 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Schedule Optimization for Fast and Robust Diffusion Model Sampling
Nov 12, 2025


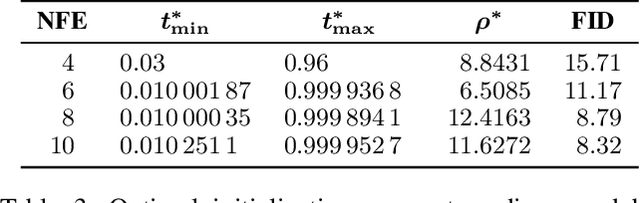
Diffusion probabilistic models have set a new standard for generative fidelity but are hindered by a slow iterative sampling process. A powerful training-free strategy to accelerate this process is Schedule Optimization, which aims to find an optimal distribution of timesteps for a fixed and small Number of Function Evaluations (NFE) to maximize sample quality. To this end, a successful schedule optimization method must adhere to four core principles: effectiveness, adaptivity, practical robustness, and computational efficiency. However, existing paradigms struggle to satisfy these principles simultaneously, motivating the need for a more advanced solution. To overcome these limitations, we propose the Hierarchical-Schedule-Optimizer (HSO), a novel and efficient bi-level optimization framework. HSO reframes the search for a globally optimal schedule into a more tractable problem by iteratively alternating between two synergistic levels: an upper-level global search for an optimal initialization strategy and a lower-level local optimization for schedule refinement. This process is guided by two key innovations: the Midpoint Error Proxy (MEP), a solver-agnostic and numerically stable objective for effective local optimization, and the Spacing-Penalized Fitness (SPF) function, which ensures practical robustness by penalizing pathologically close timesteps. Extensive experiments show that HSO sets a new state-of-the-art for training-free sampling in the extremely low-NFE regime. For instance, with an NFE of just 5, HSO achieves a remarkable FID of 11.94 on LAION-Aesthetics with Stable Diffusion v2.1. Crucially, this level of performance is attained not through costly retraining, but with a one-time optimization cost of less than 8 seconds, presenting a highly practical and efficient paradigm for diffusion model acceleration.
Continuous-variable Quantum Diffusion Model for State Generation and Restoration
Jun 24, 2025The generation and preservation of complex quantum states against environmental noise are paramount challenges in advancing continuous-variable (CV) quantum information processing. This paper introduces a novel framework based on continuous-variable quantum diffusion principles, synergizing them with CV quantum neural networks (CVQNNs) to address these dual challenges. For the task of state generation, our Continuous-Variable Quantum Diffusion Generative model (CVQD-G) employs a physically driven forward diffusion process using a thermal loss channel, which is then inverted by a learnable, parameter-efficient backward denoising process based on a CVQNN with time-embedding. This framework's capability is further extended for state recovery by the Continuous-Variable Quantum Diffusion Restoration model (CVQD-R), a specialized variant designed to restore quantum states, particularly coherent states with unknown parameters, from thermal degradation. Extensive numerical simulations validate these dual capabilities, demonstrating the high-fidelity generation of diverse Gaussian (coherent, squeezed) and non-Gaussian (Fock, cat) states, typically with fidelities exceeding 99%, and confirming the model's ability to robustly restore corrupted states. Furthermore, a comprehensive complexity analysis reveals favorable training and inference costs, highlighting the framework's efficiency, scalability, and its potential as a robust tool for quantum state engineering and noise mitigation in realistic CV quantum systems.
Overcoming Dimensional Factorization Limits in Discrete Diffusion Models through Quantum Joint Distribution Learning
May 08, 2025This study explores quantum-enhanced discrete diffusion models to overcome classical limitations in learning high-dimensional distributions. We rigorously prove that classical discrete diffusion models, which calculate per-dimension transition probabilities to avoid exponential computational cost, exhibit worst-case linear scaling of Kullback-Leibler (KL) divergence with data dimension. To address this, we propose a Quantum Discrete Denoising Diffusion Probabilistic Model (QD3PM), which enables joint probability learning through diffusion and denoising in exponentially large Hilbert spaces. By deriving posterior states through quantum Bayes' theorem, similar to the crucial role of posterior probabilities in classical diffusion models, and by learning the joint probability, we establish a solid theoretical foundation for quantum-enhanced diffusion models. For denoising, we design a quantum circuit using temporal information for parameter sharing and learnable classical-data-controlled rotations for encoding. Exploiting joint distribution learning, our approach enables single-step sampling from pure noise, eliminating iterative requirements of existing models. Simulations demonstrate the proposed model's superior accuracy in modeling complex distributions compared to factorization methods. Hence, this paper establishes a new theoretical paradigm in generative models by leveraging the quantum advantage in joint distribution learning.
HQViT: Hybrid Quantum Vision Transformer for Image Classification
Apr 03, 2025



Transformer-based architectures have revolutionized the landscape of deep learning. In computer vision domain, Vision Transformer demonstrates remarkable performance on par with or even surpassing that of convolutional neural networks. However, the quadratic computational complexity of its self-attention mechanism poses challenges for classical computing, making model training with high-dimensional input data, e.g., images, particularly expensive. To address such limitations, we propose a Hybrid Quantum Vision Transformer (HQViT), that leverages the principles of quantum computing to accelerate model training while enhancing model performance. HQViT introduces whole-image processing with amplitude encoding to better preserve global image information without additional positional encoding. By leveraging quantum computation on the most critical steps and selectively handling other components in a classical way, we lower the cost of quantum resources for HQViT. The qubit requirement is minimized to $O(log_2N)$ and the number of parameterized quantum gates is only $O(log_2d)$, making it well-suited for Noisy Intermediate-Scale Quantum devices. By offloading the computationally intensive attention coefficient matrix calculation to the quantum framework, HQViT reduces the classical computational load by $O(T^2d)$. Extensive experiments across various computer vision datasets demonstrate that HQViT outperforms existing models, achieving a maximum improvement of up to $10.9\%$ (on the MNIST 10-classification task) over the state of the art. This work highlights the great potential to combine quantum and classical computing to cope with complex image classification tasks.
Quantum Complex-Valued Self-Attention Model
Mar 24, 2025



The self-attention mechanism has revolutionized classical machine learning, yet its quantum counterpart remains underexplored in fully harnessing the representational power of quantum states. Current quantum self-attention models exhibit a critical limitation by neglecting the indispensable phase information inherent in quantum systems when compressing attention weights into real-valued overlaps. To address this fundamental gap, we propose the Quantum Complex-Valued Self-Attention Model (QCSAM), the first framework that explicitly leverages complex-valued similarities between quantum states to capture both amplitude and phase relationships. Simultaneously, we enhance the standard Linear Combination of Unitaries (LCUs) method by introducing a Complex LCUs (CLCUs) framework that natively supports complex-valued coefficients. This framework enables the weighting of corresponding quantum values using fixed quantum complex self-attention weights, while also supporting trainable complex-valued parameters for value aggregation and quantum multi-head attention. Experimental evaluations on MNIST and Fashion-MNIST demonstrate our model's superiority over recent quantum self-attention architectures including QKSAN, QSAN, and GQHAN, with multi-head configurations showing consistent advantages over single-head variants. We systematically evaluate model scalability through qubit configurations ranging from 3 to 8 qubits and multi-class classification tasks spanning 2 to 4 categories. Through comprehensive ablation studies, we establish the critical advantage of complex-valued quantum attention weights over real-valued alternatives.
Quantum Mixed-State Self-Attention Network
Mar 05, 2024



The rapid advancement of quantum computing has increasingly highlighted its potential in the realm of machine learning, particularly in the context of natural language processing (NLP) tasks. Quantum machine learning (QML) leverages the unique capabilities of quantum computing to offer novel perspectives and methodologies for complex data processing and pattern recognition challenges. This paper introduces a novel Quantum Mixed-State Attention Network (QMSAN), which integrates the principles of quantum computing with classical machine learning algorithms, especially self-attention networks, to enhance the efficiency and effectiveness in handling NLP tasks. QMSAN model employs a quantum attention mechanism based on mixed states, enabling efficient direct estimation of similarity between queries and keys within the quantum domain, leading to more effective attention weight acquisition. Additionally, we propose an innovative quantum positional encoding scheme, implemented through fixed quantum gates within the quantum circuit, to enhance the model's accuracy. Experimental validation on various datasets demonstrates that QMSAN model outperforms existing quantum and classical models in text classification, achieving significant performance improvements. QMSAN model not only significantly reduces the number of parameters but also exceeds classical self-attention networks in performance, showcasing its strong capability in data representation and information extraction. Furthermore, our study investigates the model's robustness in different quantum noise environments, showing that QMSAN possesses commendable robustness to low noise.
Quantum Generative Diffusion Model
Jan 13, 2024
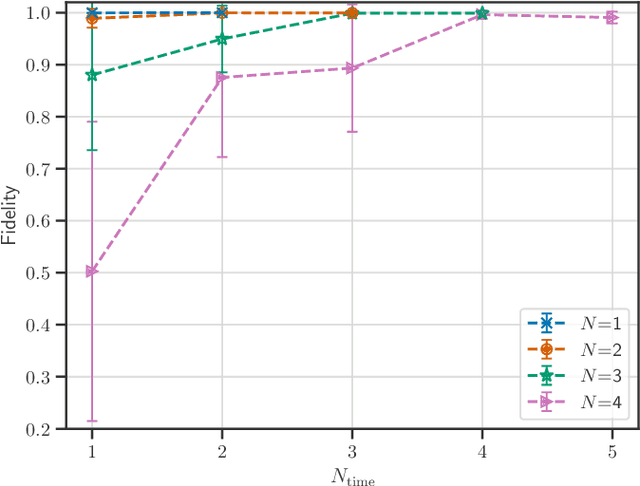
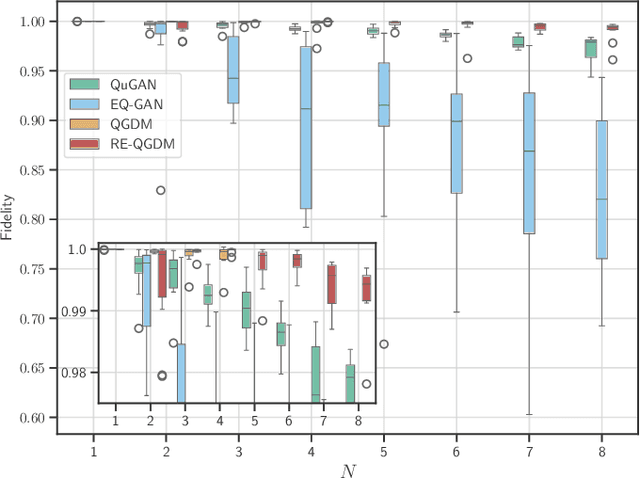
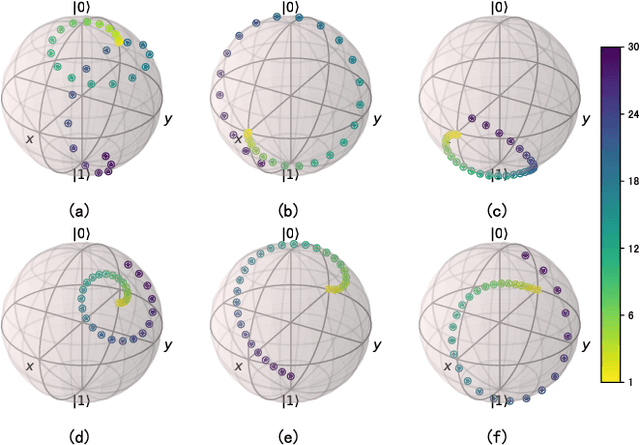
This paper introduces the Quantum Generative Diffusion Model (QGDM), a fully quantum-mechanical model for generating quantum state ensembles, inspired by Denoising Diffusion Probabilistic Models. QGDM features a diffusion process that introduces timestep-dependent noise into quantum states, paired with a denoising mechanism trained to reverse this contamination. This model efficiently evolves a completely mixed state into a target quantum state post-training. Our comparative analysis with Quantum Generative Adversarial Networks demonstrates QGDM's superiority, with fidelity metrics exceeding 0.99 in numerical simulations involving up to 4 qubits. Additionally, we present a Resource-Efficient version of QGDM (RE-QGDM), which minimizes the need for auxiliary qubits while maintaining impressive generative capabilities for tasks involving up to 8 qubits. These results showcase the proposed models' potential for tackling challenging quantum generation problems.
A Sparse Cross Attention-based Graph Convolution Network with Auxiliary Information Awareness for Traffic Flow Prediction
Dec 14, 2023Deep graph convolution networks (GCNs) have recently shown excellent performance in traffic prediction tasks. However, they face some challenges. First, few existing models consider the influence of auxiliary information, i.e., weather and holidays, which may result in a poor grasp of spatial-temporal dynamics of traffic data. Second, both the construction of a dynamic adjacent matrix and regular graph convolution operations have quadratic computation complexity, which restricts the scalability of GCN-based models. To address such challenges, this work proposes a deep encoder-decoder model entitled AIMSAN. It contains an auxiliary information-aware module (AIM) and sparse cross attention-based graph convolution network (SAN). The former learns multi-attribute auxiliary information and obtains its embedded presentation of different time-window sizes. The latter uses a cross-attention mechanism to construct dynamic adjacent matrices by fusing traffic data and embedded auxiliary data. Then, SAN applies diffusion GCN on traffic data to mine rich spatial-temporal dynamics. Furthermore, AIMSAN considers and uses the spatial sparseness of traffic nodes to reduce the quadratic computation complexity. Experimental results on three public traffic datasets demonstrate that the proposed method outperforms other counterparts in terms of various performance indices. Specifically, the proposed method has competitive performance with the state-of-the-art algorithms but saves 35.74% of GPU memory usage, 42.25% of training time, and 45.51% of validation time on average.
MODMA dataset: a Multi-modal Open Dataset for Mental-disorder Analysis
Mar 05, 2020

According to the World Health Organization, the number of mental disorder patients, especially depression patients, has grown rapidly and become a leading contributor to the global burden of disease. However, the present common practice of depression diagnosis is based on interviews and clinical scales carried out by doctors, which is not only labor-consuming but also time-consuming. One important reason is due to the lack of physiological indicators for mental disorders. With the rising of tools such as data mining and artificial intelligence, using physiological data to explore new possible physiological indicators of mental disorder and creating new applications for mental disorder diagnosis has become a new research hot topic. However, good quality physiological data for mental disorder patients are hard to acquire. We present a multi-modal open dataset for mental-disorder analysis. The dataset includes EEG and audio data from clinically depressed patients and matching normal controls. All our patients were carefully diagnosed and selected by professional psychiatrists in hospitals. The EEG dataset includes not only data collected using traditional 128-electrodes mounted elastic cap, but also a novel wearable 3-electrode EEG collector for pervasive applications. The 128-electrodes EEG signals of 53 subjects were recorded as both in resting state and under stimulation; the 3-electrode EEG signals of 55 subjects were recorded in resting state; the audio data of 52 subjects were recorded during interviewing, reading, and picture description. We encourage other researchers in the field to use it for testing their methods of mental-disorder analysis.