 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Backdoor Adversarial Unlearning through the Lens of Catastrophic Forgetting in Continual Learning
Jun 12, 2026Existing studies reveal that current backdoor defenses exhibit limited robustness and often fail against specific types of attacks. More concerningly, prevailing safety tuning strategies tend to provide only superficial safety protection, as they fall short of completely eliminating the backdoor effects. In this work, we present a novel formulation of backdoor learning and unlearning as a sequential, three-stage process from a continual learning perspective. Within this framework, we formally define complete backdoor unlearning and further derive the necessary conditions for achieving it based on the mechanism of catastrophic forgetting. Guided by these insights, we propose Blind Inversion-Backdoor Adversarial Unlearning (BI-BAU), which formulates the generation of adversarial examples satisfying the unlearning conditions as a blind inversion problem. We solve this by integrating the bi-level optimization process of adversarial training into an Expectation-Maximization (EM) algorithm framework to optimize the maximum a posteriori (MAP) objective. Furthermore, BI-BAU is extended to untargeted adversarial scenarios with unknown target classes, as well as to multi-modal contrastive learning tasks, enhancing its applicability to real-world deployment scenarios where pre-trained models may be compromised. Extensive experiments demonstrate that our method exhibits general applicability across a wide spectrum of backdoor attacks and can effectively and thoroughly eliminate the backdoor effects from a backdoor model.
Showing Many Labels in Multi-label Classification Models: An Empirical Study of Adversarial Examples
Sep 26, 2024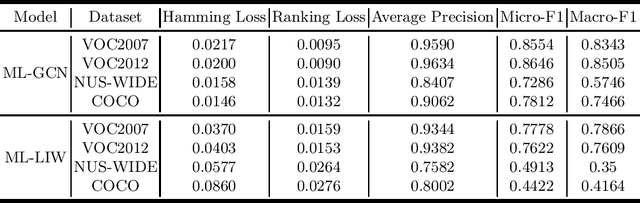
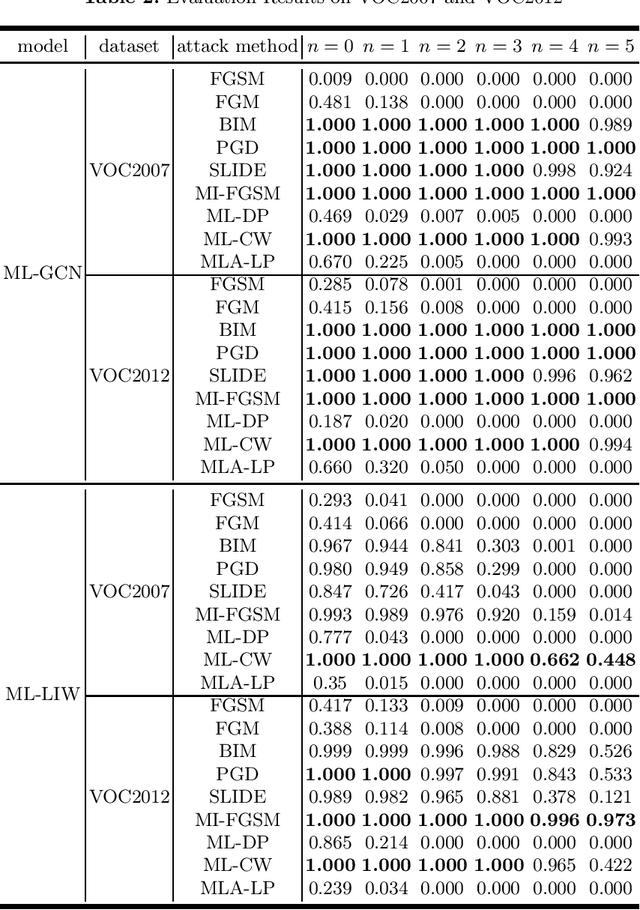
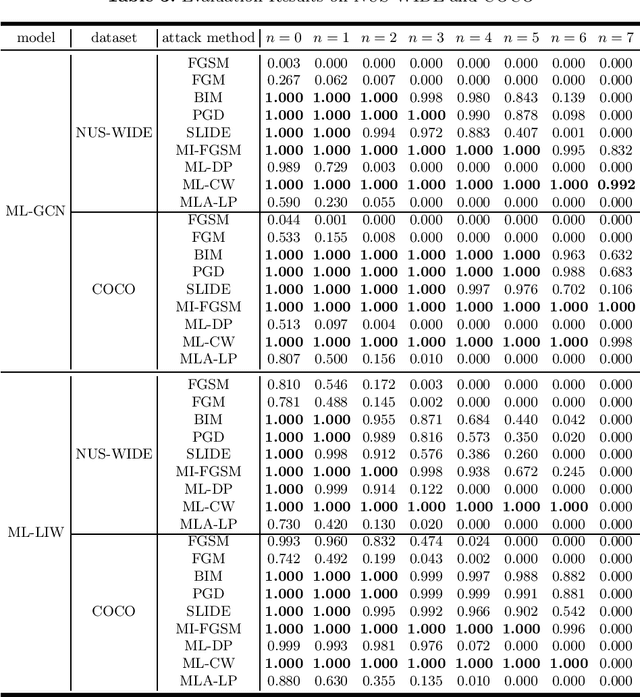
With the rapid development of Deep Neural Networks (DNNs), they have been applied in numerous fields. However, research indicates that DNNs are susceptible to adversarial examples, and this is equally true in the multi-label domain. To further investigate multi-label adversarial examples, we introduce a novel type of attacks, termed "Showing Many Labels". The objective of this attack is to maximize the number of labels included in the classifier's prediction results. In our experiments, we select nine attack algorithms and evaluate their performance under "Showing Many Labels". Eight of the attack algorithms were adapted from the multi-class environment to the multi-label environment, while the remaining one was specifically designed for the multi-label environment. We choose ML-LIW and ML-GCN as target models and train them on four popular multi-label datasets: VOC2007, VOC2012, NUS-WIDE, and COCO. We record the success rate of each algorithm when it shows the expected number of labels in eight different scenarios. Experimental results indicate that under the "Showing Many Labels", iterative attacks perform significantly better than one-step attacks. Moreover, it is possible to show all labels in the dataset.
USTC FLICAR: A Multisensor Fusion Dataset of LiDAR-Inertial-Camera for Heavy-duty Autonomous Aerial Work Robots
Apr 04, 2023
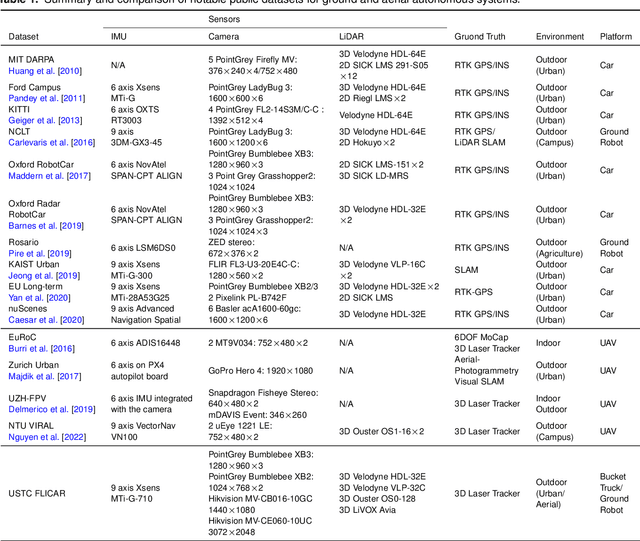

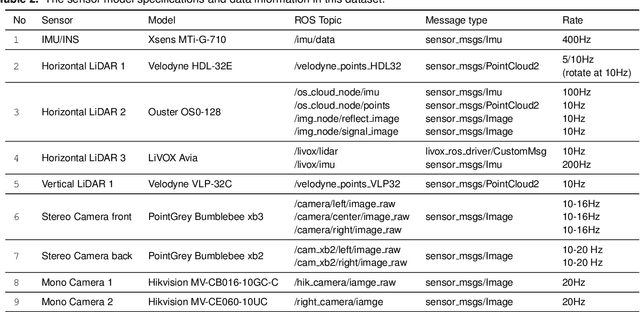
In this paper, we present the USTC FLICAR Dataset, which is dedicated to the development of simultaneous localization and mapping and precise 3D reconstruction of the workspace for heavy-duty autonomous aerial work robots. In recent years, numerous public datasets have played significant roles in the advancement of autonomous cars and unmanned aerial vehicles (UAVs). However, these two platforms differ from aerial work robots: UAVs are limited in their payload capacity, while cars are restricted to two-dimensional movements. To fill this gap, we create the Giraffe mapping robot based on a bucket truck, which is equipped with a variety of well-calibrated and synchronized sensors: four 3D LiDARs, two stereo cameras, two monocular cameras, Inertial Measurement Units (IMUs), and a GNSS/INS system. A laser tracker is used to record the millimeter-level ground truth positions. We also make its ground twin, the Okapi mapping robot, to gather data for comparison. The proposed dataset extends the typical autonomous driving sensing suite to aerial scenes. Therefore, the dataset is named FLICAR to denote flying cars. We believe this dataset can also represent the flying car scenarios, specifically the takeoff and landing of VTOL (Vertical Takeoff and Landing) flying cars. The dataset is available for download at: https://ustc-flicar.github.io.
PEL-BERT: A Joint Model for Protocol Entity Linking
Jan 28, 2020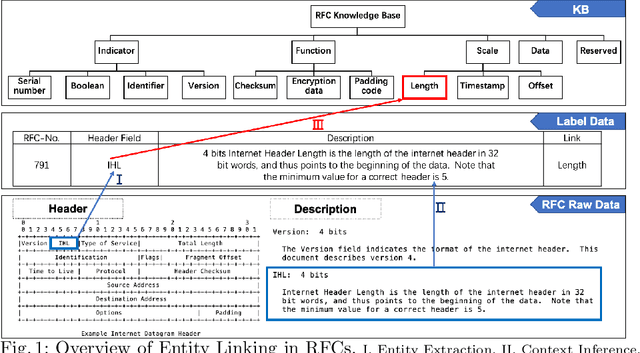
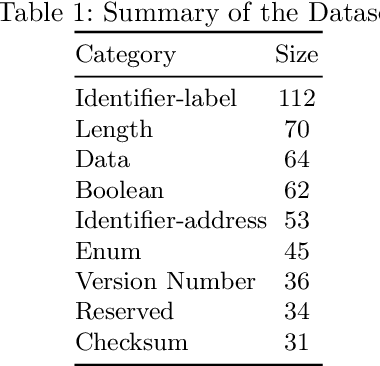


Pre-trained models such as BERT are widely used in NLP tasks and are fine-tuned to improve the performance of various NLP tasks consistently. Nevertheless, the fine-tuned BERT model trained on our protocol corpus still has a weak performance on the Entity Linking (EL) task. In this paper, we propose a model that joints a fine-tuned language model with an RFC Domain Model. Firstly, we design a Protocol Knowledge Base as the guideline for protocol EL. Secondly, we propose a novel model, PEL-BERT, to link named entities in protocols to categories in Protocol Knowledge Base. Finally, we conduct a comprehensive study on the performance of pre-trained language models on descriptive texts and abstract concepts. Experimental results demonstrate that our model achieves state-of-the-art performance in EL on our annotated dataset, outperforming all the baselines.