 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Brain-inspired Embodied Intelligence for Fluid and Fast Reflexive Robotics Control
Jan 21, 2026Recent advances in embodied intelligence have leveraged massive scaling of data and model parameters to master natural-language command following and multi-task control. In contrast, biological systems demonstrate an innate ability to acquire skills rapidly from sparse experience. Crucially, current robotic policies struggle to replicate the dynamic stability, reflexive responsiveness, and temporal memory inherent in biological motion. Here we present Neuromorphic Vision-Language-Action (NeuroVLA), a framework that mimics the structural organization of the bio-nervous system between the cortex, cerebellum, and spinal cord. We adopt a system-level bio-inspired design: a high-level model plans goals, an adaptive cerebellum module stabilizes motion using high-frequency sensors feedback, and a bio-inspired spinal layer executes lightning-fast actions generation. NeuroVLA represents the first deployment of a neuromorphic VLA on physical robotics, achieving state-of-the-art performance. We observe the emergence of biological motor characteristics without additional data or special guidance: it stops the shaking in robotic arms, saves significant energy(only 0.4w on Neuromorphic Processor), shows temporal memory ability and triggers safety reflexes in less than 20 milliseconds.
Beyond Boundaries: Leveraging Vision Foundation Models for Source-Free Object Detection
Nov 10, 2025Source-Free Object Detection (SFOD) aims to adapt a source-pretrained object detector to a target domain without access to source data. However, existing SFOD methods predominantly rely on internal knowledge from the source model, which limits their capacity to generalize across domains and often results in biased pseudo-labels, thereby hindering both transferability and discriminability. In contrast, Vision Foundation Models (VFMs), pretrained on massive and diverse data, exhibit strong perception capabilities and broad generalization, yet their potential remains largely untapped in the SFOD setting. In this paper, we propose a novel SFOD framework that leverages VFMs as external knowledge sources to jointly enhance feature alignment and label quality. Specifically, we design three VFM-based modules: (1) Patch-weighted Global Feature Alignment (PGFA) distills global features from VFMs using patch-similarity-based weighting to enhance global feature transferability; (2) Prototype-based Instance Feature Alignment (PIFA) performs instance-level contrastive learning guided by momentum-updated VFM prototypes; and (3) Dual-source Enhanced Pseudo-label Fusion (DEPF) fuses predictions from detection VFMs and teacher models via an entropy-aware strategy to yield more reliable supervision. Extensive experiments on six benchmarks demonstrate that our method achieves state-of-the-art SFOD performance, validating the effectiveness of integrating VFMs to simultaneously improve transferability and discriminability.
See&Trek: Training-Free Spatial Prompting for Multimodal Large Language Model
Sep 19, 2025We introduce SEE&TREK, the first training-free prompting framework tailored to enhance the spatial understanding of Multimodal Large Language Models (MLLMS) under vision-only constraints. While prior efforts have incorporated modalities like depth or point clouds to improve spatial reasoning, purely visualspatial understanding remains underexplored. SEE&TREK addresses this gap by focusing on two core principles: increasing visual diversity and motion reconstruction. For visual diversity, we conduct Maximum Semantic Richness Sampling, which employs an off-the-shell perception model to extract semantically rich keyframes that capture scene structure. For motion reconstruction, we simulate visual trajectories and encode relative spatial positions into keyframes to preserve both spatial relations and temporal coherence. Our method is training&GPU-free, requiring only a single forward pass, and can be seamlessly integrated into existing MLLM'S. Extensive experiments on the VSI-B ENCH and STI-B ENCH show that S EE &T REK consistently boosts various MLLM S performance across diverse spatial reasoning tasks with the most +3.5% improvement, offering a promising path toward stronger spatial intelligence.
VSI: Visual Subtitle Integration for Keyframe Selection to enhance Long Video Understanding
Aug 09, 2025Long video understanding presents a significant challenge to multimodal large language models (MLLMs) primarily due to the immense data scale. A critical and widely adopted strategy for making this task computationally tractable is keyframe retrieval, which seeks to identify a sparse set of video frames that are most salient to a given textual query. However, the efficacy of this approach is hindered by weak multimodal alignment between textual queries and visual content and fails to capture the complex temporal semantic information required for precise reasoning. To address this, we propose Visual-Subtitle Integeration(VSI), a multimodal keyframe search method that integrates subtitles, timestamps, and scene boundaries into a unified multimodal search process. The proposed method captures the visual information of video frames as well as the complementary textual information through a dual-stream search mechanism by Video Search Stream as well as Subtitle Match Stream, respectively, and improves the keyframe search accuracy through the interaction of the two search streams. Experimental results show that VSI achieve 40.00% key frame localization accuracy on the text-relevant subset of LongVideoBench and 68.48% accuracy on downstream long Video-QA tasks, surpassing competitive baselines by 20.35% and 15.79%, respectively. Furthermore, on the LongVideoBench, VSI achieved state-of-the-art(SOTA) in medium-to-long video-QA tasks, demonstrating the robustness and generalizability of the proposed multimodal search strategy.
Logic-in-Frames: Dynamic Keyframe Search via Visual Semantic-Logical Verification for Long Video Understanding
Mar 17, 2025Understanding long video content is a complex endeavor that often relies on densely sampled frame captions or end-to-end feature selectors, yet these techniques commonly overlook the logical relationships between textual queries and visual elements. In practice, computational constraints necessitate coarse frame subsampling, a challenge analogous to ``finding a needle in a haystack.'' To address this issue, we introduce a semantics-driven search framework that reformulates keyframe selection under the paradigm of Visual Semantic-Logical Search. Specifically, we systematically define four fundamental logical dependencies: 1) spatial co-occurrence, 2) temporal proximity, 3) attribute dependency, and 4) causal order. These relations dynamically update frame sampling distributions through an iterative refinement process, enabling context-aware identification of semantically critical frames tailored to specific query requirements. Our method establishes new SOTA performance on the manually annotated benchmark in key-frame selection metrics. Furthermore, when applied to downstream video question-answering tasks, the proposed approach demonstrates the best performance gains over existing methods on LongVideoBench and Video-MME, validating its effectiveness in bridging the logical gap between textual queries and visual-temporal reasoning. The code will be publicly available.
SEE: See Everything Every Time -- Adaptive Brightness Adjustment for Broad Light Range Images via Events
Feb 28, 2025Event cameras, with a high dynamic range exceeding $120dB$, significantly outperform traditional embedded cameras, robustly recording detailed changing information under various lighting conditions, including both low- and high-light situations. However, recent research on utilizing event data has primarily focused on low-light image enhancement, neglecting image enhancement and brightness adjustment across a broader range of lighting conditions, such as normal or high illumination. Based on this, we propose a novel research question: how to employ events to enhance and adaptively adjust the brightness of images captured under broad lighting conditions? To investigate this question, we first collected a new dataset, SEE-600K, consisting of 610,126 images and corresponding events across 202 scenarios, each featuring an average of four lighting conditions with over a 1000-fold variation in illumination. Subsequently, we propose a framework that effectively utilizes events to smoothly adjust image brightness through the use of prompts. Our framework captures color through sensor patterns, uses cross-attention to model events as a brightness dictionary, and adjusts the image's dynamic range to form a broad light-range representation (BLR), which is then decoded at the pixel level based on the brightness prompt. Experimental results demonstrate that our method not only performs well on the low-light enhancement dataset but also shows robust performance on broader light-range image enhancement using the SEE-600K dataset. Additionally, our approach enables pixel-level brightness adjustment, providing flexibility for post-processing and inspiring more imaging applications. The dataset and source code are publicly available at:https://github.com/yunfanLu/SEE.
A Survey of fMRI to Image Reconstruction
Feb 24, 2025Functional magnetic resonance imaging (fMRI) based image reconstruction plays a pivotal role in decoding human perception, with applications in neuroscience and brain-computer interfaces. While recent advancements in deep learning and large-scale datasets have driven progress, challenges such as data scarcity, cross-subject variability, and low semantic consistency persist. To address these issues, we introduce the concept of fMRI-to-Image Learning (fMRI2Image) and present the first systematic review in this field. This review highlights key challenges, categorizes methodologies such as fMRI signal encoding, feature mapping, and image generator. Finally, promising research directions are proposed to advance this emerging frontier, providing a reference for future studies.
SpGesture: Source-Free Domain-adaptive sEMG-based Gesture Recognition with Jaccard Attentive Spiking Neural Network
May 23, 2024



Surface electromyography (sEMG) based gesture recognition offers a natural and intuitive interaction modality for wearable devices. Despite significant advancements in sEMG-based gesture-recognition models, existing methods often suffer from high computational latency and increased energy consumption. Additionally, the inherent instability of sEMG signals, combined with their sensitivity to distribution shifts in real-world settings, compromises model robustness. To tackle these challenges, we propose a novel SpGesture framework based on Spiking Neural Networks, which possesses several unique merits compared with existing methods: (1) Robustness: By utilizing membrane potential as a memory list, we pioneer the introduction of Source-Free Domain Adaptation into SNN for the first time. This enables SpGesture to mitigate the accuracy degradation caused by distribution shifts. (2) High Accuracy: With a novel Spiking Jaccard Attention, SpGesture enhances the SNNs' ability to represent sEMG features, leading to a notable rise in system accuracy. To validate SpGesture's performance, we collected a new sEMG gesture dataset which has different forearm postures, where SpGesture achieved the highest accuracy among the baselines ($89.26\%$). Moreover, the actual deployment on the CPU demonstrated a system latency below 100ms, well within real-time requirements. This impressive performance showcases SpGesture's potential to enhance the applicability of sEMG in real-world scenarios. The code is available at https://anonymous.4open.science/r/SpGesture.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024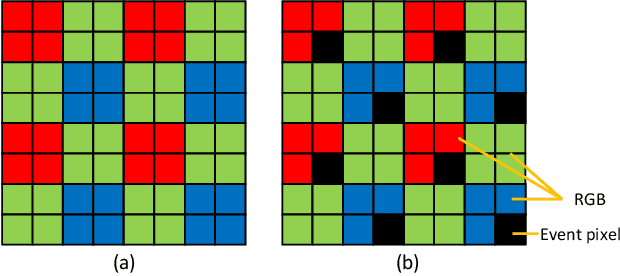
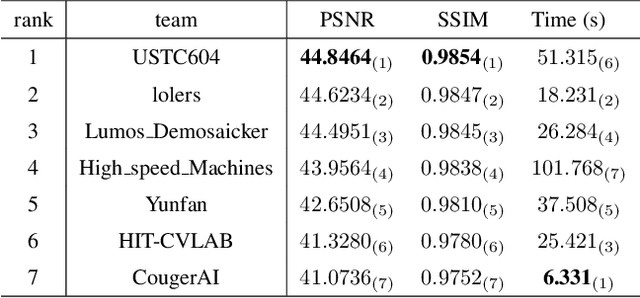
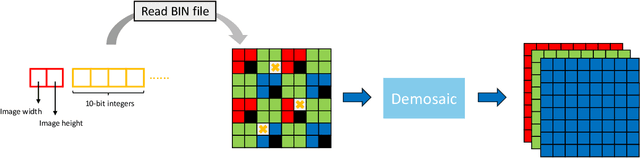

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Revisiting Noise Resilience Strategies in Gesture Recognition: Short-Term Enhancement in Surface Electromyographic Signal Analysis
Apr 17, 2024Gesture recognition based on surface electromyography (sEMG) has been gaining importance in many 3D Interactive Scenes. However, sEMG is easily influenced by various forms of noise in real-world environments, leading to challenges in providing long-term stable interactions through sEMG. Existing methods often struggle to enhance model noise resilience through various predefined data augmentation techniques. In this work, we revisit the problem from a short term enhancement perspective to improve precision and robustness against various common noisy scenarios with learnable denoise using sEMG intrinsic pattern information and sliding-window attention. We propose a Short Term Enhancement Module(STEM) which can be easily integrated with various models. STEM offers several benefits: 1) Learnable denoise, enabling noise reduction without manual data augmentation; 2) Scalability, adaptable to various models; and 3) Cost-effectiveness, achieving short-term enhancement through minimal weight-sharing in an efficient attention mechanism. In particular, we incorporate STEM into a transformer, creating the Short Term Enhanced Transformer (STET). Compared with best-competing approaches, the impact of noise on STET is reduced by more than 20%. We also report promising results on both classification and regression datasets and demonstrate that STEM generalizes across different gesture recognition tasks.