 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-ZD: A Transferable Graph Neural Network Approach for Proactive Zero-Day Threats Mitigation
Feb 06, 2026In today's enterprise network landscape, the combination of perimeter and distributed firewall rules governs connectivity. To address challenges arising from increased traffic and diverse network architectures, organizations employ automated tools for firewall rule and access policy generation. Yet, effectively managing risks arising from dynamically generated policies, especially concerning critical asset exposure, remains a major challenge. This challenge is amplified by evolving network structures due to trends like remote users, bring-your-own devices, and cloud integration. This paper introduces a novel graph neural network model for identifying weighted shortest paths. The model aids in detecting network misconfigurations and high-risk connectivity paths that threaten critical assets, potentially exploited in zero-day attacks -- cyber-attacks exploiting undisclosed vulnerabilities. The proposed Pro-ZD framework adopts a proactive approach, automatically fine-tuning firewall rules and access policies to address high-risk connections and prevent unauthorized access. Experimental results highlight the robustness and transferability of Pro-ZD, achieving over 95% average accuracy in detecting high-risk connections. \
A Large-Scale Empirical Analysis of Custom GPTs' Vulnerabilities in the OpenAI Ecosystem
May 13, 2025Millions of users leverage generative pretrained transformer (GPT)-based language models developed by leading model providers for a wide range of tasks. To support enhanced user interaction and customization, many platforms-such as OpenAI-now enable developers to create and publish tailored model instances, known as custom GPTs, via dedicated repositories or application stores. These custom GPTs empower users to browse and interact with specialized applications designed to meet specific needs. However, as custom GPTs see growing adoption, concerns regarding their security vulnerabilities have intensified. Existing research on these vulnerabilities remains largely theoretical, often lacking empirical, large-scale, and statistically rigorous assessments of associated risks. In this study, we analyze 14,904 custom GPTs to assess their susceptibility to seven exploitable threats, such as roleplay-based attacks, system prompt leakage, phishing content generation, and malicious code synthesis, across various categories and popularity tiers within the OpenAI marketplace. We introduce a multi-metric ranking system to examine the relationship between a custom GPT's popularity and its associated security risks. Our findings reveal that over 95% of custom GPTs lack adequate security protections. The most prevalent vulnerabilities include roleplay-based vulnerabilities (96.51%), system prompt leakage (92.20%), and phishing (91.22%). Furthermore, we demonstrate that OpenAI's foundational models exhibit inherent security weaknesses, which are often inherited or amplified in custom GPTs. These results highlight the urgent need for enhanced security measures and stricter content moderation to ensure the safe deployment of GPT-based applications.
On the Robustness of Malware Detectors to Adversarial Samples
Aug 05, 2024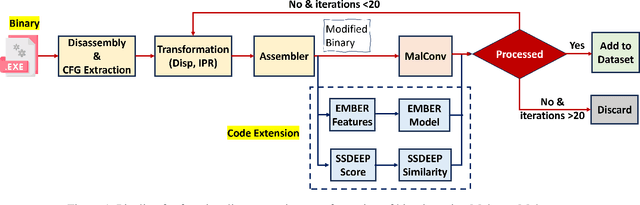
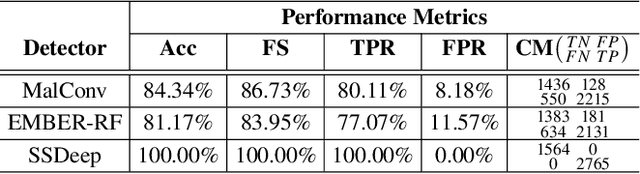
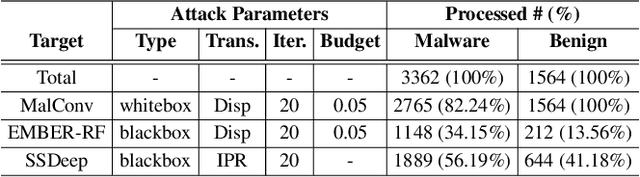
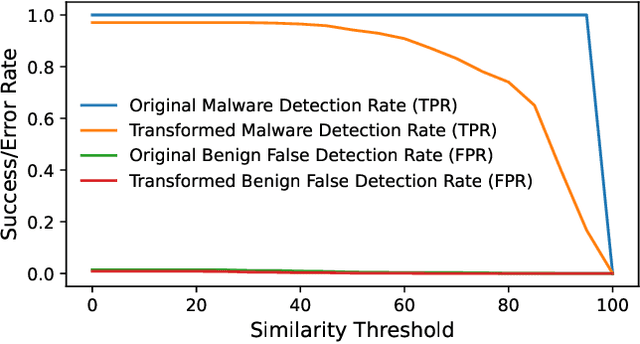
Adversarial examples add imperceptible alterations to inputs with the objective to induce misclassification in machine learning models. They have been demonstrated to pose significant challenges in domains like image classification, with results showing that an adversarially perturbed image to evade detection against one classifier is most likely transferable to other classifiers. Adversarial examples have also been studied in malware analysis. Unlike images, program binaries cannot be arbitrarily perturbed without rendering them non-functional. Due to the difficulty of crafting adversarial program binaries, there is no consensus on the transferability of adversarially perturbed programs to different detectors. In this work, we explore the robustness of malware detectors against adversarially perturbed malware. We investigate the transferability of adversarial attacks developed against one detector, against other machine learning-based malware detectors, and code similarity techniques, specifically, locality sensitive hashing-based detectors. Our analysis reveals that adversarial program binaries crafted for one detector are generally less effective against others. We also evaluate an ensemble of detectors and show that they can potentially mitigate the impact of adversarial program binaries. Finally, we demonstrate that substantial program changes made to evade detection may result in the transformation technique being identified, implying that the adversary must make minimal changes to the program binary.
BotSSCL: Social Bot Detection with Self-Supervised Contrastive Learning
Feb 06, 2024

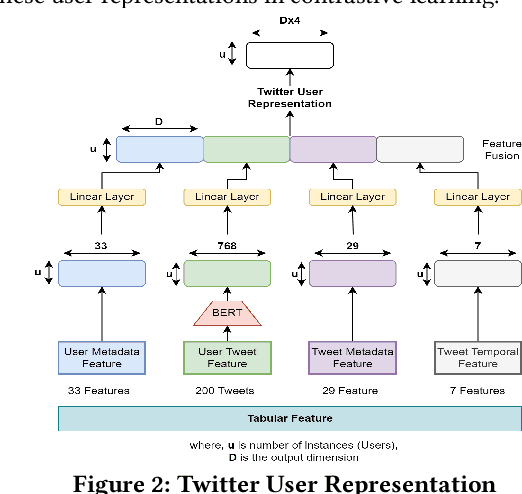

The detection of automated accounts, also known as "social bots", has been an increasingly important concern for online social networks (OSNs). While several methods have been proposed for detecting social bots, significant research gaps remain. First, current models exhibit limitations in detecting sophisticated bots that aim to mimic genuine OSN users. Second, these methods often rely on simplistic profile features, which are susceptible to manipulation. In addition to their vulnerability to adversarial manipulations, these models lack generalizability, resulting in subpar performance when trained on one dataset and tested on another. To address these challenges, we propose a novel framework for social Bot detection with Self-Supervised Contrastive Learning (BotSSCL). Our framework leverages contrastive learning to distinguish between social bots and humans in the embedding space to improve linear separability. The high-level representations derived by BotSSCL enhance its resilience to variations in data distribution and ensure generalizability. We evaluate BotSSCL's robustness against adversarial attempts to manipulate bot accounts to evade detection. Experiments on two datasets featuring sophisticated bots demonstrate that BotSSCL outperforms other supervised, unsupervised, and self-supervised baseline methods. We achieve approx. 6% and approx. 8% higher (F1) performance than SOTA on both datasets. In addition, BotSSCL also achieves 67% F1 when trained on one dataset and tested with another, demonstrating its generalizability. Lastly, BotSSCL increases adversarial complexity and only allows 4% success to the adversary in evading detection.
False Information, Bots and Malicious Campaigns: Demystifying Elements of Social Media Manipulations
Aug 24, 2023



The rapid spread of false information and persistent manipulation attacks on online social networks (OSNs), often for political, ideological, or financial gain, has affected the openness of OSNs. While researchers from various disciplines have investigated different manipulation-triggering elements of OSNs (such as understanding information diffusion on OSNs or detecting automated behavior of accounts), these works have not been consolidated to present a comprehensive overview of the interconnections among these elements. Notably, user psychology, the prevalence of bots, and their tactics in relation to false information detection have been overlooked in previous research. To address this research gap, this paper synthesizes insights from various disciplines to provide a comprehensive analysis of the manipulation landscape. By integrating the primary elements of social media manipulation (SMM), including false information, bots, and malicious campaigns, we extensively examine each SMM element. Through a systematic investigation of prior research, we identify commonalities, highlight existing gaps, and extract valuable insights in the field. Our findings underscore the urgent need for interdisciplinary research to effectively combat social media manipulations, and our systematization can guide future research efforts and assist OSN providers in ensuring the safety and integrity of their platforms.
SPGNN-API: A Transferable Graph Neural Network for Attack Paths Identification and Autonomous Mitigation
May 31, 2023Attack paths are the potential chain of malicious activities an attacker performs to compromise network assets and acquire privileges through exploiting network vulnerabilities. Attack path analysis helps organizations to identify new/unknown chains of attack vectors that reach critical assets within the network, as opposed to individual attack vectors in signature-based attack analysis. Timely identification of attack paths enables proactive mitigation of threats. Nevertheless, manual analysis of complex network configurations, vulnerabilities, and security events to identify attack paths is rarely feasible. This work proposes a novel transferable graph neural network-based model for shortest path identification. The proposed shortest path detection approach, integrated with a novel holistic and comprehensive model for identifying potential network vulnerabilities interactions, is then utilized to detect network attack paths. Our framework automates the risk assessment of attack paths indicating the propensity of the paths to enable the compromise of highly-critical assets (e.g., databases) given the network configuration, assets' criticality, and the severity of the vulnerabilities in-path to the asset. The proposed framework, named SPGNN-API, incorporates automated threat mitigation through a proactive timely tuning of the network firewall rules and zero-trust policies to break critical attack paths and bolster cyber defenses. Our evaluation process is twofold; evaluating the performance of the shortest path identification and assessing the attack path detection accuracy. Our results show that SPGNN-API largely outperforms the baseline model for shortest path identification with an average accuracy >= 95% and successfully detects 100% of the potentially compromised assets, outperforming the attack graph baseline by 47%.
Machine Learning-based Automatic Annotation and Detection of COVID-19 Fake News
Sep 07, 2022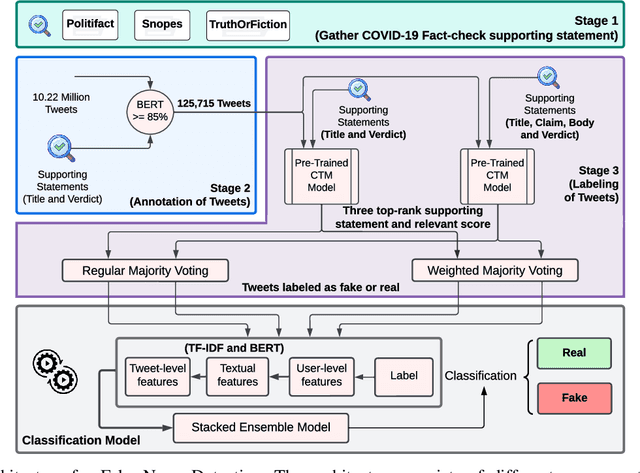
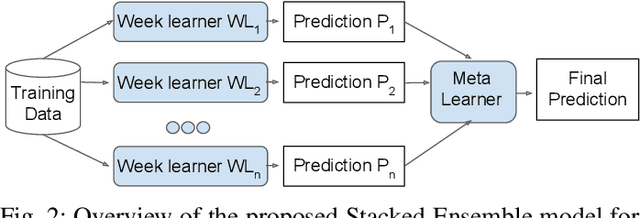
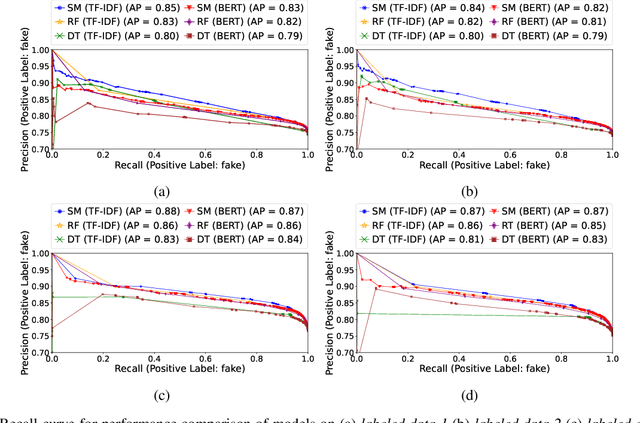
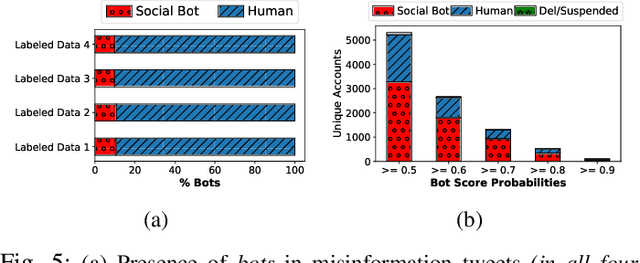
COVID-19 impacted every part of the world, although the misinformation about the outbreak traveled faster than the virus. Misinformation spread through online social networks (OSN) often misled people from following correct medical practices. In particular, OSN bots have been a primary source of disseminating false information and initiating cyber propaganda. Existing work neglects the presence of bots that act as a catalyst in the spread and focuses on fake news detection in 'articles shared in posts' rather than the post (textual) content. Most work on misinformation detection uses manually labeled datasets that are hard to scale for building their predictive models. In this research, we overcome this challenge of data scarcity by proposing an automated approach for labeling data using verified fact-checked statements on a Twitter dataset. In addition, we combine textual features with user-level features (such as followers count and friends count) and tweet-level features (such as number of mentions, hashtags and urls in a tweet) to act as additional indicators to detect misinformation. Moreover, we analyzed the presence of bots in tweets and show that bots change their behavior over time and are most active during the misinformation campaign. We collected 10.22 Million COVID-19 related tweets and used our annotation model to build an extensive and original ground truth dataset for classification purposes. We utilize various machine learning models to accurately detect misinformation and our best classification model achieves precision (82%), recall (96%), and false positive rate (3.58%). Also, our bot analysis indicates that bots generated approximately 10% of misinformation tweets. Our methodology results in substantial exposure of false information, thus improving the trustworthiness of information disseminated through social media platforms.