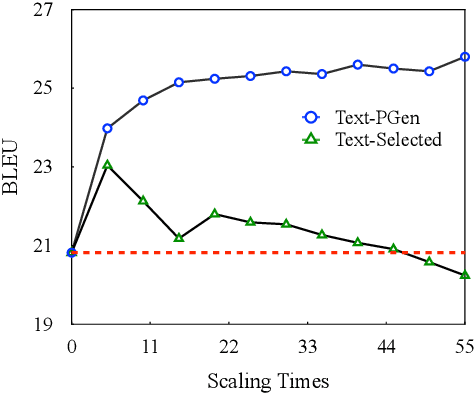

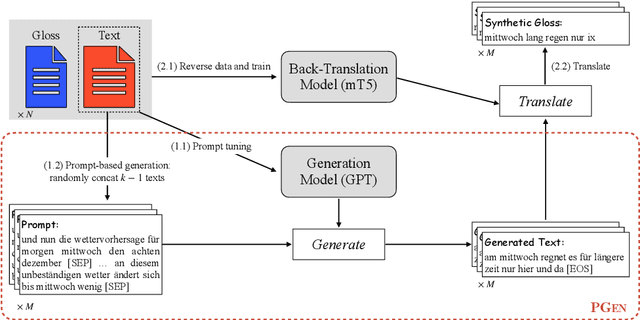

Sign language gloss translation aims to translate the sign glosses into spoken language texts, which is challenging due to the scarcity of labeled gloss-text parallel data. Back translation (BT), which generates pseudo-parallel data by translating in-domain spoken language texts into sign glosses, has been applied to alleviate the data scarcity problem. However, the lack of large-scale high-quality domain spoken language text data limits the effect of BT. In this paper, to overcome the limitation, we propose a Prompt based domain text Generation (PGEN) approach to produce the large-scale in-domain spoken language text data. Specifically, PGEN randomly concatenates sentences from the original in-domain spoken language text data as prompts to induce a pre-trained language model (i.e., GPT-2) to generate spoken language texts in a similar style. Experimental results on three benchmarks of sign language gloss translation in varied languages demonstrate that BT with spoken language texts generated by PGEN significantly outperforms the compared methods. In addition, as the scale of spoken language texts generated by PGEN increases, the BT technique can achieve further improvements, demonstrating the effectiveness of our approach. We release the code and data for facilitating future research in this field.