 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
WDMamba: When Wavelet Degradation Prior Meets Vision Mamba for Image Dehazing
May 07, 2025In this paper, we reveal a novel haze-specific wavelet degradation prior observed through wavelet transform analysis, which shows that haze-related information predominantly resides in low-frequency components. Exploiting this insight, we propose a novel dehazing framework, WDMamba, which decomposes the image dehazing task into two sequential stages: low-frequency restoration followed by detail enhancement. This coarse-to-fine strategy enables WDMamba to effectively capture features specific to each stage of the dehazing process, resulting in high-quality restored images. Specifically, in the low-frequency restoration stage, we integrate Mamba blocks to reconstruct global structures with linear complexity, efficiently removing overall haze and producing a coarse restored image. Thereafter, the detail enhancement stage reinstates fine-grained information that may have been overlooked during the previous phase, culminating in the final dehazed output. Furthermore, to enhance detail retention and achieve more natural dehazing, we introduce a self-guided contrastive regularization during network training. By utilizing the coarse restored output as a hard negative example, our model learns more discriminative representations, substantially boosting the overall dehazing performance. Extensive evaluations on public dehazing benchmarks demonstrate that our method surpasses state-of-the-art approaches both qualitatively and quantitatively. Code is available at https://github.com/SunJ000/WDMamba.
Physical-Layer Security in Mixed Near-Field and Far-Field Communication Systems
Apr 28, 2025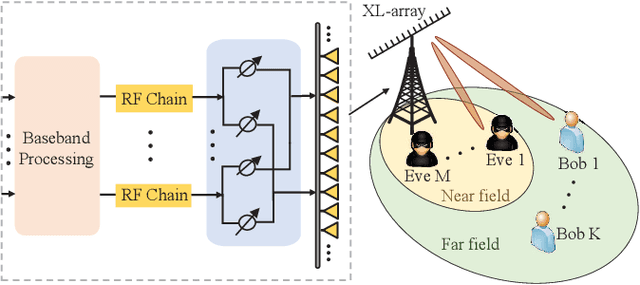
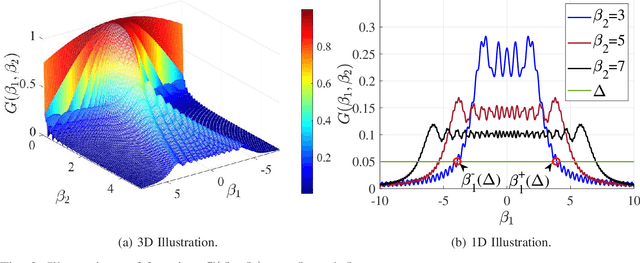
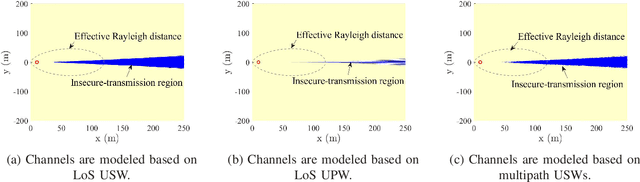
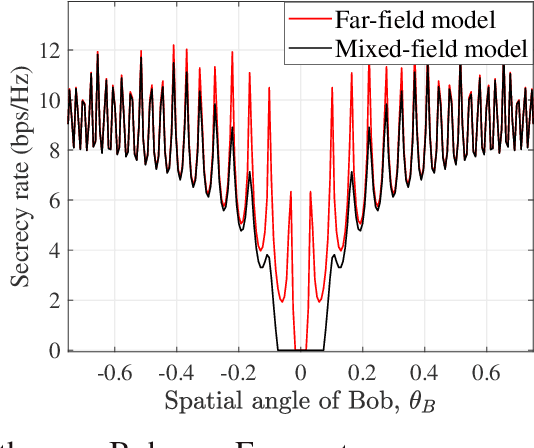
Extremely large-scale arrays (XL-arrays) have emerged as a promising technology to improve the spectrum efficiency and spatial resolution of future wireless systems. Different from existing works that mostly considered physical layer security (PLS) in either the far-field or near-field, we consider in this paper a new and practical scenario, where legitimate users (Bobs) are located in the far-field of a base station (BS) while eavesdroppers (Eves) are located in the near-field for intercepting confidential information at short distance, referred to as the mixed near-field and far-field PLS. Specifically, we formulate an optimization problem to maximize the sum-secrecy-rate of all Bobs by optimizing the power allocation of the BS, subject to the constraint on the total BS transmit power. To shed useful insights, we first consider a one-Bob-one-Eve system and characterize the insecure-transmission region of the Bob in closed form. Interestingly, we show that the insecure-transmission region is significantly \emph{expanded} as compared to that in conventional far-field PLS systems, due to the energy-spread effect in the mixed-field scenario. Then, we further extend the analysis to a two-Bob-one-Eve system. It is revealed that as compared to the one-Bob system, the interferences from the other Bob can be effectively used to weaken the capability of Eve for intercepting signals of target Bobs, thus leading to enhanced secrecy rates. Furthermore, we propose an efficient algorithm to obtain a high-quality solution to the formulated non-convex problem by leveraging the successive convex approximation (SCA) technique. Finally, numerical results demonstrate that our proposed algorithm achieves a higher sum-secrecy-rate than the benchmark scheme where the power allocation is designed based on the (simplified) far-field channel model.
Unwarping Screen Content Images via Structure-texture Enhancement Network and Transformation Self-estimation
Apr 21, 2025While existing implicit neural network-based image unwarping methods perform well on natural images, they struggle to handle screen content images (SCIs), which often contain large geometric distortions, text, symbols, and sharp edges. To address this, we propose a structure-texture enhancement network (STEN) with transformation self-estimation for SCI warping. STEN integrates a B-spline implicit neural representation module and a transformation error estimation and self-correction algorithm. It comprises two branches: the structure estimation branch (SEB), which enhances local aggregation and global dependency modeling, and the texture estimation branch (TEB), which improves texture detail synthesis using B-spline implicit neural representation. Additionally, the transformation self-estimation module autonomously estimates the transformation error and corrects the coordinate transformation matrix, effectively handling real-world image distortions. Extensive experiments on public SCI datasets demonstrate that our approach significantly outperforms state-of-the-art methods. Comparisons on well-known natural image datasets also show the potential of our approach for natural image distortion.
Few-Shot Referring Video Single- and Multi-Object Segmentation via Cross-Modal Affinity with Instance Sequence Matching
Apr 18, 2025Referring video object segmentation (RVOS) aims to segment objects in videos guided by natural language descriptions. We propose FS-RVOS, a Transformer-based model with two key components: a cross-modal affinity module and an instance sequence matching strategy, which extends FS-RVOS to multi-object segmentation (FS-RVMOS). Experiments show FS-RVOS and FS-RVMOS outperform state-of-the-art methods across diverse benchmarks, demonstrating superior robustness and accuracy.
GroundingSuite: Measuring Complex Multi-Granular Pixel Grounding
Mar 13, 2025Pixel grounding, encompassing tasks such as Referring Expression Segmentation (RES), has garnered considerable attention due to its immense potential for bridging the gap between vision and language modalities. However, advancements in this domain are currently constrained by limitations inherent in existing datasets, including limited object categories, insufficient textual diversity, and a scarcity of high-quality annotations. To mitigate these limitations, we introduce GroundingSuite, which comprises: (1) an automated data annotation framework leveraging multiple Vision-Language Model (VLM) agents; (2) a large-scale training dataset encompassing 9.56 million diverse referring expressions and their corresponding segmentations; and (3) a meticulously curated evaluation benchmark consisting of 3,800 images. The GroundingSuite training dataset facilitates substantial performance improvements, enabling models trained on it to achieve state-of-the-art results. Specifically, a cIoU of 68.9 on gRefCOCO and a gIoU of 55.3 on RefCOCOm. Moreover, the GroundingSuite annotation framework demonstrates superior efficiency compared to the current leading data annotation method, i.e., $4.5 \times$ faster than the GLaMM.
CLIP-SR: Collaborative Linguistic and Image Processing for Super-Resolution
Dec 16, 2024Convolutional Neural Networks (CNNs) have advanced Image Super-Resolution (SR), but most CNN-based methods rely solely on pixel-based transformations, often leading to artifacts and blurring, particularly with severe downsampling (e.g., 8x or 16x). Recent text-guided SR methods attempt to leverage textual information for enhanced detail, but they frequently struggle with effective alignment, resulting in inconsistent semantic coherence. To address these limitations, we introduce a multi-modal semantic enhancement approach that combines textual semantics with visual features, effectively tackling semantic mismatches and detail loss in highly degraded LR images. Our proposed multi-modal collaborative framework enables the production of realistic and high-quality SR images at significant up-scaling factors. The framework integrates text and image inputs, employing a prompt predictor, Text-Image Fusion Block (TIFBlock), and Iterative Refinement Module alongside CLIP (Contrastive Language-Image Pretraining) features to guide a progressive enhancement process with fine-grained alignment. This alignment produces high-resolution outputs with crisp details and semantic coherence, even at large scaling factors. Through extensive comparative experiments and ablation studies, we validate the effectiveness of our approach. Additionally, by incorporating textual semantic guidance, our technique enables a degree of super-resolution editability while maintaining semantic coherence.
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement
Dec 05, 2024Large Language Models (LLMs) have achieved remarkable progress in recent years; however, their excellent performance is still largely limited to major world languages, primarily English. Many LLMs continue to face challenges with multilingual tasks, especially when it comes to low-resource languages. To address this issue, we introduced Marco-LLM: Massive multilingual training for cross-lingual enhancement LLM. We have collected a substantial amount of multilingual data for several low-resource languages and conducted extensive continual pre-training using the Qwen2 models. This effort has resulted in a multilingual LLM named Marco-LLM. Through comprehensive evaluations on various multilingual benchmarks, including MMMLU, AGIEval, Belebele, Flores-200, XCOPA and many others, Marco-LLM has demonstrated substantial improvements over state-of-the-art LLMs. Furthermore, Marco-LLM achieved substantial enhancements in any-to-any machine translation tasks, showing the effectiveness of our multilingual LLM. Marco-LLM is a pioneering multilingual LLM designed to not only perform exceptionally well in multilingual tasks, including low-resource languages, but also maintain strong performance in English and other major languages, closing the performance gap between high- and low-resource language capabilities. By bridging languages, this effort demonstrates our dedication to ensuring LLMs work accurately across various languages.
Frequency Diverse Array-enabled RIS-aided Integrated Sensing and Communication
Oct 01, 2024Integrated sensing and communication (ISAC) has been envisioned as a prospective technology to enable ubiquitous sensing and communications in next-generation wireless networks. In contrast to existing works on reconfigurable intelligent surface (RIS) aided ISAC systems using conventional phased arrays (PAs), this paper investigates a frequency diverse array (FDA)-enabled RIS-aided ISAC system, where the FDA aims to provide a distance-angle-dependent beampattern to effectively suppress the clutter, and RIS is employed to establish high-quality links between the BS and users/target. We aim to maximize sum rate by jointly optimizing the BS transmit beamforming vectors, the covariance matrix of the dedicated radar signal, the RIS phase shift matrix, the FDA frequency offsets and the radar receive equalizer, while guaranteeing the required signal-to-clutter-plus-noise ratio (SCNR) of the radar echo signal. To tackle this challenging problem, we first theoretically prove that the dedicated radar signal is unnecessary for enhancing target sensing performance, based on which the original problem is much simplified. Then, we turn our attention to the single-user single-target (SUST) scenario to demonstrate that the FDA-RIS-aided ISAC system always achieves a higher SCNR than its PA-RIS-aided counterpart. Moreover, it is revealed that the SCNR increment exhibits linear growth with the BS transmit power and the number of BS receive antennas. In order to effectively solve this simplified problem, we leverage the fractional programming (FP) theory and subsequently develop an efficient alternating optimization (AO) algorithm based on symmetric alternating direction method of multipliers (SADMM) and successive convex approximation (SCA) techniques. Numerical results demonstrate the superior performance of our proposed algorithm in terms of sum rate and radar SCNR.
Massive MIMO-OTFS-Based Random Access for Cooperative LEO Satellite Constellations
Aug 05, 2024



This paper investigates joint device identification, channel estimation, and symbol detection for cooperative multi-satellite-enhanced random access, where orthogonal time-frequency space modulation with the large antenna array is utilized to combat the dynamics of the terrestrial-satellite links (TSLs). We introduce the generalized complex exponential basis expansion model to parameterize TSLs, thereby reducing the pilot overhead. By exploiting the block sparsity of the TSLs in the angular domain, a message passing algorithm is designed for initial channel estimation. Subsequently, we examine two cooperative modes to leverage the spatial diversity within satellite constellations: the centralized mode, where computations are performed at a high-power central server, and the distributed mode, where computations are offloaded to edge satellites with minimal signaling overhead. Specifically, in the centralized mode, device identification is achieved by aggregating backhaul information from edge satellites, and channel estimation and symbol detection are jointly enhanced through a structured approximate expectation propagation (AEP) algorithm. In the distributed mode, edge satellites share channel information and exchange soft information about data symbols, leading to a distributed version of AEP. The introduced basis expansion model for TSLs enables the efficient implementation of both centralized and distributed algorithms via fast Fourier transform. Simulation results demonstrate that proposed schemes significantly outperform conventional algorithms in terms of the activity error rate, the normalized mean squared error, and the symbol error rate. Notably, the distributed mode achieves performance comparable to the centralized mode with only two exchanges of soft information about data symbols within the constellation.