 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
AI Agents and Agentic AI-Navigating a Plethora of Concepts for Future Manufacturing
Jul 02, 2025AI agents are autonomous systems designed to perceive, reason, and act within dynamic environments. With the rapid advancements in generative AI (GenAI), large language models (LLMs) and multimodal large language models (MLLMs) have significantly improved AI agents' capabilities in semantic comprehension, complex reasoning, and autonomous decision-making. At the same time, the rise of Agentic AI highlights adaptability and goal-directed autonomy in dynamic and complex environments. LLMs-based AI Agents (LLM-Agents), MLLMs-based AI Agents (MLLM-Agents), and Agentic AI contribute to expanding AI's capabilities in information processing, environmental perception, and autonomous decision-making, opening new avenues for smart manufacturing. However, the definitions, capability boundaries, and practical applications of these emerging AI paradigms in smart manufacturing remain unclear. To address this gap, this study systematically reviews the evolution of AI and AI agent technologies, examines the core concepts and technological advancements of LLM-Agents, MLLM-Agents, and Agentic AI, and explores their potential applications in and integration into manufacturing, along with the potential challenges they may face.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement
Dec 05, 2024Large Language Models (LLMs) have achieved remarkable progress in recent years; however, their excellent performance is still largely limited to major world languages, primarily English. Many LLMs continue to face challenges with multilingual tasks, especially when it comes to low-resource languages. To address this issue, we introduced Marco-LLM: Massive multilingual training for cross-lingual enhancement LLM. We have collected a substantial amount of multilingual data for several low-resource languages and conducted extensive continual pre-training using the Qwen2 models. This effort has resulted in a multilingual LLM named Marco-LLM. Through comprehensive evaluations on various multilingual benchmarks, including MMMLU, AGIEval, Belebele, Flores-200, XCOPA and many others, Marco-LLM has demonstrated substantial improvements over state-of-the-art LLMs. Furthermore, Marco-LLM achieved substantial enhancements in any-to-any machine translation tasks, showing the effectiveness of our multilingual LLM. Marco-LLM is a pioneering multilingual LLM designed to not only perform exceptionally well in multilingual tasks, including low-resource languages, but also maintain strong performance in English and other major languages, closing the performance gap between high- and low-resource language capabilities. By bridging languages, this effort demonstrates our dedication to ensuring LLMs work accurately across various languages.
AutoIE: An Automated Framework for Information Extraction from Scientific Literature
Jan 30, 2024In the rapidly evolving field of scientific research, efficiently extracting key information from the burgeoning volume of scientific papers remains a formidable challenge. This paper introduces an innovative framework designed to automate the extraction of vital data from scientific PDF documents, enabling researchers to discern future research trajectories more readily. AutoIE uniquely integrates four novel components: (1) A multi-semantic feature fusion-based approach for PDF document layout analysis; (2) Advanced functional block recognition in scientific texts; (3) A synergistic technique for extracting and correlating information on molecular sieve synthesis; (4) An online learning paradigm tailored for molecular sieve literature. Our SBERT model achieves high Marco F1 scores of 87.19 and 89.65 on CoNLL04 and ADE datasets. In addition, a practical application of AutoIE in the petrochemical molecular sieve synthesis domain demonstrates its efficacy, evidenced by an impressive 78\% accuracy rate. This research paves the way for enhanced data management and interpretation in molecular sieve synthesis. It is a valuable asset for seasoned experts and newcomers in this specialized field.
DiffuseGAE: Controllable and High-fidelity Image Manipulation from Disentangled Representation
Jul 12, 2023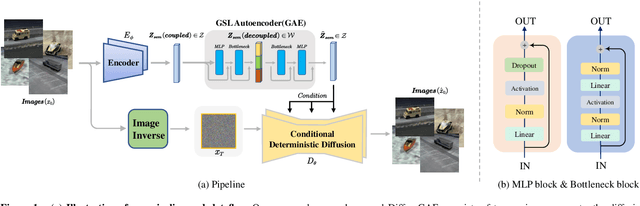
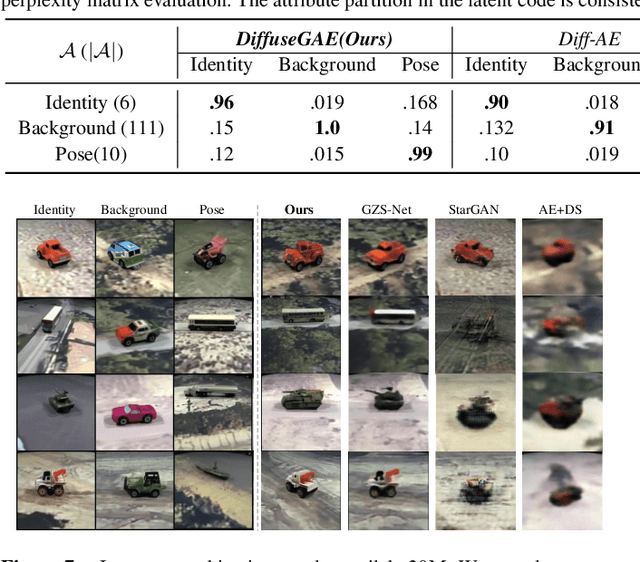
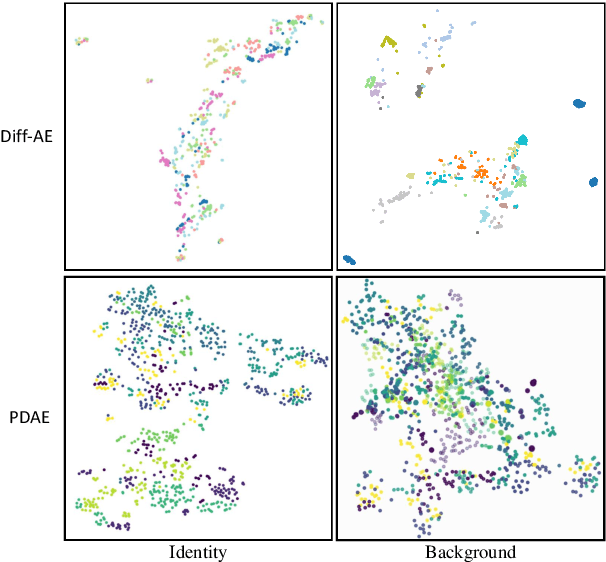
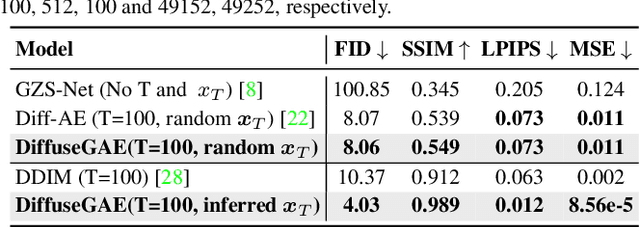
Diffusion probabilistic models (DPMs) have shown remarkable results on various image synthesis tasks such as text-to-image generation and image inpainting. However, compared to other generative methods like VAEs and GANs, DPMs lack a low-dimensional, interpretable, and well-decoupled latent code. Recently, diffusion autoencoders (Diff-AE) were proposed to explore the potential of DPMs for representation learning via autoencoding. Diff-AE provides an accessible latent space that exhibits remarkable interpretability, allowing us to manipulate image attributes based on latent codes from the space. However, previous works are not generic as they only operated on a few limited attributes. To further explore the latent space of Diff-AE and achieve a generic editing pipeline, we proposed a module called Group-supervised AutoEncoder(dubbed GAE) for Diff-AE to achieve better disentanglement on the latent code. Our proposed GAE has trained via an attribute-swap strategy to acquire the latent codes for multi-attribute image manipulation based on examples. We empirically demonstrate that our method enables multiple-attributes manipulation and achieves convincing sample quality and attribute alignments, while significantly reducing computational requirements compared to pixel-based approaches for representational decoupling. Code will be released soon.
MmWave Radar and Vision Fusion for Object Detection in Autonomous Driving: A Review
Aug 12, 2021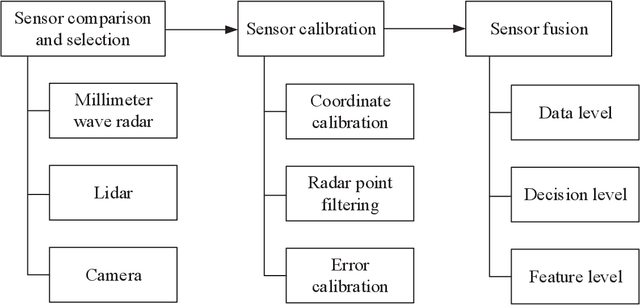
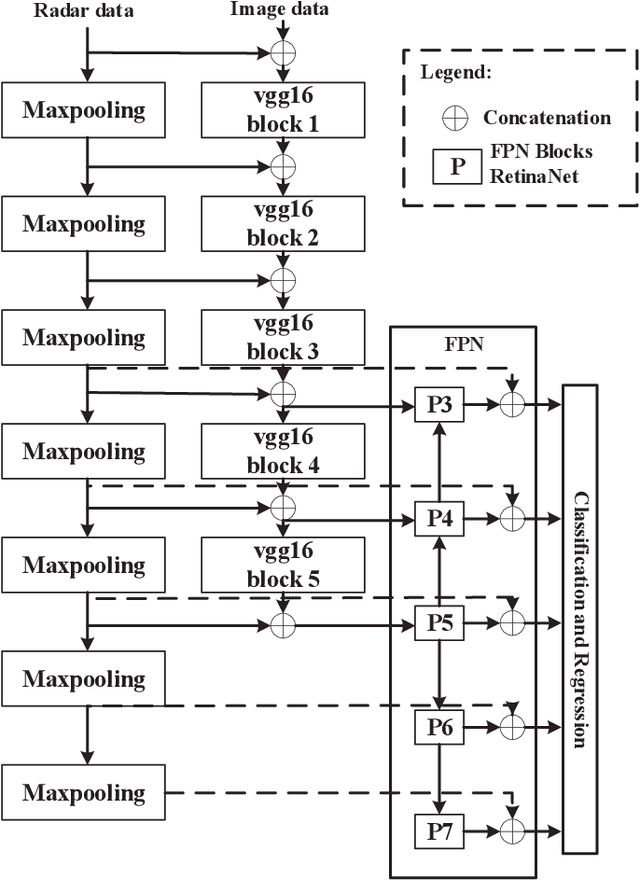
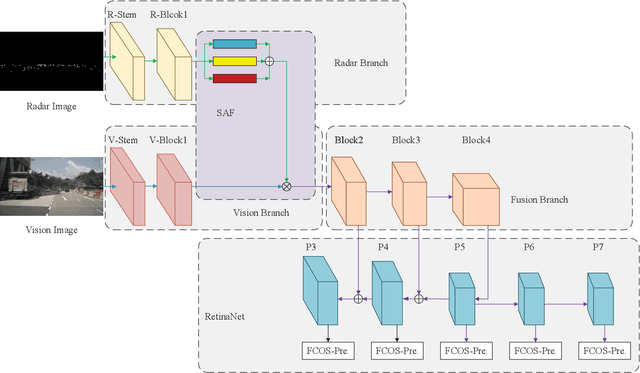
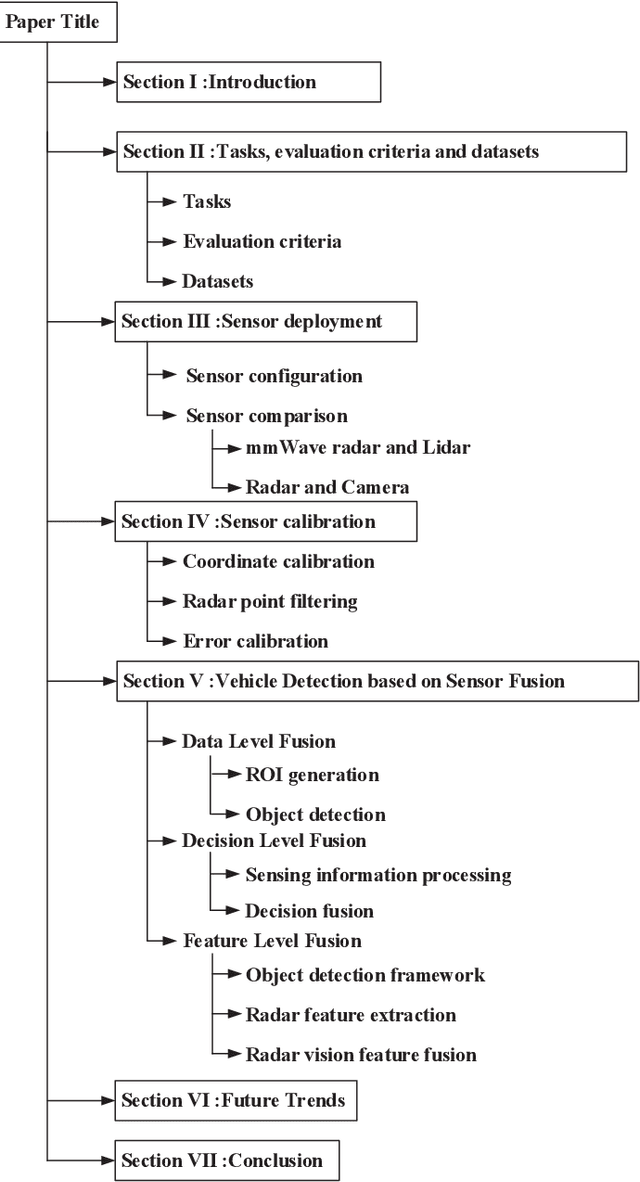
With autonomous driving developing in a booming stage, accurate object detection in complex scenarios attract wide attention to ensure the safety of autonomous driving. Millimeter wave (mmWave) radar and vision fusion is a mainstream solution for accurate obstacle detection. This article presents a detailed survey on mmWave radar and vision fusion based obstacle detection methods. Firstly, we introduce the tasks, evaluation criteria and datasets of object detection for autonomous driving. Then, the process of mmWave radar and vision fusion is divided into three parts: sensor deployment, sensor calibration and sensor fusion, which are reviewed comprehensively. Especially, we classify the fusion methods into data level, decision level and feature level fusion methods. Besides, we introduce the fusion of lidar and vision in autonomous driving in the aspects of obstacle detection, object classification and road segmentation, which is promising in the future. Finally, we summarize this article.
Detecting Cyberattacks in Industrial Control Systems Using Online Learning Algorithms
Dec 08, 2019
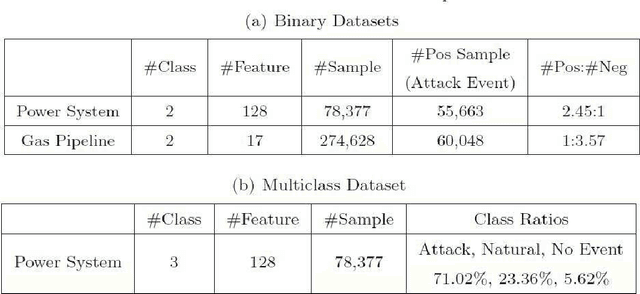
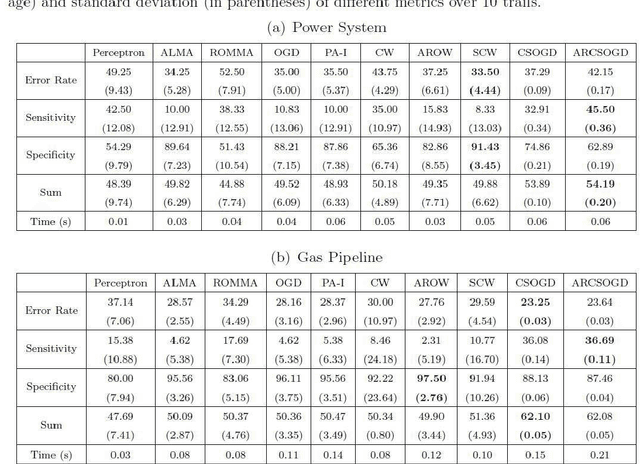

Industrial control systems are critical to the operation of industrial facilities, especially for critical infrastructures, such as refineries, power grids, and transportation systems. Similar to other information systems, a significant threat to industrial control systems is the attack from cyberspace---the offensive maneuvers launched by "anonymous" in the digital world that target computer-based assets with the goal of compromising a system's functions or probing for information. Owing to the importance of industrial control systems, and the possibly devastating consequences of being attacked, significant endeavors have been attempted to secure industrial control systems from cyberattacks. Among them are intrusion detection systems that serve as the first line of defense by monitoring and reporting potentially malicious activities. Classical machine-learning-based intrusion detection methods usually generate prediction models by learning modest-sized training samples all at once. Such approach is not always applicable to industrial control systems, as industrial control systems must process continuous control commands with limited computational resources in a nonstop way. To satisfy such requirements, we propose using online learning to learn prediction models from the controlling data stream. We introduce several state-of-the-art online learning algorithms categorically, and illustrate their efficacies on two typically used testbeds---power system and gas pipeline. Further, we explore a new cost-sensitive online learning algorithm to solve the class-imbalance problem that is pervasive in industrial intrusion detection systems. Our experimental results indicate that the proposed algorithm can achieve an overall improvement in the detection rate of cyberattacks in industrial control systems.