 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolExpander: Extending the Frontiers of Tool-Using Reinforcement Learning to Weak LLMs
Oct 09, 2025Training Large Language Models (LLMs) with Group Relative Policy Optimization (GRPO) encounters a significant challenge: models often fail to produce accurate responses, particularly in small-scale architectures. This limitation not only diminishes performance improvements and undermines the potential of GRPO but also frequently leads to mid-training collapse, adversely affecting stability and final efficacy. To address these issues, we propose ToolExpander, a novel framework that advances tool-oriented reinforcement learning for resource-constrained LLMs through two key innovations:(1) Dynamic Multi-Round Hard Sampling, which dynamically substitutes challenging samples(those without correct outputs over 10 rollouts) with high-quality few-shot demonstrations during training, coupled with an exponential learning rate decay strategy to mitigate oscillations;(2) Self-Exemplifying Thinking, an enhanced GRPO framework that eliminates KL divergence and incorporates adjusted clipping coefficients, encouraging models to autonomously generate and analyze few-shot examples via a minimal additional reward (0.01).Experimental results demonstrate that ToolExpander significantly enhances tool-using capabilities in LLMs, especially in weaker small-scale models, improving both training stability and overall performance.
Quantum Complex-Valued Self-Attention Model
Mar 24, 2025



The self-attention mechanism has revolutionized classical machine learning, yet its quantum counterpart remains underexplored in fully harnessing the representational power of quantum states. Current quantum self-attention models exhibit a critical limitation by neglecting the indispensable phase information inherent in quantum systems when compressing attention weights into real-valued overlaps. To address this fundamental gap, we propose the Quantum Complex-Valued Self-Attention Model (QCSAM), the first framework that explicitly leverages complex-valued similarities between quantum states to capture both amplitude and phase relationships. Simultaneously, we enhance the standard Linear Combination of Unitaries (LCUs) method by introducing a Complex LCUs (CLCUs) framework that natively supports complex-valued coefficients. This framework enables the weighting of corresponding quantum values using fixed quantum complex self-attention weights, while also supporting trainable complex-valued parameters for value aggregation and quantum multi-head attention. Experimental evaluations on MNIST and Fashion-MNIST demonstrate our model's superiority over recent quantum self-attention architectures including QKSAN, QSAN, and GQHAN, with multi-head configurations showing consistent advantages over single-head variants. We systematically evaluate model scalability through qubit configurations ranging from 3 to 8 qubits and multi-class classification tasks spanning 2 to 4 categories. Through comprehensive ablation studies, we establish the critical advantage of complex-valued quantum attention weights over real-valued alternatives.
VMTS: Vision-Assisted Teacher-Student Reinforcement Learning for Multi-Terrain Locomotion in Bipedal Robots
Mar 10, 2025Bipedal robots, due to their anthropomorphic design, offer substantial potential across various applications, yet their control is hindered by the complexity of their structure. Currently, most research focuses on proprioception-based methods, which lack the capability to overcome complex terrain. While visual perception is vital for operation in human-centric environments, its integration complicates control further. Recent reinforcement learning (RL) approaches have shown promise in enhancing legged robot locomotion, particularly with proprioception-based methods. However, terrain adaptability, especially for bipedal robots, remains a significant challenge, with most research focusing on flat-terrain scenarios. In this paper, we introduce a novel mixture of experts teacher-student network RL strategy, which enhances the performance of teacher-student policies based on visual inputs through a simple yet effective approach. Our method combines terrain selection strategies with the teacher policy, resulting in superior performance compared to traditional models. Additionally, we introduce an alignment loss between the teacher and student networks, rather than enforcing strict similarity, to improve the student's ability to navigate diverse terrains. We validate our approach experimentally on the Limx Dynamic P1 bipedal robot, demonstrating its feasibility and robustness across multiple terrain types.
Contact Compliance Visuo-Proprioceptive Policy for Contact-Rich Manipulation with Cost-Efficient Haptic Hand-Arm Teleoperation System
Sep 22, 2024



Learning robot manipulation skills in real-world environments is extremely challenging. Robots learning manipulation skills in real-world environments is extremely challenging. Recent research on imitation learning and visuomotor policies has significantly enhanced the ability of robots to perform manipulation tasks. In this paper, we propose Admit Policy, a visuo-proprioceptive imitation learning framework with force compliance, designed to reduce contact force fluctuations during robot execution of contact-rich manipulation tasks. This framework also includes a hand-arm teleoperation system with vibrotactile feedback for efficient data collection. Our framework utilizes RGB images, robot joint positions, and contact forces as observations and leverages a consistency-constrained teacher-student probabilistic diffusion model to generate future trajectories for end-effector positions and contact forces. An admittance model is then employed to track these trajectories, enabling effective force-position control across various tasks.We validated our framework on five challenging contact-rich manipulation tasks. Among these tasks, while improving success rates, our approach most significantly reduced the mean contact force required to complete the tasks by up to 53.92% and decreased the standard deviation of contact force fluctuations by 76.51% compared to imitation learning algorithms without dynamic contact force prediction and tracking.
OTO Planner: An Efficient Only Travelling Once Exploration Planner for Complex and Unknown Environments
Jun 11, 2024



Autonomous exploration in complex and cluttered environments is essential for various applications. However, there are many challenges due to the lack of global heuristic information. Existing exploration methods suffer from the repeated paths and considerable computational resource requirement in large-scale environments. To address the above issues, this letter proposes an efficient exploration planner that reduces repeated paths in complex environments, hence it is called "Only Travelling Once Planner". OTO Planner includes fast frontier updating, viewpoint evaluation and viewpoint refinement. A selective frontier updating mechanism is designed, saving a large amount of computational resources. In addition, a novel viewpoint evaluation system is devised to reduce the repeated paths utilizing the enclosed sub-region detection. Besides, a viewpoint refinement approach is raised to concentrate the redundant viewpoints, leading to smoother paths. We conduct extensive simulation and real-world experiments to validate the proposed method. Compared to the state-of-the-art approach, the proposed method reduces the exploration time and movement distance by 10%-20% and improves the speed of frontier detection by 6-9 times.
Quantum Mixed-State Self-Attention Network
Mar 05, 2024



The rapid advancement of quantum computing has increasingly highlighted its potential in the realm of machine learning, particularly in the context of natural language processing (NLP) tasks. Quantum machine learning (QML) leverages the unique capabilities of quantum computing to offer novel perspectives and methodologies for complex data processing and pattern recognition challenges. This paper introduces a novel Quantum Mixed-State Attention Network (QMSAN), which integrates the principles of quantum computing with classical machine learning algorithms, especially self-attention networks, to enhance the efficiency and effectiveness in handling NLP tasks. QMSAN model employs a quantum attention mechanism based on mixed states, enabling efficient direct estimation of similarity between queries and keys within the quantum domain, leading to more effective attention weight acquisition. Additionally, we propose an innovative quantum positional encoding scheme, implemented through fixed quantum gates within the quantum circuit, to enhance the model's accuracy. Experimental validation on various datasets demonstrates that QMSAN model outperforms existing quantum and classical models in text classification, achieving significant performance improvements. QMSAN model not only significantly reduces the number of parameters but also exceeds classical self-attention networks in performance, showcasing its strong capability in data representation and information extraction. Furthermore, our study investigates the model's robustness in different quantum noise environments, showing that QMSAN possesses commendable robustness to low noise.
Improvements on Recommender System based on Mathematical Principles
Apr 26, 2023In this article, we will research the Recommender System's implementation about how it works and the algorithms used. We will explain the Recommender System's algorithms based on mathematical principles, and find feasible methods for improvements. The algorithms based on probability have its significance in Recommender System, we will describe how they help to increase the accuracy and speed of the algorithms. Both the weakness and the strength of two different mathematical distance used to describe the similarity will be detailed illustrated in this article.
Explainable Enterprise Credit Rating via Deep Feature Crossing Network
May 22, 2021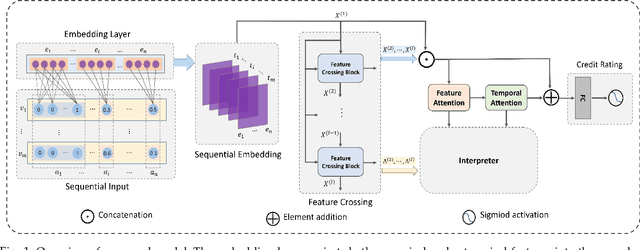
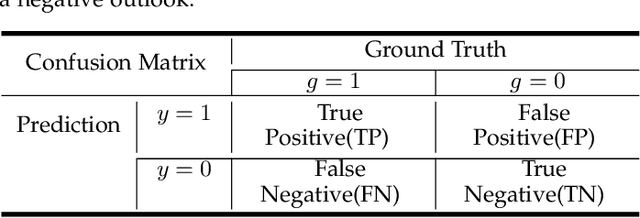
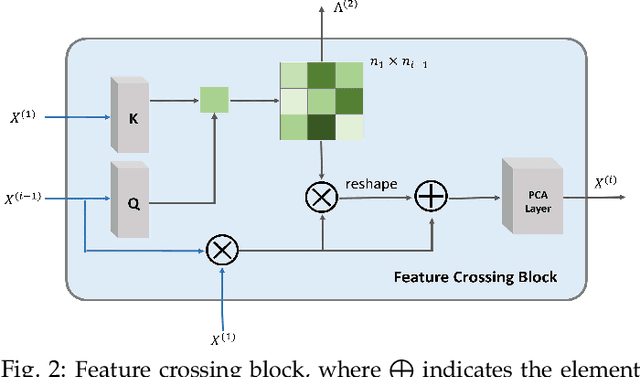
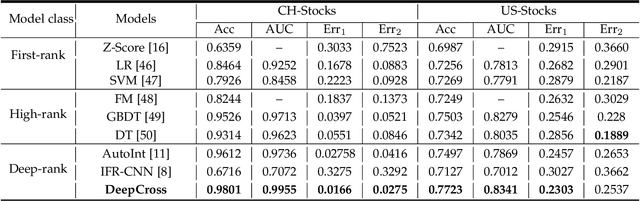
Due to the powerful learning ability on high-rank and non-linear features, deep neural networks (DNNs) are being applied to data mining and machine learning in various fields, and exhibit higher discrimination performance than conventional methods. However, the applications based on DNNs are rare in enterprise credit rating tasks because most of DNNs employ the "end-to-end" learning paradigm, which outputs the high-rank representations of objects and predictive results without any explanations. Thus, users in the financial industry cannot understand how these high-rank representations are generated, what do they mean and what relations exist with the raw inputs. Then users cannot determine whether the predictions provided by DNNs are reliable, and not trust the predictions providing by such "black box" models. Therefore, in this paper, we propose a novel network to explicitly model the enterprise credit rating problem using DNNs and attention mechanisms. The proposed model realizes explainable enterprise credit ratings. Experimental results obtained on real-world enterprise datasets verify that the proposed approach achieves higher performance than conventional methods, and provides insights into individual rating results and the reliability of model training.