 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide in Plain Sight: Clean-Label Backdoor for Auditing Membership Inference
Nov 24, 2024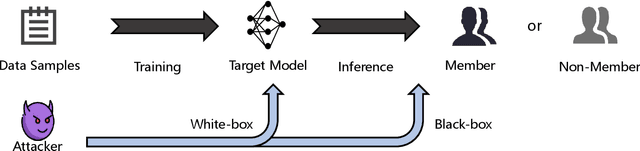



Membership inference attacks (MIAs) are critical tools for assessing privacy risks and ensuring compliance with regulations like the General Data Protection Regulation (GDPR). However, their potential for auditing unauthorized use of data remains under explored. To bridge this gap, we propose a novel clean-label backdoor-based approach for MIAs, designed specifically for robust and stealthy data auditing. Unlike conventional methods that rely on detectable poisoned samples with altered labels, our approach retains natural labels, enhancing stealthiness even at low poisoning rates. Our approach employs an optimal trigger generated by a shadow model that mimics the target model's behavior. This design minimizes the feature-space distance between triggered samples and the source class while preserving the original data labels. The result is a powerful and undetectable auditing mechanism that overcomes limitations of existing approaches, such as label inconsistencies and visual artifacts in poisoned samples. The proposed method enables robust data auditing through black-box access, achieving high attack success rates across diverse datasets and model architectures. Additionally, it addresses challenges related to trigger stealthiness and poisoning durability, establishing itself as a practical and effective solution for data auditing. Comprehensive experiments validate the efficacy and generalizability of our approach, outperforming several baseline methods in both stealth and attack success metrics.
CLMIA: Membership Inference Attacks via Unsupervised Contrastive Learning
Nov 17, 2024



Since machine learning model is often trained on a limited data set, the model is trained multiple times on the same data sample, which causes the model to memorize most of the training set data. Membership Inference Attacks (MIAs) exploit this feature to determine whether a data sample is used for training a machine learning model. However, in realistic scenarios, it is difficult for the adversary to obtain enough qualified samples that mark accurate identity information, especially since most samples are non-members in real world applications. To address this limitation, in this paper, we propose a new attack method called CLMIA, which uses unsupervised contrastive learning to train an attack model without using extra membership status information. Meanwhile, in CLMIA, we require only a small amount of data with known membership status to fine-tune the attack model. Experimental results demonstrate that CLMIA performs better than existing attack methods for different datasets and model structures, especially with data with less marked identity information. In addition, we experimentally find that the attack performs differently for different proportions of labeled identity information for member and non-member data. More analysis proves that our attack method performs better with less labeled identity information, which applies to more realistic scenarios.