 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-variable Quantum Diffusion Model for State Generation and Restoration
Jun 24, 2025The generation and preservation of complex quantum states against environmental noise are paramount challenges in advancing continuous-variable (CV) quantum information processing. This paper introduces a novel framework based on continuous-variable quantum diffusion principles, synergizing them with CV quantum neural networks (CVQNNs) to address these dual challenges. For the task of state generation, our Continuous-Variable Quantum Diffusion Generative model (CVQD-G) employs a physically driven forward diffusion process using a thermal loss channel, which is then inverted by a learnable, parameter-efficient backward denoising process based on a CVQNN with time-embedding. This framework's capability is further extended for state recovery by the Continuous-Variable Quantum Diffusion Restoration model (CVQD-R), a specialized variant designed to restore quantum states, particularly coherent states with unknown parameters, from thermal degradation. Extensive numerical simulations validate these dual capabilities, demonstrating the high-fidelity generation of diverse Gaussian (coherent, squeezed) and non-Gaussian (Fock, cat) states, typically with fidelities exceeding 99%, and confirming the model's ability to robustly restore corrupted states. Furthermore, a comprehensive complexity analysis reveals favorable training and inference costs, highlighting the framework's efficiency, scalability, and its potential as a robust tool for quantum state engineering and noise mitigation in realistic CV quantum systems.
Overcoming Dimensional Factorization Limits in Discrete Diffusion Models through Quantum Joint Distribution Learning
May 08, 2025This study explores quantum-enhanced discrete diffusion models to overcome classical limitations in learning high-dimensional distributions. We rigorously prove that classical discrete diffusion models, which calculate per-dimension transition probabilities to avoid exponential computational cost, exhibit worst-case linear scaling of Kullback-Leibler (KL) divergence with data dimension. To address this, we propose a Quantum Discrete Denoising Diffusion Probabilistic Model (QD3PM), which enables joint probability learning through diffusion and denoising in exponentially large Hilbert spaces. By deriving posterior states through quantum Bayes' theorem, similar to the crucial role of posterior probabilities in classical diffusion models, and by learning the joint probability, we establish a solid theoretical foundation for quantum-enhanced diffusion models. For denoising, we design a quantum circuit using temporal information for parameter sharing and learnable classical-data-controlled rotations for encoding. Exploiting joint distribution learning, our approach enables single-step sampling from pure noise, eliminating iterative requirements of existing models. Simulations demonstrate the proposed model's superior accuracy in modeling complex distributions compared to factorization methods. Hence, this paper establishes a new theoretical paradigm in generative models by leveraging the quantum advantage in joint distribution learning.
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Jun 20, 2024



In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
Quantum Mixed-State Self-Attention Network
Mar 05, 2024



The rapid advancement of quantum computing has increasingly highlighted its potential in the realm of machine learning, particularly in the context of natural language processing (NLP) tasks. Quantum machine learning (QML) leverages the unique capabilities of quantum computing to offer novel perspectives and methodologies for complex data processing and pattern recognition challenges. This paper introduces a novel Quantum Mixed-State Attention Network (QMSAN), which integrates the principles of quantum computing with classical machine learning algorithms, especially self-attention networks, to enhance the efficiency and effectiveness in handling NLP tasks. QMSAN model employs a quantum attention mechanism based on mixed states, enabling efficient direct estimation of similarity between queries and keys within the quantum domain, leading to more effective attention weight acquisition. Additionally, we propose an innovative quantum positional encoding scheme, implemented through fixed quantum gates within the quantum circuit, to enhance the model's accuracy. Experimental validation on various datasets demonstrates that QMSAN model outperforms existing quantum and classical models in text classification, achieving significant performance improvements. QMSAN model not only significantly reduces the number of parameters but also exceeds classical self-attention networks in performance, showcasing its strong capability in data representation and information extraction. Furthermore, our study investigates the model's robustness in different quantum noise environments, showing that QMSAN possesses commendable robustness to low noise.
Quantum Generative Diffusion Model
Jan 13, 2024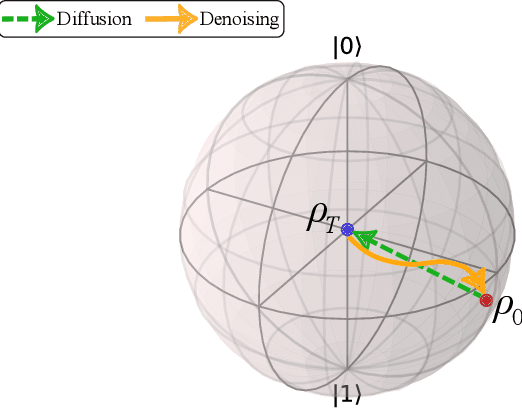
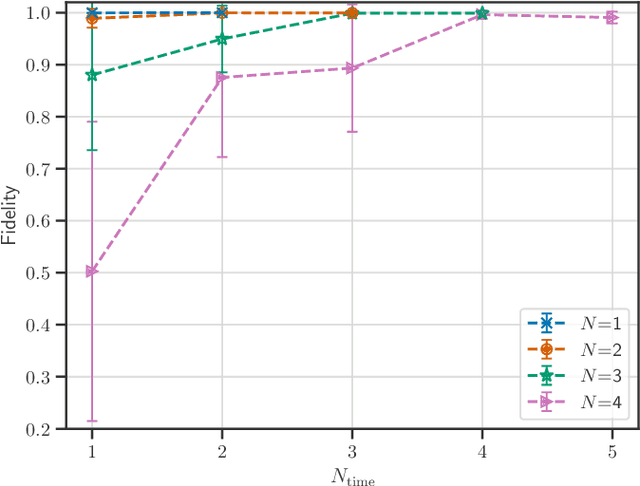
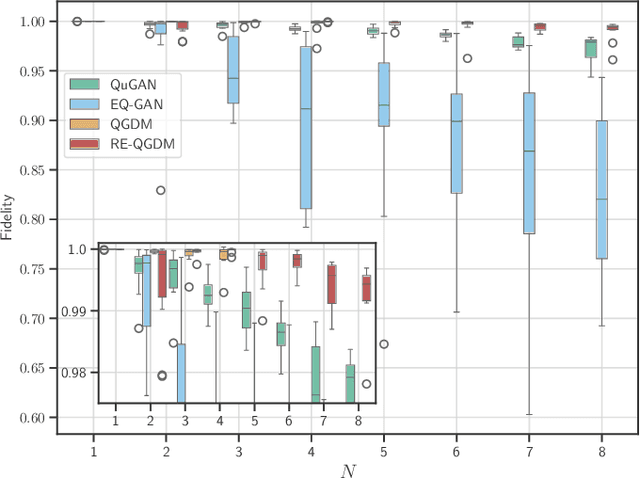
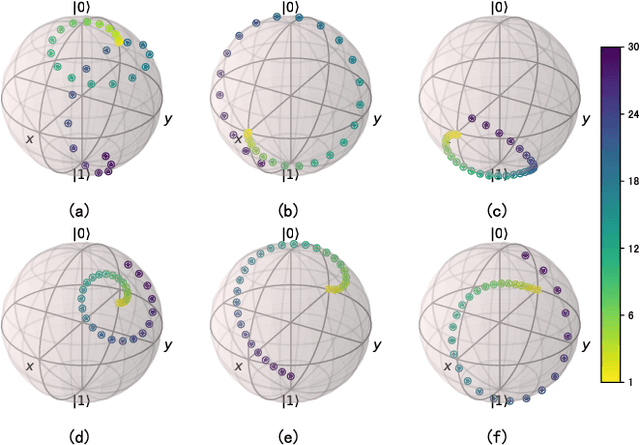
This paper introduces the Quantum Generative Diffusion Model (QGDM), a fully quantum-mechanical model for generating quantum state ensembles, inspired by Denoising Diffusion Probabilistic Models. QGDM features a diffusion process that introduces timestep-dependent noise into quantum states, paired with a denoising mechanism trained to reverse this contamination. This model efficiently evolves a completely mixed state into a target quantum state post-training. Our comparative analysis with Quantum Generative Adversarial Networks demonstrates QGDM's superiority, with fidelity metrics exceeding 0.99 in numerical simulations involving up to 4 qubits. Additionally, we present a Resource-Efficient version of QGDM (RE-QGDM), which minimizes the need for auxiliary qubits while maintaining impressive generative capabilities for tasks involving up to 8 qubits. These results showcase the proposed models' potential for tackling challenging quantum generation problems.
Expressivity Enhancement with Efficient Quadratic Neurons for Convolutional Neural Networks
Jun 10, 2023Convolutional neural networks (CNNs) have been successfully applied in a range of fields such as image classification and object segmentation. To improve their expressivity, various techniques, such as novel CNN architectures, have been explored. However, the performance gain from such techniques tends to diminish. To address this challenge, many researchers have shifted their focus to increasing the non-linearity of neurons, the fundamental building blocks of neural networks, to enhance the network expressivity. Nevertheless, most of these approaches incur a large number of parameters and thus formidable computation cost inevitably, impairing their efficiency to be deployed in practice. In this work, an efficient quadratic neuron structure is proposed to preserve the non-linearity with only negligible parameter and computation cost overhead. The proposed quadratic neuron can maximize the utilization of second-order computation information to improve the network performance. The experimental results have demonstrated that the proposed quadratic neuron can achieve a higher accuracy and a better computation efficiency in classification tasks compared with both linear neurons and non-linear neurons from previous works.