 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
Few-Shot Referring Video Single- and Multi-Object Segmentation via Cross-Modal Affinity with Instance Sequence Matching
Apr 18, 2025Referring video object segmentation (RVOS) aims to segment objects in videos guided by natural language descriptions. We propose FS-RVOS, a Transformer-based model with two key components: a cross-modal affinity module and an instance sequence matching strategy, which extends FS-RVOS to multi-object segmentation (FS-RVMOS). Experiments show FS-RVOS and FS-RVMOS outperform state-of-the-art methods across diverse benchmarks, demonstrating superior robustness and accuracy.
DTN: Deep Multiple Task-specific Feature Interactions Network for Multi-Task Recommendation
Aug 21, 2024



Neural-based multi-task learning (MTL) has been successfully applied to many recommendation applications. However, these MTL models (e.g., MMoE, PLE) did not consider feature interaction during the optimization, which is crucial for capturing complex high-order features and has been widely used in ranking models for real-world recommender systems. Moreover, through feature importance analysis across various tasks in MTL, we have observed an interesting divergence phenomenon that the same feature can have significantly different importance across different tasks in MTL. To address these issues, we propose Deep Multiple Task-specific Feature Interactions Network (DTN) with a novel model structure design. DTN introduces multiple diversified task-specific feature interaction methods and task-sensitive network in MTL networks, enabling the model to learn task-specific diversified feature interaction representations, which improves the efficiency of joint representation learning in a general setup. We applied DTN to our company's real-world E-commerce recommendation dataset, which consisted of over 6.3 billion samples, the results demonstrated that DTN significantly outperformed state-of-the-art MTL models. Moreover, during online evaluation of DTN in a large-scale E-commerce recommender system, we observed a 3.28% in clicks, a 3.10% increase in orders and a 2.70% increase in GMV (Gross Merchandise Value) compared to the state-of-the-art MTL models. Finally, extensive offline experiments conducted on public benchmark datasets demonstrate that DTN can be applied to various scenarios beyond recommendations, enhancing the performance of ranking models.
A Sparse Cross Attention-based Graph Convolution Network with Auxiliary Information Awareness for Traffic Flow Prediction
Dec 14, 2023Deep graph convolution networks (GCNs) have recently shown excellent performance in traffic prediction tasks. However, they face some challenges. First, few existing models consider the influence of auxiliary information, i.e., weather and holidays, which may result in a poor grasp of spatial-temporal dynamics of traffic data. Second, both the construction of a dynamic adjacent matrix and regular graph convolution operations have quadratic computation complexity, which restricts the scalability of GCN-based models. To address such challenges, this work proposes a deep encoder-decoder model entitled AIMSAN. It contains an auxiliary information-aware module (AIM) and sparse cross attention-based graph convolution network (SAN). The former learns multi-attribute auxiliary information and obtains its embedded presentation of different time-window sizes. The latter uses a cross-attention mechanism to construct dynamic adjacent matrices by fusing traffic data and embedded auxiliary data. Then, SAN applies diffusion GCN on traffic data to mine rich spatial-temporal dynamics. Furthermore, AIMSAN considers and uses the spatial sparseness of traffic nodes to reduce the quadratic computation complexity. Experimental results on three public traffic datasets demonstrate that the proposed method outperforms other counterparts in terms of various performance indices. Specifically, the proposed method has competitive performance with the state-of-the-art algorithms but saves 35.74% of GPU memory usage, 42.25% of training time, and 45.51% of validation time on average.
Learning Cross-Modal Affinity for Referring Video Object Segmentation Targeting Limited Samples
Sep 05, 2023



Referring video object segmentation (RVOS), as a supervised learning task, relies on sufficient annotated data for a given scene. However, in more realistic scenarios, only minimal annotations are available for a new scene, which poses significant challenges to existing RVOS methods. With this in mind, we propose a simple yet effective model with a newly designed cross-modal affinity (CMA) module based on a Transformer architecture. The CMA module builds multimodal affinity with a few samples, thus quickly learning new semantic information, and enabling the model to adapt to different scenarios. Since the proposed method targets limited samples for new scenes, we generalize the problem as - few-shot referring video object segmentation (FS-RVOS). To foster research in this direction, we build up a new FS-RVOS benchmark based on currently available datasets. The benchmark covers a wide range and includes multiple situations, which can maximally simulate real-world scenarios. Extensive experiments show that our model adapts well to different scenarios with only a few samples, reaching state-of-the-art performance on the benchmark. On Mini-Ref-YouTube-VOS, our model achieves an average performance of 53.1 J and 54.8 F, which are 10% better than the baselines. Furthermore, we show impressive results of 77.7 J and 74.8 F on Mini-Ref-SAIL-VOS, which are significantly better than the baselines. Code is publicly available at https://github.com/hengliusky/Few_shot_RVOS.
Resource Scheduling in Edge Computing: A Survey
Aug 18, 2021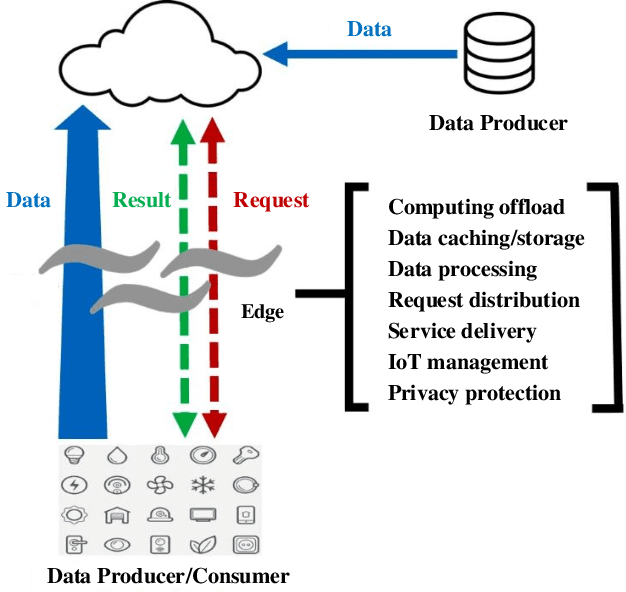
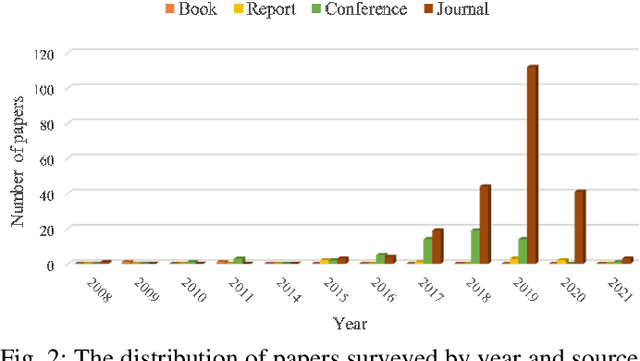
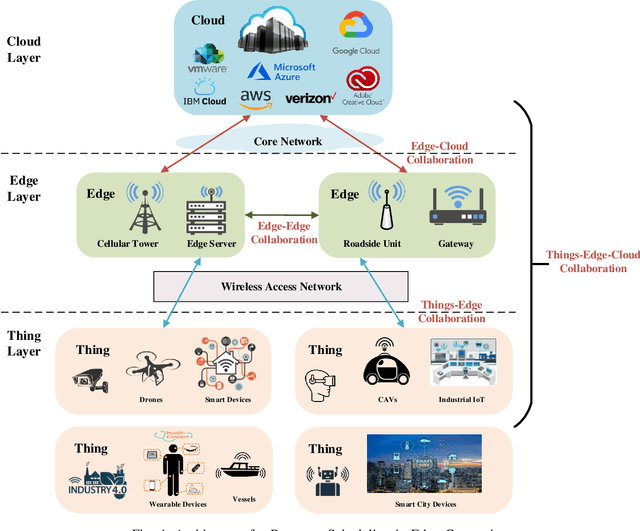
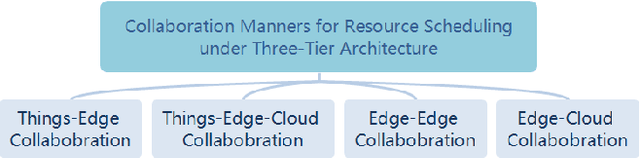
With the proliferation of the Internet of Things (IoT) and the wide penetration of wireless networks, the surging demand for data communications and computing calls for the emerging edge computing paradigm. By moving the services and functions located in the cloud to the proximity of users, edge computing can provide powerful communication, storage, networking, and communication capacity. The resource scheduling in edge computing, which is the key to the success of edge computing systems, has attracted increasing research interests. In this paper, we survey the state-of-the-art research findings to know the research progress in this field. Specifically, we present the architecture of edge computing, under which different collaborative manners for resource scheduling are discussed. Particularly, we introduce a unified model before summarizing the current works on resource scheduling from three research issues, including computation offloading, resource allocation, and resource provisioning. Based on two modes of operation, i.e., centralized and distributed modes, different techniques for resource scheduling are discussed and compared. Also, we summarize the main performance indicators based on the surveyed literature. To shed light on the significance of resource scheduling in real-world scenarios, we discuss several typical application scenarios involved in the research of resource scheduling in edge computing. Finally, we highlight some open research challenges yet to be addressed and outline several open issues as the future research direction.