 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Light: A Large-Scale Aerial Dataset for Urban Scene Reconstruction Under Varying Illumination
Dec 16, 2025Recent advances in Neural Radiance Fields and 3D Gaussian Splatting have demonstrated strong potential for large-scale UAV-based 3D reconstruction tasks by fitting the appearance of images. However, real-world large-scale captures are often based on multi-temporal data capture, where illumination inconsistencies across different times of day can significantly lead to color artifacts, geometric inaccuracies, and inconsistent appearance. Due to the lack of UAV datasets that systematically capture the same areas under varying illumination conditions, this challenge remains largely underexplored. To fill this gap, we introduceSkyLume, a large-scale, real-world UAV dataset specifically designed for studying illumination robust 3D reconstruction in urban scene modeling: (1) We collect data from 10 urban regions data comprising more than 100k high resolution UAV images (four oblique views and nadir), where each region is captured at three periods of the day to systematically isolate illumination changes. (2) To support precise evaluation of geometry and appearance, we provide per-scene LiDAR scans and accurate 3D ground-truth for assessing depth, surface normals, and reconstruction quality under varying illumination. (3) For the inverse rendering task, we introduce the Temporal Consistency Coefficient (TCC), a metric that measuress cross-time albedo stability and directly evaluates the robustness of the disentanglement of light and material. We aim for this resource to serve as a foundation that advances research and real-world evaluation in large-scale inverse rendering, geometry reconstruction, and novel view synthesis.
From Events to Clarity: The Event-Guided Diffusion Framework for Dehazing
Nov 14, 2025Clear imaging under hazy conditions is a critical task. Prior-based and neural methods have improved results. However, they operate on RGB frames, which suffer from limited dynamic range. Therefore, dehazing remains ill-posed and can erase structure and illumination details. To address this, we use event cameras for dehazing for the \textbf{first time}. Event cameras offer much higher HDR ($120 dBvs.60 dB$) and microsecond latency, therefore they suit hazy scenes. In practice, transferring HDR cues from events to frames is hard because real paired data are scarce. To tackle this, we propose an event-guided diffusion model that utilizes the strong generative priors of diffusion models to reconstruct clear images from hazy inputs by effectively transferring HDR information from events. Specifically, we design an event-guided module that maps sparse HDR event features, \textit{e.g.,} edges, corners, into the diffusion latent space. This clear conditioning provides precise structural guidance during generation, improves visual realism, and reduces semantic drift. For real-world evaluation, we collect a drone dataset in heavy haze (AQI = 341) with synchronized RGB and event sensors. Experiments on two benchmarks and our dataset achieve state-of-the-art results.
Open-vocabulary Mobile Manipulation in Unseen Dynamic Environments with 3D Semantic Maps
Jun 26, 2024



Open-Vocabulary Mobile Manipulation (OVMM) is a crucial capability for autonomous robots, especially when faced with the challenges posed by unknown and dynamic environments. This task requires robots to explore and build a semantic understanding of their surroundings, generate feasible plans to achieve manipulation goals, adapt to environmental changes, and comprehend natural language instructions from humans. To address these challenges, we propose a novel framework that leverages the zero-shot detection and grounded recognition capabilities of pretraining visual-language models (VLMs) combined with dense 3D entity reconstruction to build 3D semantic maps. Additionally, we utilize large language models (LLMs) for spatial region abstraction and online planning, incorporating human instructions and spatial semantic context. We have built a 10-DoF mobile manipulation robotic platform JSR-1 and demonstrated in real-world robot experiments that our proposed framework can effectively capture spatial semantics and process natural language user instructions for zero-shot OVMM tasks under dynamic environment settings, with an overall navigation and task success rate of 80.95% and 73.33% over 105 episodes, and better SFT and SPL by 157.18% and 19.53% respectively compared to the baseline. Furthermore, the framework is capable of replanning towards the next most probable candidate location based on the spatial semantic context derived from the 3D semantic map when initial plans fail, keeping an average success rate of 76.67%.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024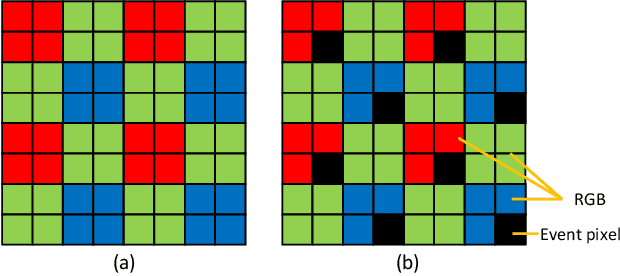
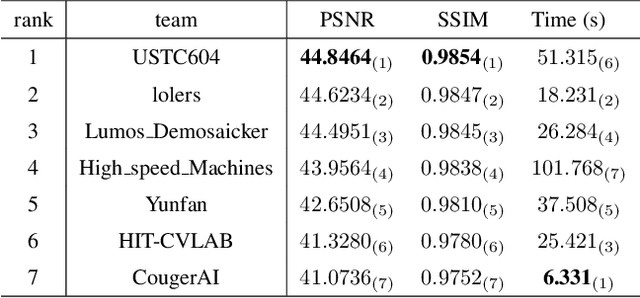

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
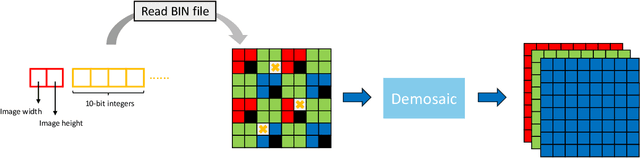
Event Camera Demosaicing via Swin Transformer and Pixel-focus Loss
Apr 03, 2024Recent research has highlighted improvements in high-quality imaging guided by event cameras, with most of these efforts concentrating on the RGB domain. However, these advancements frequently neglect the unique challenges introduced by the inherent flaws in the sensor design of event cameras in the RAW domain. Specifically, this sensor design results in the partial loss of pixel values, posing new challenges for RAW domain processes like demosaicing. The challenge intensifies as most research in the RAW domain is based on the premise that each pixel contains a value, making the straightforward adaptation of these methods to event camera demosaicing problematic. To end this, we present a Swin-Transformer-based backbone and a pixel-focus loss function for demosaicing with missing pixel values in RAW domain processing. Our core motivation is to refine a general and widely applicable foundational model from the RGB domain for RAW domain processing, thereby broadening the model's applicability within the entire imaging process. Our method harnesses multi-scale processing and space-to-depth techniques to ensure efficiency and reduce computing complexity. We also proposed the Pixel-focus Loss function for network fine-tuning to improve network convergence based on our discovery of a long-tailed distribution in training loss. Our method has undergone validation on the MIPI Demosaic Challenge dataset, with subsequent analytical experimentation confirming its efficacy. All code and trained models are released here: https://github.com/yunfanLu/ev-demosaic