 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Did It Go Wrong? Capability-Oriented Failure Attribution for Vision-and-Language Navigation Agents
Apr 28, 2026Embodied agents in safety-critical applications such as Vision-Language Navigation (VLN) rely on multiple interdependent capabilities (e.g., perception, memory, planning, decision), making failures difficult to localize and attribute. Existing testing methods are largely system-level and provide limited insight into which capability deficiencies cause task failures. We propose a capability-oriented testing approach that enables failure detection and attribution by combining (1) adaptive test case generation via seed selection and mutation, (2) capability oracles for identifying capability-specific errors, and (3) a feedback mechanism that attributes failures to capabilities and guides further test generation. Experiments show that our method discovers more failure cases and more accurately pinpoints capability-level deficiencies than state-of-the-art baselines, providing more interpretable and actionable guidance for improving embodied agents.
AutoIE: An Automated Framework for Information Extraction from Scientific Literature
Jan 30, 2024In the rapidly evolving field of scientific research, efficiently extracting key information from the burgeoning volume of scientific papers remains a formidable challenge. This paper introduces an innovative framework designed to automate the extraction of vital data from scientific PDF documents, enabling researchers to discern future research trajectories more readily. AutoIE uniquely integrates four novel components: (1) A multi-semantic feature fusion-based approach for PDF document layout analysis; (2) Advanced functional block recognition in scientific texts; (3) A synergistic technique for extracting and correlating information on molecular sieve synthesis; (4) An online learning paradigm tailored for molecular sieve literature. Our SBERT model achieves high Marco F1 scores of 87.19 and 89.65 on CoNLL04 and ADE datasets. In addition, a practical application of AutoIE in the petrochemical molecular sieve synthesis domain demonstrates its efficacy, evidenced by an impressive 78\% accuracy rate. This research paves the way for enhanced data management and interpretation in molecular sieve synthesis. It is a valuable asset for seasoned experts and newcomers in this specialized field.
VTLayout: Fusion of Visual and Text Features for Document Layout Analysis
Aug 12, 2021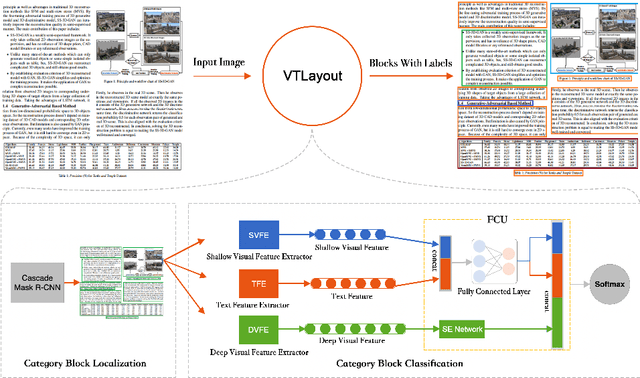
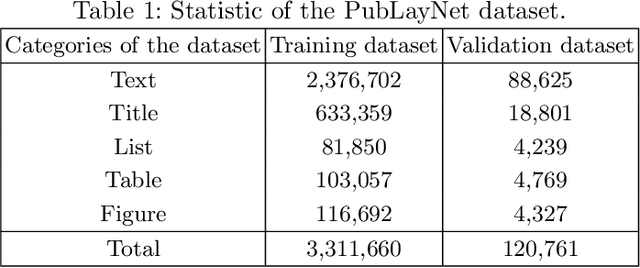
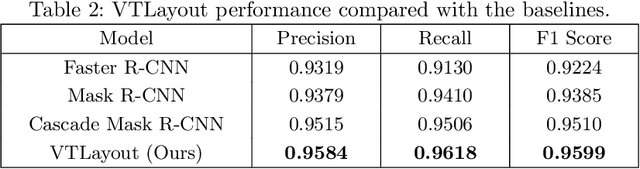
Documents often contain complex physical structures, which make the Document Layout Analysis (DLA) task challenging. As a pre-processing step for content extraction, DLA has the potential to capture rich information in historical or scientific documents on a large scale. Although many deep-learning-based methods from computer vision have already achieved excellent performance in detecting \emph{Figure} from documents, they are still unsatisfactory in recognizing the \emph{List}, \emph{Table}, \emph{Text} and \emph{Title} category blocks in DLA. This paper proposes a VTLayout model fusing the documents' deep visual, shallow visual, and text features to localize and identify different category blocks. The model mainly includes two stages, and the three feature extractors are built in the second stage. In the first stage, the Cascade Mask R-CNN model is applied directly to localize all category blocks of the documents. In the second stage, the deep visual, shallow visual, and text features are extracted for fusion to identify the category blocks of documents. As a result, we strengthen the classification power of different category blocks based on the existing localization technique. The experimental results show that the identification capability of the VTLayout is superior to the most advanced method of DLA based on the PubLayNet dataset, and the F1 score is as high as 0.9599.
PEL-BERT: A Joint Model for Protocol Entity Linking
Jan 28, 2020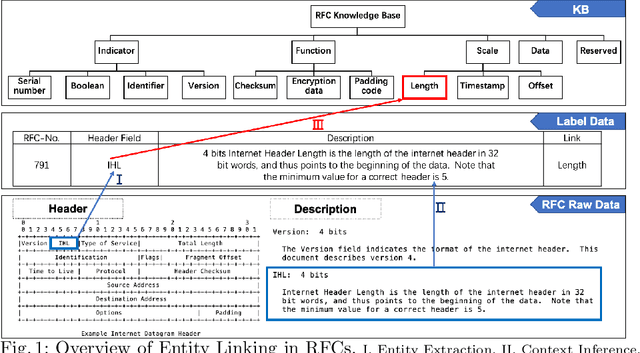
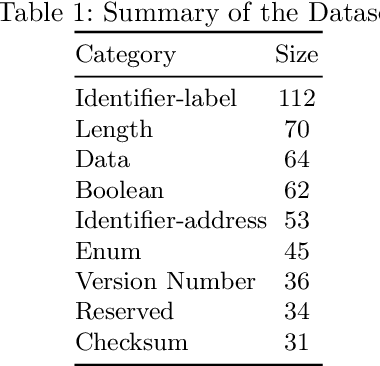


Pre-trained models such as BERT are widely used in NLP tasks and are fine-tuned to improve the performance of various NLP tasks consistently. Nevertheless, the fine-tuned BERT model trained on our protocol corpus still has a weak performance on the Entity Linking (EL) task. In this paper, we propose a model that joints a fine-tuned language model with an RFC Domain Model. Firstly, we design a Protocol Knowledge Base as the guideline for protocol EL. Secondly, we propose a novel model, PEL-BERT, to link named entities in protocols to categories in Protocol Knowledge Base. Finally, we conduct a comprehensive study on the performance of pre-trained language models on descriptive texts and abstract concepts. Experimental results demonstrate that our model achieves state-of-the-art performance in EL on our annotated dataset, outperforming all the baselines.