 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
May 24, 2024


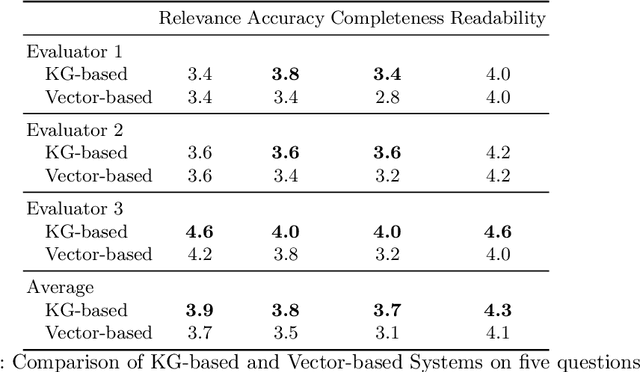
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023

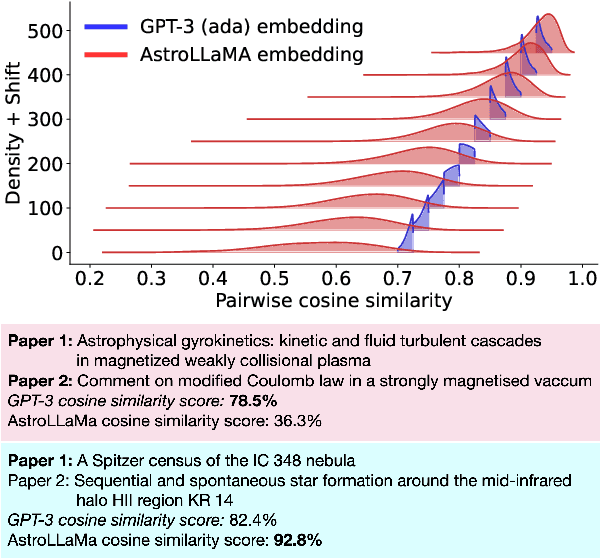
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Syntactic Complexity Identification, Measurement, and Reduction Through Controlled Syntactic Simplification
Apr 16, 2023
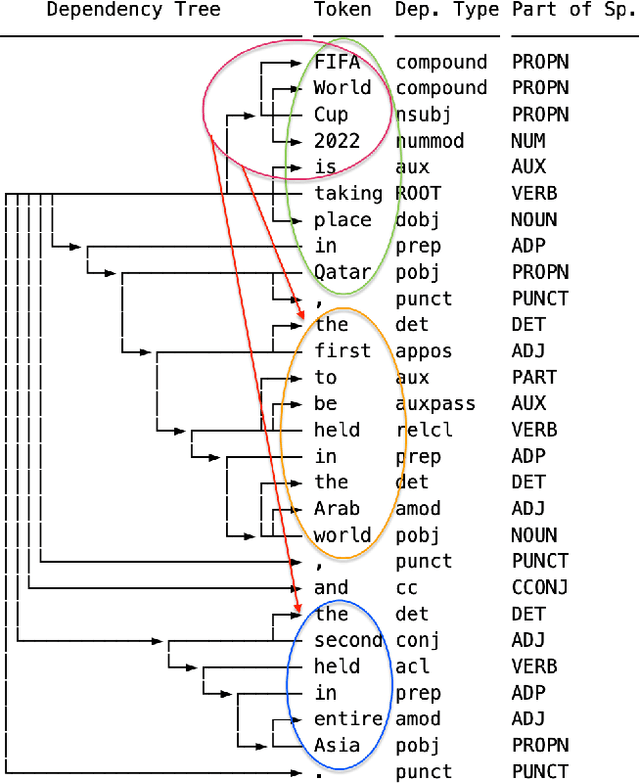

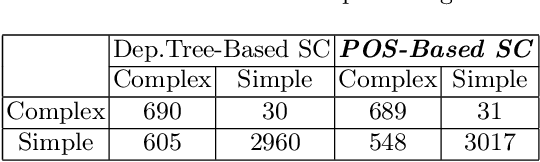
Text simplification is one of the domains in Natural Language Processing (NLP) that offers an opportunity to understand the text in a simplified manner for exploration. However, it is always hard to understand and retrieve knowledge from unstructured text, which is usually in the form of compound and complex sentences. There are state-of-the-art neural network-based methods to simplify the sentences for improved readability while replacing words with plain English substitutes and summarising the sentences and paragraphs. In the Knowledge Graph (KG) creation process from unstructured text, summarising long sentences and substituting words is undesirable since this may lead to information loss. However, KG creation from text requires the extraction of all possible facts (triples) with the same mentions as in the text. In this work, we propose a controlled simplification based on the factual information in a sentence, i.e., triple. We present a classical syntactic dependency-based approach to split and rephrase a compound and complex sentence into a set of simplified sentences. This simplification process will retain the original wording with a simple structure of possible domain facts in each sentence, i.e., triples. The paper also introduces an algorithm to identify and measure a sentence's syntactic complexity (SC), followed by reduction through a controlled syntactic simplification process. Last, an experiment for a dataset re-annotation is also conducted through GPT3; we aim to publish this refined corpus as a resource. This work is accepted and presented in International workshop on Learning with Knowledge Graphs (IWLKG) at WSDM-2023 Conference. The code and data is available at www.github.com/sallmanm/SynSim.
A Pipeline for Analysing Grant Applications
Oct 30, 2022



Data mining techniques can transform massive amounts of unstructured data into quantitative data that quickly reveal insights, trends, and patterns behind the original data. In this paper, a data mining model is applied to analyse the 2019 grant applications submitted to an Australian Government research funding agency to investigate whether grant schemes successfully identifies innovative project proposals, as intended. The grant applications are peer-reviewed research proposals that include specific ``innovation and creativity'' (IC) scores assigned by reviewers. In addition to predicting the IC score for each research proposal, we are particularly interested in understanding the vocabulary of innovative proposals. In order to solve this problem, various data mining models and feature encoding algorithms are studied and explored. As a result, we propose a model with the best performance, a Random Forest (RF) classifier over documents encoded with features denoting the presence or absence of unigrams. In specific, the unigram terms are encoded by a modified Term Frequency - Inverse Document Frequency (TF-IDF) algorithm, which only implements the IDF part of TF-IDF. Besides the proposed model, this paper also presents a rigorous experimental pipeline for analysing grant applications, and the experimental results prove its feasibility.
TNNT: The Named Entity Recognition Toolkit
Aug 31, 2021
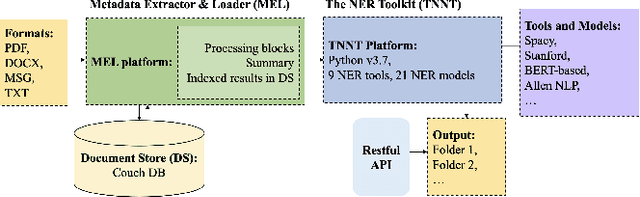
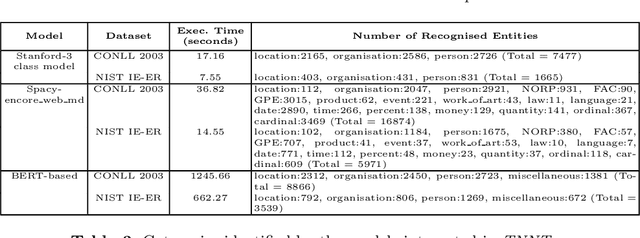
Extraction of categorised named entities from text is a complex task given the availability of a variety of Named Entity Recognition (NER) models and the unstructured information encoded in different source document formats. Processing the documents to extract text, identifying suitable NER models for a task, and obtaining statistical information is important in data analysis to make informed decisions. This paper presents TNNT, a toolkit that automates the extraction of categorised named entities from unstructured information encoded in source documents, using diverse state-of-the-art Natural Language Processing (NLP) tools and NER models. TNNT integrates 21 different NER models as part of a Knowledge Graph Construction Pipeline (KGCP) that takes a document set as input and processes it based on the defined settings, applying the selected blocks of NER models to output the results. The toolkit generates all results with an integrated summary of the extracted entities, enabling enhanced data analysis to support the KGCP, and also, to aid further NLP tasks.