 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State-Transition Framework for Efficient LLM Reasoning
Feb 01, 2026While Long Chain-of-Thought (CoT) reasoning significantly improves Large Language Models (LLMs) performance on complex reasoning tasks, the substantial computational and memory costs of generating long CoT sequences limit their efficiency and practicality. Existing studies usually enhance the reasoning efficiency of LLMs by compressing CoT sequences. However, this approach conflicts with test-time scaling, limiting the reasoning capacity of LLMs. In this paper, we propose an efficient reasoning framework that models the reasoning process of LLMs as a state-transition process. Specifically, we first apply a linear attention mechanism to estimate the LLM's reasoning state, which records the historical reasoning information from previous reasoning steps. Then, based on the query prompt and the reasoning state, the LLM can efficiently perform the current reasoning step and update the state. With the linear attention, each token in the current reasoning step can directly retrieve relevant historical reasoning information from the reasoning state, without explicitly attending to tokens in previous reasoning steps. In this way, the computational complexity of attention is reduced from quadratic to linear, significantly improving the reasoning efficiency of LLMs. In addition, we propose a state-based reasoning strategy to mitigate the over-thinking issue caused by noisy reasoning steps. Extensive experiments across multiple datasets and model sizes demonstrate that our framework not only improves the reasoning efficiency of LLMs but also enhances their reasoning performance.
Marco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
TransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
Towards Widening The Distillation Bottleneck for Reasoning Models
Mar 03, 2025Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation--post-training on LRMs-generated data--is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning(SFT) and Reinforcement Learning(RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the construted data.
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement
Dec 05, 2024Large Language Models (LLMs) have achieved remarkable progress in recent years; however, their excellent performance is still largely limited to major world languages, primarily English. Many LLMs continue to face challenges with multilingual tasks, especially when it comes to low-resource languages. To address this issue, we introduced Marco-LLM: Massive multilingual training for cross-lingual enhancement LLM. We have collected a substantial amount of multilingual data for several low-resource languages and conducted extensive continual pre-training using the Qwen2 models. This effort has resulted in a multilingual LLM named Marco-LLM. Through comprehensive evaluations on various multilingual benchmarks, including MMMLU, AGIEval, Belebele, Flores-200, XCOPA and many others, Marco-LLM has demonstrated substantial improvements over state-of-the-art LLMs. Furthermore, Marco-LLM achieved substantial enhancements in any-to-any machine translation tasks, showing the effectiveness of our multilingual LLM. Marco-LLM is a pioneering multilingual LLM designed to not only perform exceptionally well in multilingual tasks, including low-resource languages, but also maintain strong performance in English and other major languages, closing the performance gap between high- and low-resource language capabilities. By bridging languages, this effort demonstrates our dedication to ensuring LLMs work accurately across various languages.
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Nov 21, 2024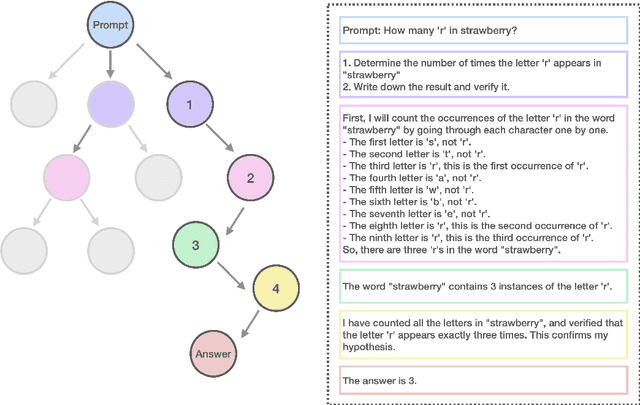

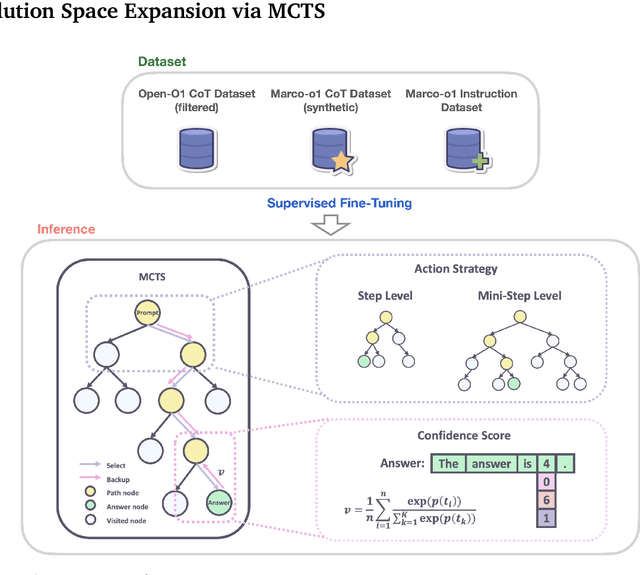
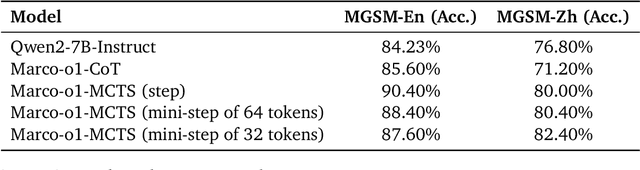
Currently OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mathematics, physics, and coding -- which are well-suited for reinforcement learning (RL) -- but also places greater emphasis on open-ended resolutions. We aim to address the question: "Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?" Marco-o1 is powered by Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), reflection mechanisms, and innovative reasoning strategies -- optimized for complex real-world problem-solving tasks.
Life Regression based Patch Slimming for Vision Transformers
Apr 11, 2023Vision transformers have achieved remarkable success in computer vision tasks by using multi-head self-attention modules to capture long-range dependencies within images. However, the high inference computation cost poses a new challenge. Several methods have been proposed to address this problem, mainly by slimming patches. In the inference stage, these methods classify patches into two classes, one to keep and the other to discard in multiple layers. This approach results in additional computation at every layer where patches are discarded, which hinders inference acceleration. In this study, we tackle the patch slimming problem from a different perspective by proposing a life regression module that determines the lifespan of each image patch in one go. During inference, the patch is discarded once the current layer index exceeds its life. Our proposed method avoids additional computation and parameters in multiple layers to enhance inference speed while maintaining competitive performance. Additionally, our approach requires fewer training epochs than other patch slimming methods.