 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Embodied Intelligence: Graph Neural Network--Driven Co-Design of Morphology and Control in Soft Robotics
Mar 20, 2026The intelligent behavior of robots does not emerge solely from control systems, but from the tight coupling between body and brain, a principle known as embodied intelligence. Designing soft robots that leverage this interaction remains a significant challenge, particularly when morphology and control require simultaneous optimization. A significant obstacle in this co-design process is that morphological evolution can disrupt learned control strategies, making it difficult to reuse or adapt existing knowledge. We address this by develop a Graph Neural Network-based approach for the co-design of morphology and controller. Each robot is represented as a graph, with a graph attention network (GAT) encoding node features and a pooled representation passed through a multilayer perceptron (MLP) head to produce actuator commands or value estimates. During evolution, inheritance follows a topology-consistent mapping: shared GAT layers are reused, MLP hidden layers are transferred intact, matched actuator outputs are copied, and unmatched ones are randomly initialized and fine-tuned. This morphology-aware policy class lets the controller adapt when the body mutates. On the benchmark, our GAT-based approach achieves higher final fitness and stronger adaptability to morphological variations compared to traditional MLP-only co-design methods. These results indicate that graph-structured policies provide a more effective interface between evolving morphologies and control for embodied intelligence.
Landscape-aware Automated Algorithm Design: An Efficient Framework for Real-world Optimization
Feb 04, 2026The advent of Large Language Models (LLMs) has opened new frontiers in automated algorithm design, giving rise to numerous powerful methods. However, these approaches retain critical limitations: they require extensive evaluation of the target problem to guide the search process, making them impractical for real-world optimization tasks, where each evaluation consumes substantial computational resources. This research proposes an innovative and efficient framework that decouples algorithm discovery from high-cost evaluation. Our core innovation lies in combining a Genetic Programming (GP) function generator with an LLM-driven evolutionary algorithm designer. The evolutionary direction of the GP-based function generator is guided by the similarity between the landscape characteristics of generated proxy functions and those of real-world problems, ensuring that algorithms discovered via proxy functions exhibit comparable performance on real-world problems. Our method enables deep exploration of the algorithmic space before final validation while avoiding costly real-world evaluations. We validated the framework's efficacy across multiple real-world problems, demonstrating its ability to discover high-performance algorithms while substantially reducing expensive evaluations. This approach shows a path to apply LLM-based automated algorithm design to computationally intensive real-world optimization challenges.
Unifying Search and Recommendation in LLMs via Gradient Multi-Subspace Tuning
Jan 14, 2026Search and recommendation (S&R) are core to online platforms, addressing explicit intent through queries and modeling implicit intent from behaviors, respectively. Their complementary roles motivate a unified modeling paradigm. Early studies to unify S&R adopt shared encoders with task-specific heads, while recent efforts reframe item ranking in both S&R as conditional generation. The latter holds particular promise, enabling end-to-end optimization and leveraging the semantic understanding of LLMs. However, existing methods rely on full fine-tuning, which is computationally expensive and limits scalability. Parameter-efficient fine-tuning (PEFT) offers a more practical alternative but faces two critical challenges in unifying S&R: (1) gradient conflicts across tasks due to divergent optimization objectives, and (2) shifts in user intent understanding caused by overfitting to fine-tuning data, which distort general-domain knowledge and weaken LLM reasoning. To address the above issues, we propose Gradient Multi-Subspace Tuning (GEMS), a novel framework that unifies S&R with LLMs while alleviating gradient conflicts and preserving general-domain knowledge. GEMS introduces (1) \textbf{Multi-Subspace Decomposition}, which disentangles shared and task-specific optimization signals into complementary low-rank subspaces, thereby reducing destructive gradient interference, and (2) \textbf{Null-Space Projection}, which constrains parameter updates to a subspace orthogonal to the general-domain knowledge space, mitigating shifts in user intent understanding. Extensive experiments on benchmark datasets show that GEMS consistently outperforms the state-of-the-art baselines across both search and recommendation tasks, achieving superior effectiveness.
Transfer Learning of Surrogate Models: Integrating Domain Warping and Affine Transformations
Jan 30, 2025



Surrogate models provide efficient alternatives to computationally demanding real-world processes but often require large datasets for effective training. A promising solution to this limitation is the transfer of pre-trained surrogate models to new tasks. Previous studies have investigated the transfer of differentiable and non-differentiable surrogate models, typically assuming an affine transformation between the source and target functions. This paper extends previous research by addressing a broader range of transformations, including linear and nonlinear variations. Specifically, we consider the combination of an unknown input warping, such as one modelled by the beta cumulative distribution function, with an unspecified affine transformation. Our approach achieves transfer learning by employing a limited number of data points from the target task to optimize these transformations, minimizing empirical loss on the transfer dataset. We validate the proposed method on the widely used Black-Box Optimization Benchmark (BBOB) testbed and a real-world transfer learning task from the automobile industry. The results underscore the significant advantages of the approach, revealing that the transferred surrogate significantly outperforms both the original surrogate and the one built from scratch using the transfer dataset, particularly in data-scarce scenarios.
Transfer Learning of Surrogate Models via Domain Affine Transformation Across Synthetic and Real-World Benchmarks
Jan 23, 2025



Surrogate models are frequently employed as efficient substitutes for the costly execution of real-world processes. However, constructing a high-quality surrogate model often demands extensive data acquisition. A solution to this issue is to transfer pre-trained surrogate models for new tasks, provided that certain invariances exist between tasks. This study focuses on transferring non-differentiable surrogate models (e.g., random forest) from a source function to a target function, where we assume their domains are related by an unknown affine transformation, using only a limited amount of transfer data points evaluated on the target. Previous research attempts to tackle this challenge for differentiable models, e.g., Gaussian process regression, which minimizes the empirical loss on the transfer data by tuning the affine transformations. In this paper, we extend the previous work to the random forest model and assess its effectiveness on a widely-used artificial problem set - Black-Box Optimization Benchmark (BBOB) testbed, and on four real-world transfer learning problems. The results highlight the significant practical advantages of the proposed method, particularly in reducing both the data requirements and computational costs of training surrogate models for complex real-world scenarios.
A Pipeline for Analysing Grant Applications
Oct 30, 2022



Data mining techniques can transform massive amounts of unstructured data into quantitative data that quickly reveal insights, trends, and patterns behind the original data. In this paper, a data mining model is applied to analyse the 2019 grant applications submitted to an Australian Government research funding agency to investigate whether grant schemes successfully identifies innovative project proposals, as intended. The grant applications are peer-reviewed research proposals that include specific ``innovation and creativity'' (IC) scores assigned by reviewers. In addition to predicting the IC score for each research proposal, we are particularly interested in understanding the vocabulary of innovative proposals. In order to solve this problem, various data mining models and feature encoding algorithms are studied and explored. As a result, we propose a model with the best performance, a Random Forest (RF) classifier over documents encoded with features denoting the presence or absence of unigrams. In specific, the unigram terms are encoded by a modified Term Frequency - Inverse Document Frequency (TF-IDF) algorithm, which only implements the IDF part of TF-IDF. Besides the proposed model, this paper also presents a rigorous experimental pipeline for analysing grant applications, and the experimental results prove its feasibility.
VTLayout: Fusion of Visual and Text Features for Document Layout Analysis
Aug 12, 2021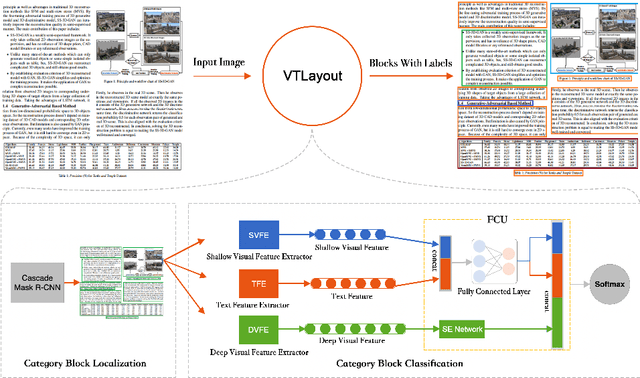
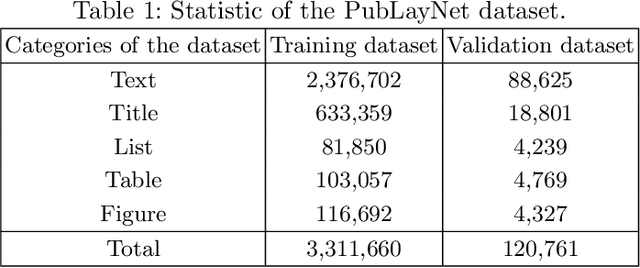
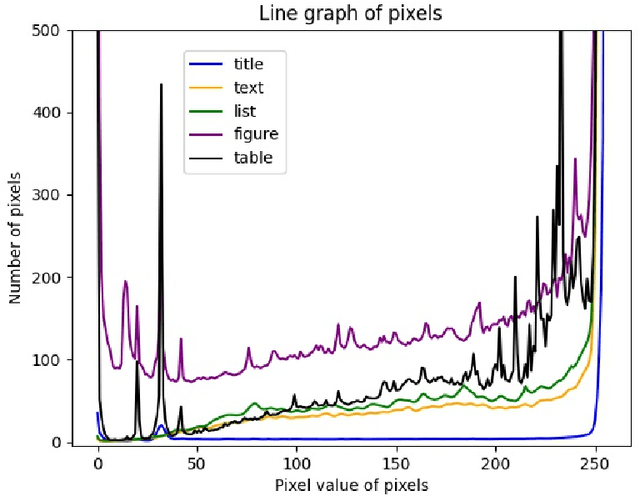
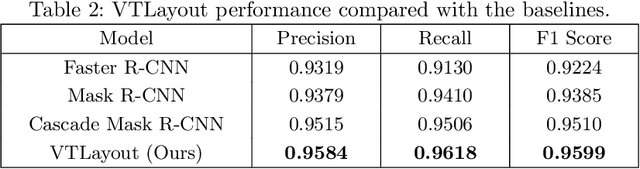
Documents often contain complex physical structures, which make the Document Layout Analysis (DLA) task challenging. As a pre-processing step for content extraction, DLA has the potential to capture rich information in historical or scientific documents on a large scale. Although many deep-learning-based methods from computer vision have already achieved excellent performance in detecting \emph{Figure} from documents, they are still unsatisfactory in recognizing the \emph{List}, \emph{Table}, \emph{Text} and \emph{Title} category blocks in DLA. This paper proposes a VTLayout model fusing the documents' deep visual, shallow visual, and text features to localize and identify different category blocks. The model mainly includes two stages, and the three feature extractors are built in the second stage. In the first stage, the Cascade Mask R-CNN model is applied directly to localize all category blocks of the documents. In the second stage, the deep visual, shallow visual, and text features are extracted for fusion to identify the category blocks of documents. As a result, we strengthen the classification power of different category blocks based on the existing localization technique. The experimental results show that the identification capability of the VTLayout is superior to the most advanced method of DLA based on the PubLayNet dataset, and the F1 score is as high as 0.9599.