 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWARE-NET: Adaptive Weighted Averaging for Robust Ensemble Network in Deepfake Detection
May 01, 2025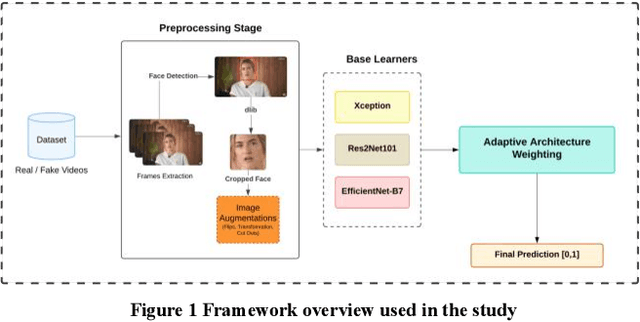
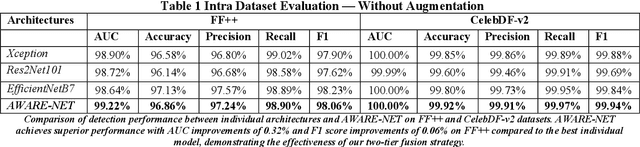
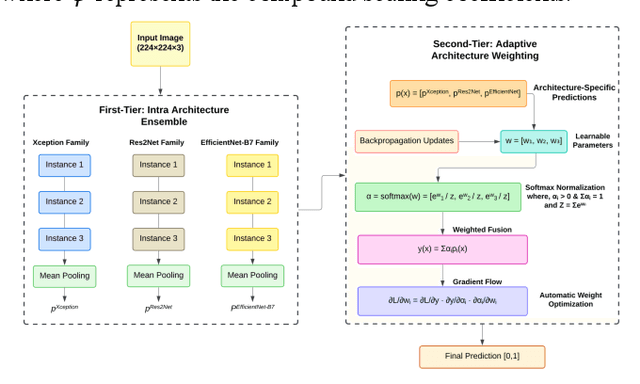
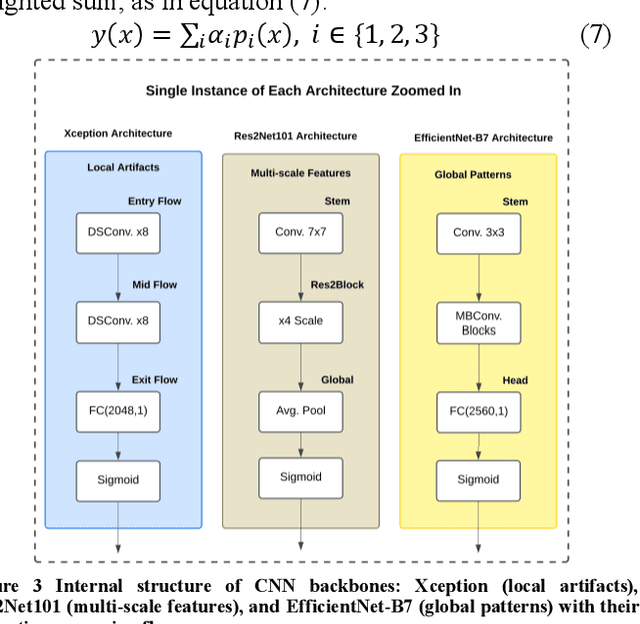
Deepfake detection has become increasingly important due to the rise of synthetic media, which poses significant risks to digital identity and cyber presence for security and trust. While multiple approaches have improved detection accuracy, challenges remain in achieving consistent performance across diverse datasets and manipulation types. In response, we propose a novel two-tier ensemble framework for deepfake detection based on deep learning that hierarchically combines multiple instances of three state-of-the-art architectures: Xception, Res2Net101, and EfficientNet-B7. Our framework employs a unique approach where each architecture is instantiated three times with different initializations to enhance model diversity, followed by a learnable weighting mechanism that dynamically combines their predictions. Unlike traditional fixed-weight ensembles, our first-tier averages predictions within each architecture family to reduce model variance, while the second tier learns optimal contribution weights through backpropagation, automatically adjusting each architecture's influence based on their detection reliability. Our experiments achieved state-of-the-art intra-dataset performance with AUC scores of 99.22% (FF++) and 100.00% (CelebDF-v2), and F1 scores of 98.06% (FF++) and 99.94% (CelebDF-v2) without augmentation. With augmentation, we achieve AUC scores of 99.47% (FF++) and 100.00% (CelebDF-v2), and F1 scores of 98.43% (FF++) and 99.95% (CelebDF-v2). The framework demonstrates robust cross-dataset generalization, achieving AUC scores of 88.20% and 72.52%, and F1 scores of 93.16% and 80.62% in cross-dataset evaluations.
Multi-population Differential Evolution for RSS based Cooperative Localization in Wireless Sensor Networks with Limited Communication Range
Dec 27, 2024This paper presents a novel approach to deal with the cooperative localization problem in wireless sensor networks based on received signal strength measurements. In cooperative scenarios, the cost function of the localization problem becomes increasingly nonlinear and nonconvex due to the heightened interaction between sensor nodes, making the estimation of the positions of the target nodes more challenging. Although most of existing cooperative localization algorithms assure acceptable localization accuracy, their computational complexity increases dramatically, which may restrict their applicability. To reduce the computational complexity and provide competitive localization accuracy at the same time, we propose a localization algorithm based on the differential evolution with multiple populations, opposite-based learning, redirection, and anchoring. In this work, the cooperative localization cost function is split into several simpler cost functions, each of which accounts only for one individual target node. Then, each cost function is solved by a dedicated population of the proposed algorithm. In addition, an enhanced version of the proposed algorithm which incorporates the population midpoint scheme for further improvement in the localization accuracy is devised. Simulation results demonstrate that the proposed algorithms provide comparative localization accuracy with much lower computational complexity compared with the state-of-the-art algorithms.
On the Robustness of Malware Detectors to Adversarial Samples
Aug 05, 2024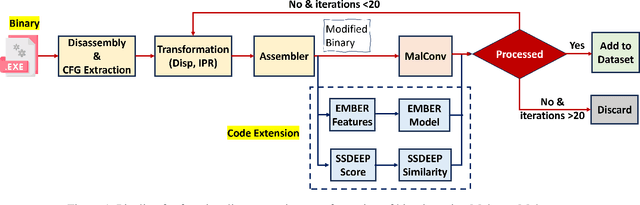
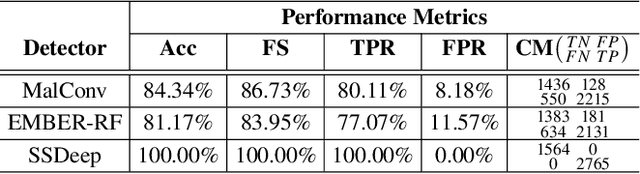
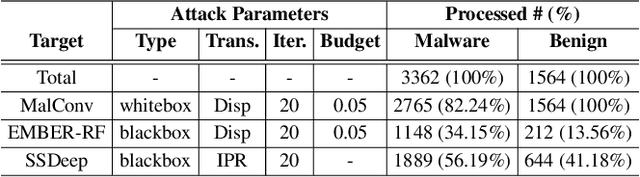
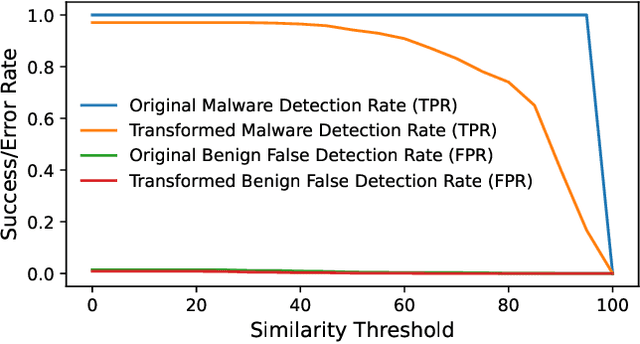
Adversarial examples add imperceptible alterations to inputs with the objective to induce misclassification in machine learning models. They have been demonstrated to pose significant challenges in domains like image classification, with results showing that an adversarially perturbed image to evade detection against one classifier is most likely transferable to other classifiers. Adversarial examples have also been studied in malware analysis. Unlike images, program binaries cannot be arbitrarily perturbed without rendering them non-functional. Due to the difficulty of crafting adversarial program binaries, there is no consensus on the transferability of adversarially perturbed programs to different detectors. In this work, we explore the robustness of malware detectors against adversarially perturbed malware. We investigate the transferability of adversarial attacks developed against one detector, against other machine learning-based malware detectors, and code similarity techniques, specifically, locality sensitive hashing-based detectors. Our analysis reveals that adversarial program binaries crafted for one detector are generally less effective against others. We also evaluate an ensemble of detectors and show that they can potentially mitigate the impact of adversarial program binaries. Finally, we demonstrate that substantial program changes made to evade detection may result in the transformation technique being identified, implying that the adversary must make minimal changes to the program binary.
Syntactic Complexity Identification, Measurement, and Reduction Through Controlled Syntactic Simplification
Apr 16, 2023
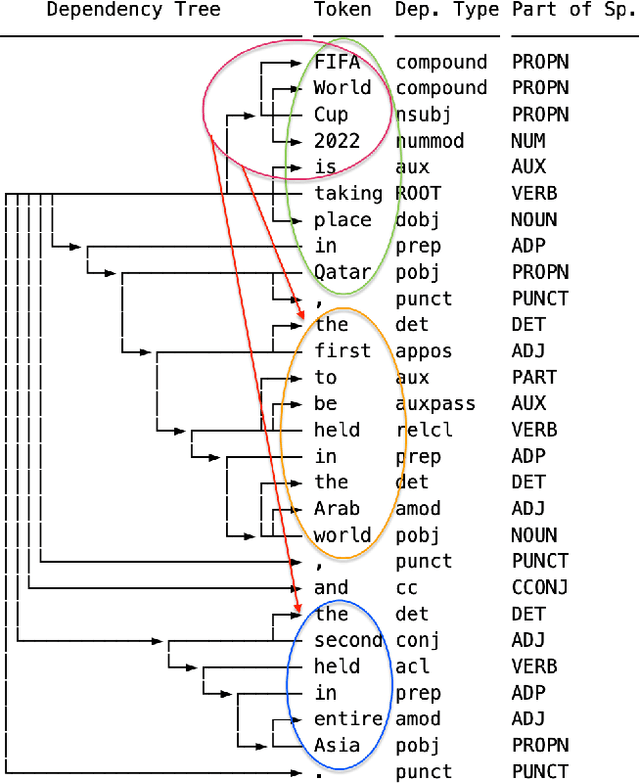

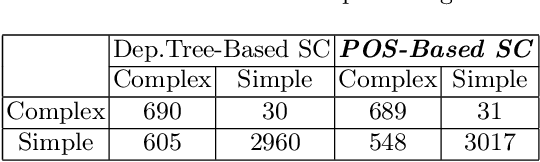
Text simplification is one of the domains in Natural Language Processing (NLP) that offers an opportunity to understand the text in a simplified manner for exploration. However, it is always hard to understand and retrieve knowledge from unstructured text, which is usually in the form of compound and complex sentences. There are state-of-the-art neural network-based methods to simplify the sentences for improved readability while replacing words with plain English substitutes and summarising the sentences and paragraphs. In the Knowledge Graph (KG) creation process from unstructured text, summarising long sentences and substituting words is undesirable since this may lead to information loss. However, KG creation from text requires the extraction of all possible facts (triples) with the same mentions as in the text. In this work, we propose a controlled simplification based on the factual information in a sentence, i.e., triple. We present a classical syntactic dependency-based approach to split and rephrase a compound and complex sentence into a set of simplified sentences. This simplification process will retain the original wording with a simple structure of possible domain facts in each sentence, i.e., triples. The paper also introduces an algorithm to identify and measure a sentence's syntactic complexity (SC), followed by reduction through a controlled syntactic simplification process. Last, an experiment for a dataset re-annotation is also conducted through GPT3; we aim to publish this refined corpus as a resource. This work is accepted and presented in International workshop on Learning with Knowledge Graphs (IWLKG) at WSDM-2023 Conference. The code and data is available at www.github.com/sallmanm/SynSim.