 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

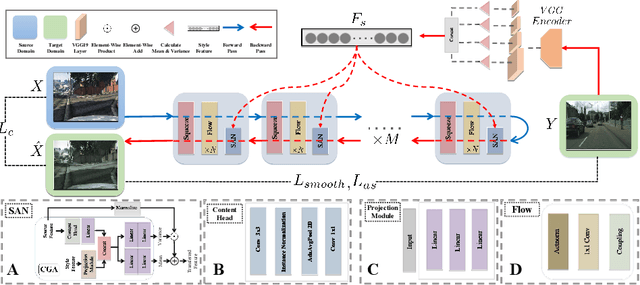

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.
Learning Efficient Convolutional Networks through Irregular Convolutional Kernels
Sep 29, 2019

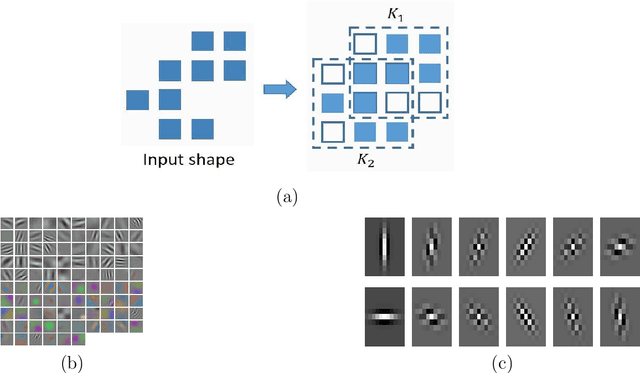

As deep neural networks are increasingly used in applications suited for low-power devices, a fundamental dilemma becomes apparent: the trend is to grow models to absorb increasing data that gives rise to memory intensive; however low-power devices are designed with very limited memory that can not store large models. Parameters pruning is critical for deep model deployment on low-power devices. Existing efforts mainly focus on designing highly efficient structures or pruning redundant connections for networks. They are usually sensitive to the tasks or relay on dedicated and expensive hashing storage strategies. In this work, we introduce a novel approach for achieving a lightweight model from the views of reconstructing the structure of convolutional kernels and efficient storage. Our approach transforms a traditional square convolution kernel to line segments, and automatically learn a proper strategy for equipping these line segments to model diverse features. The experimental results indicate that our approach can massively reduce the number of parameters (pruned 69% on DenseNet-40) and calculations (pruned 59% on DenseNet-40) while maintaining acceptable performance (only lose less than 2% accuracy).
Irregular Convolutional Neural Networks
Jun 24, 2017
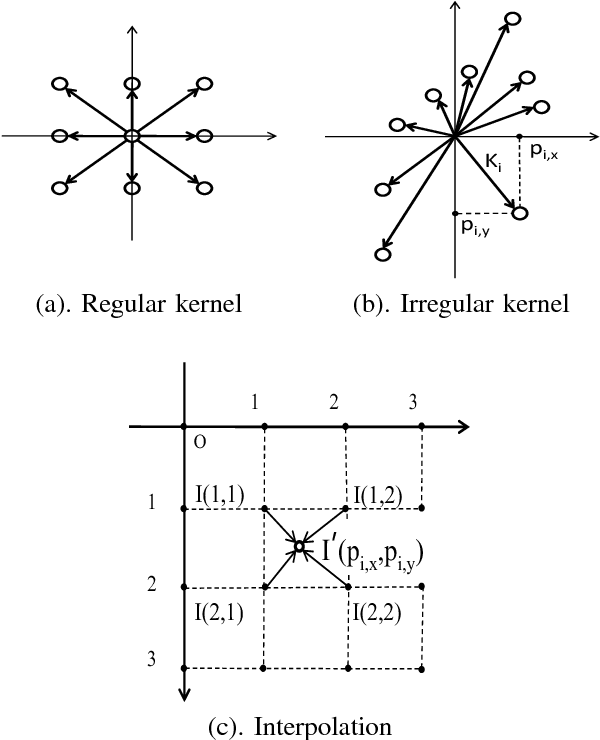


Convolutional kernels are basic and vital components of deep Convolutional Neural Networks (CNN). In this paper, we equip convolutional kernels with shape attributes to generate the deep Irregular Convolutional Neural Networks (ICNN). Compared to traditional CNN applying regular convolutional kernels like ${3\times3}$, our approach trains irregular kernel shapes to better fit the geometric variations of input features. In other words, shapes are learnable parameters in addition to weights. The kernel shapes and weights are learned simultaneously during end-to-end training with the standard back-propagation algorithm. Experiments for semantic segmentation are implemented to validate the effectiveness of our proposed ICNN.