 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Rat in the Tunnel: Interpretable Multi-Label Classification of Tor-based Malware
Sep 25, 2024
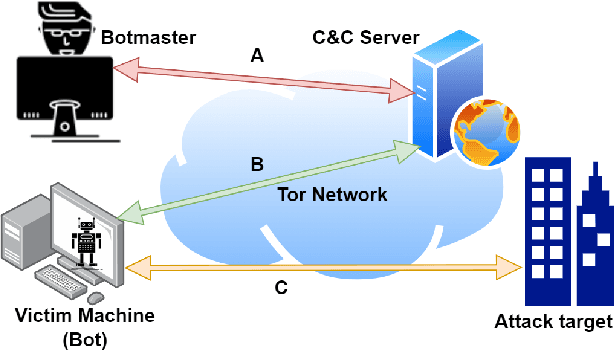
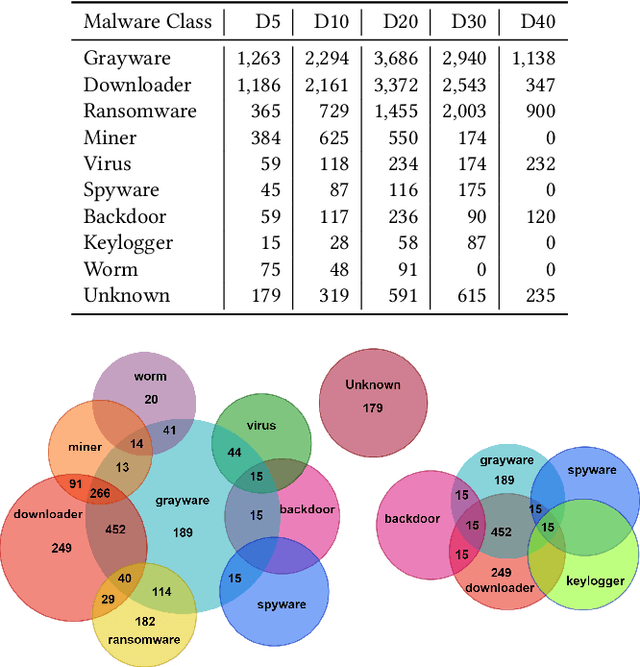

Despite being the most popular privacy-enhancing network, Tor is increasingly adopted by cybercriminals to obfuscate malicious traffic, hindering the identification of malware-related communications between compromised devices and Command and Control (C&C) servers. This malicious traffic can induce congestion and reduce Tor's performance, while encouraging network administrators to block Tor traffic. Recent research, however, demonstrates the potential for accurately classifying captured Tor traffic as malicious or benign. While existing efforts have addressed malware class identification, their performance remains limited, with micro-average precision and recall values around 70%. Accurately classifying specific malware classes is crucial for effective attack prevention and mitigation. Furthermore, understanding the unique patterns and attack vectors employed by different malware classes helps the development of robust and adaptable defence mechanisms. We utilise a multi-label classification technique based on Message-Passing Neural Networks, demonstrating its superiority over previous approaches such as Binary Relevance, Classifier Chains, and Label Powerset, by achieving micro-average precision (MAP) and recall (MAR) exceeding 90%. Compared to previous work, we significantly improve performance by 19.98%, 10.15%, and 59.21% in MAP, MAR, and Hamming Loss, respectively. Next, we employ Explainable Artificial Intelligence (XAI) techniques to interpret the decision-making process within these models. Finally, we assess the robustness of all techniques by crafting adversarial perturbations capable of manipulating classifier predictions and generating false positives and negatives.
Machine Learning-based Automatic Annotation and Detection of COVID-19 Fake News
Sep 07, 2022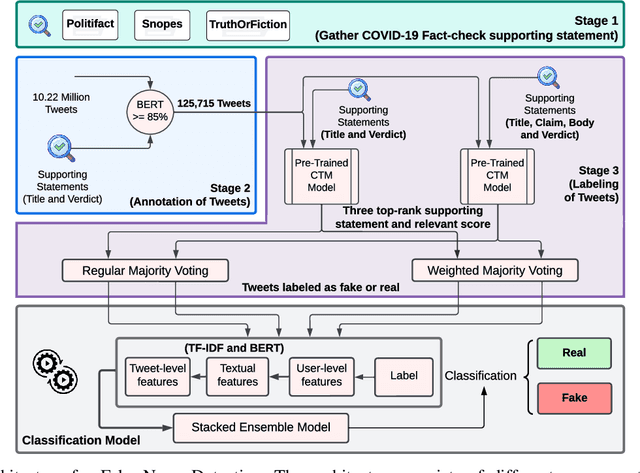
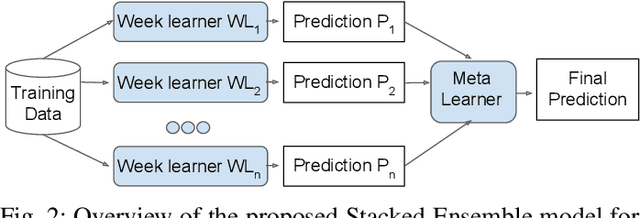
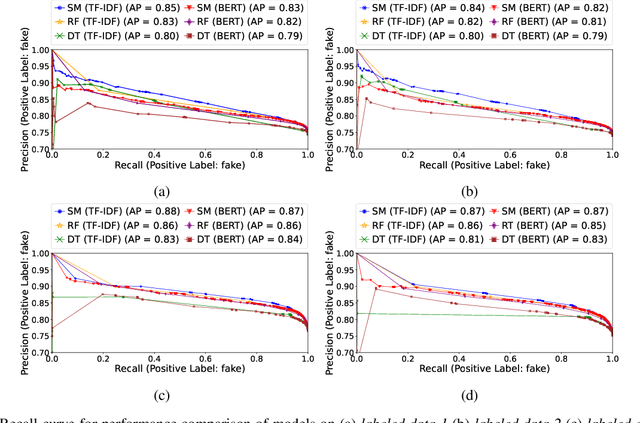
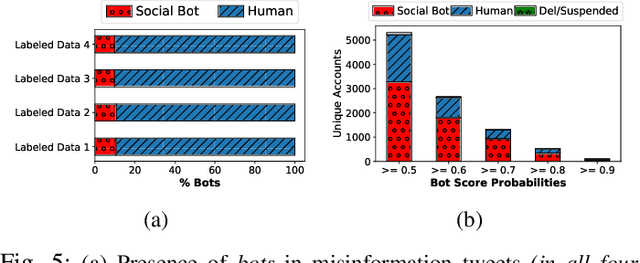
COVID-19 impacted every part of the world, although the misinformation about the outbreak traveled faster than the virus. Misinformation spread through online social networks (OSN) often misled people from following correct medical practices. In particular, OSN bots have been a primary source of disseminating false information and initiating cyber propaganda. Existing work neglects the presence of bots that act as a catalyst in the spread and focuses on fake news detection in 'articles shared in posts' rather than the post (textual) content. Most work on misinformation detection uses manually labeled datasets that are hard to scale for building their predictive models. In this research, we overcome this challenge of data scarcity by proposing an automated approach for labeling data using verified fact-checked statements on a Twitter dataset. In addition, we combine textual features with user-level features (such as followers count and friends count) and tweet-level features (such as number of mentions, hashtags and urls in a tweet) to act as additional indicators to detect misinformation. Moreover, we analyzed the presence of bots in tweets and show that bots change their behavior over time and are most active during the misinformation campaign. We collected 10.22 Million COVID-19 related tweets and used our annotation model to build an extensive and original ground truth dataset for classification purposes. We utilize various machine learning models to accurately detect misinformation and our best classification model achieves precision (82%), recall (96%), and false positive rate (3.58%). Also, our bot analysis indicates that bots generated approximately 10% of misinformation tweets. Our methodology results in substantial exposure of false information, thus improving the trustworthiness of information disseminated through social media platforms.
Intelligence at the Extreme Edge: A Survey on Reformable TinyML
Apr 02, 2022


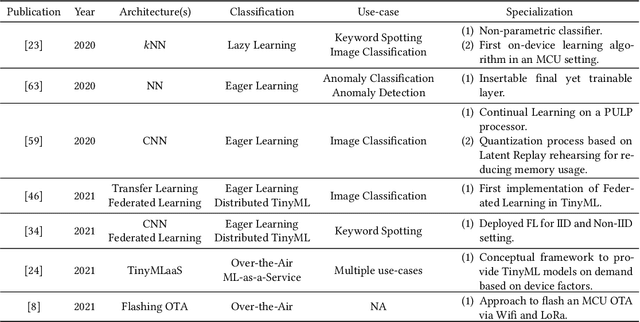
The rapid miniaturization of Machine Learning (ML) for low powered processing has opened gateways to provide cognition at the extreme edge (E.g., sensors and actuators). Dubbed Tiny Machine Learning (TinyML), this upsurging research field proposes to democratize the use of Machine Learning (ML) and Deep Learning (DL) on frugal Microcontroller Units (MCUs). MCUs are highly energy-efficient pervasive devices capable of operating with less than a few Milliwatts of power. Nevertheless, many solutions assume that TinyML can only run inference. Despite this, growing interest in TinyML has led to work that makes them reformable, i.e., work that permits TinyML to improve once deployed. In line with this, roadblocks in MCU based solutions in general, such as reduced physical access and long deployment periods of MCUs, deem reformable TinyML to play a significant part in more effective solutions. In this work, we present a survey on reformable TinyML solutions with the proposal of a novel taxonomy for ease of separation. Here, we also discuss the suitability of each hierarchical layer in the taxonomy for allowing reformability. In addition to these, we explore the workflow of TinyML and analyze the identified deployment schemes and the scarcely available benchmarking tools. Furthermore, we discuss how reformable TinyML can impact a few selected industrial areas and discuss the challenges and future directions.