 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViroBench: Benchmarking Nucleotide Foundation Models on Viral Genomics Tasks
May 25, 2026Nucleotide sequences constitute the fundamental genetic basis of biological systems, rendering viral genomic analysis critical for biomedical advancement. Despite progress in biological foundation models, specifically nucleotide foundation models (NFMs), the field lacks a unified standard for viral genomics to facilitate community development and enforce biosecurity constraints. To address this, we introduce ViroBench, the first comprehensive and large-scale benchmark specifically designed for NFMs in viral settings. ViroBench evaluates models across two critical dimensions: biological understanding and latent biosecurity risk, covering 18 diverse scenarios within 4 task types. Extensive evaluation of 66 NFMs across diverse architectures yields three critical conclusions. Firstly, NFMs exhibit a performance degradation in biological understanding under phylogenetic and temporal shifts, indicating weak extrapolation capabilities. Secondly, generation tasks reveal a decoupling between statistical likelihood and biological functional validity, posing latent biosecurity risks. Thirdly, controlled ablation studies reveal that taxonomic diversity in pretraining data outweighs parameter scale. Specifically, a lightweight baseline trained on diverse data achieves a 67.5% performance gain over its original model. Overall, ViroBench provides interpretable, diagnostic evaluations and a reproducible measurement framework for future research on viral nucleotide foundation models. The datasets and code are publicly available at https://github.com/QIANJINYDX/ViroBench.
Hide in Plain Sight: Clean-Label Backdoor for Auditing Membership Inference
Nov 24, 2024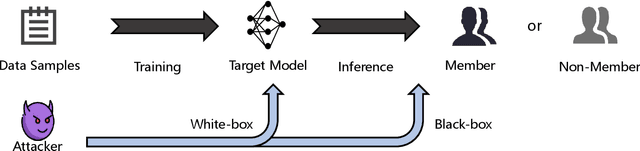



Membership inference attacks (MIAs) are critical tools for assessing privacy risks and ensuring compliance with regulations like the General Data Protection Regulation (GDPR). However, their potential for auditing unauthorized use of data remains under explored. To bridge this gap, we propose a novel clean-label backdoor-based approach for MIAs, designed specifically for robust and stealthy data auditing. Unlike conventional methods that rely on detectable poisoned samples with altered labels, our approach retains natural labels, enhancing stealthiness even at low poisoning rates. Our approach employs an optimal trigger generated by a shadow model that mimics the target model's behavior. This design minimizes the feature-space distance between triggered samples and the source class while preserving the original data labels. The result is a powerful and undetectable auditing mechanism that overcomes limitations of existing approaches, such as label inconsistencies and visual artifacts in poisoned samples. The proposed method enables robust data auditing through black-box access, achieving high attack success rates across diverse datasets and model architectures. Additionally, it addresses challenges related to trigger stealthiness and poisoning durability, establishing itself as a practical and effective solution for data auditing. Comprehensive experiments validate the efficacy and generalizability of our approach, outperforming several baseline methods in both stealth and attack success metrics.
CLMIA: Membership Inference Attacks via Unsupervised Contrastive Learning
Nov 17, 2024



Since machine learning model is often trained on a limited data set, the model is trained multiple times on the same data sample, which causes the model to memorize most of the training set data. Membership Inference Attacks (MIAs) exploit this feature to determine whether a data sample is used for training a machine learning model. However, in realistic scenarios, it is difficult for the adversary to obtain enough qualified samples that mark accurate identity information, especially since most samples are non-members in real world applications. To address this limitation, in this paper, we propose a new attack method called CLMIA, which uses unsupervised contrastive learning to train an attack model without using extra membership status information. Meanwhile, in CLMIA, we require only a small amount of data with known membership status to fine-tune the attack model. Experimental results demonstrate that CLMIA performs better than existing attack methods for different datasets and model structures, especially with data with less marked identity information. In addition, we experimentally find that the attack performs differently for different proportions of labeled identity information for member and non-member data. More analysis proves that our attack method performs better with less labeled identity information, which applies to more realistic scenarios.
DTN: Deep Multiple Task-specific Feature Interactions Network for Multi-Task Recommendation
Aug 21, 2024



Neural-based multi-task learning (MTL) has been successfully applied to many recommendation applications. However, these MTL models (e.g., MMoE, PLE) did not consider feature interaction during the optimization, which is crucial for capturing complex high-order features and has been widely used in ranking models for real-world recommender systems. Moreover, through feature importance analysis across various tasks in MTL, we have observed an interesting divergence phenomenon that the same feature can have significantly different importance across different tasks in MTL. To address these issues, we propose Deep Multiple Task-specific Feature Interactions Network (DTN) with a novel model structure design. DTN introduces multiple diversified task-specific feature interaction methods and task-sensitive network in MTL networks, enabling the model to learn task-specific diversified feature interaction representations, which improves the efficiency of joint representation learning in a general setup. We applied DTN to our company's real-world E-commerce recommendation dataset, which consisted of over 6.3 billion samples, the results demonstrated that DTN significantly outperformed state-of-the-art MTL models. Moreover, during online evaluation of DTN in a large-scale E-commerce recommender system, we observed a 3.28% in clicks, a 3.10% increase in orders and a 2.70% increase in GMV (Gross Merchandise Value) compared to the state-of-the-art MTL models. Finally, extensive offline experiments conducted on public benchmark datasets demonstrate that DTN can be applied to various scenarios beyond recommendations, enhancing the performance of ranking models.
A Fast Multitaper Power Spectrum Estimation in Nonuniformly Sampled Time Series
Jul 02, 2024



Nonuniformly sampled signals are prevalent in real-world applications but pose a significant challenge when estimating their power spectra from a finite number of samples of a single realization. The optimal solution using Bronez Generalized Prolate Spheroidal Sequence (GPSS) is computationally intensive and thus impractical for large datasets. This paper presents a fast nonparametric method, MultiTaper NonUniform Fast Fourier Transform (MTNUFFT), capable of estimating power spectra with lower computational burden. The method first derives a set of optimal tapers via cubic spline interpolation on a nominal analysis band, and subsequently shifts these tapers to other analysis bands using NonUniform FFT (NUFFT). The estimated spectral power within the band is the average power at the outputs of the taper set. This algorithm eliminates the time-consuming computation for solving the Generalized Eigenvalue Problem (GEP), thus reducing the computational load from $O(N^4)$ to $O(N \log N + N \log(1/\epsilon))$, comparable with the NUFFT. The statistical properties of the estimator are assessed using Bronez GPSS theory, revealing that the bias and variance bound of the MTNUFFT estimator are identical to those of the optimal estimator. Furthermore, the degradation of bias bound can serve as a measure of the deviation from optimality. The performance of the estimator is evaluated using both simulation and real-world data, demonstrating its practical applicability. The code of the proposed fast algorithm is available on GitHub (https://github.com/jiecui/mtnufft).