 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructTransform: A Scalable Attack Surface for Safety-Aligned Large Language Models
Feb 17, 2025



In this work, we present a series of structure transformation attacks on LLM alignment, where we encode natural language intent using diverse syntax spaces, ranging from simple structure formats and basic query languages (e.g. SQL) to new novel spaces and syntaxes created entirely by LLMs. Our extensive evaluation shows that our simplest attacks can achieve close to 90% success rate, even on strict LLMs (such as Claude 3.5 Sonnet) using SOTA alignment mechanisms. We improve the attack performance further by using an adaptive scheme that combines structure transformations along with existing \textit{content transformations}, resulting in over 96% ASR with 0% refusals. To generalize our attacks, we explore numerous structure formats, including syntaxes purely generated by LLMs. Our results indicate that such novel syntaxes are easy to generate and result in a high ASR, suggesting that defending against our attacks is not a straightforward process. Finally, we develop a benchmark and evaluate existing safety-alignment defenses against it, showing that most of them fail with 100% ASR. Our results show that existing safety alignment mostly relies on token-level patterns without recognizing harmful concepts, highlighting and motivating the need for serious research efforts in this direction. As a case study, we demonstrate how attackers can use our attack to easily generate a sample malware, and a corpus of fraudulent SMS messages, which perform well in bypassing detection.
Examining the Rat in the Tunnel: Interpretable Multi-Label Classification of Tor-based Malware
Sep 25, 2024
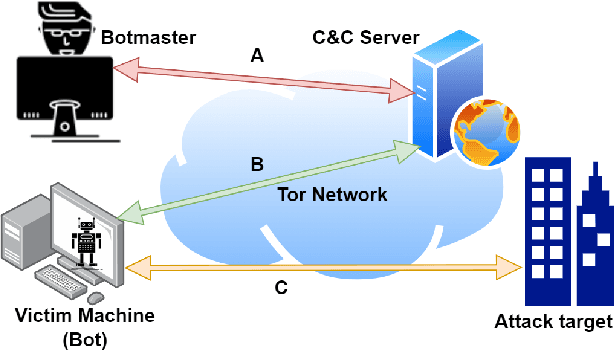
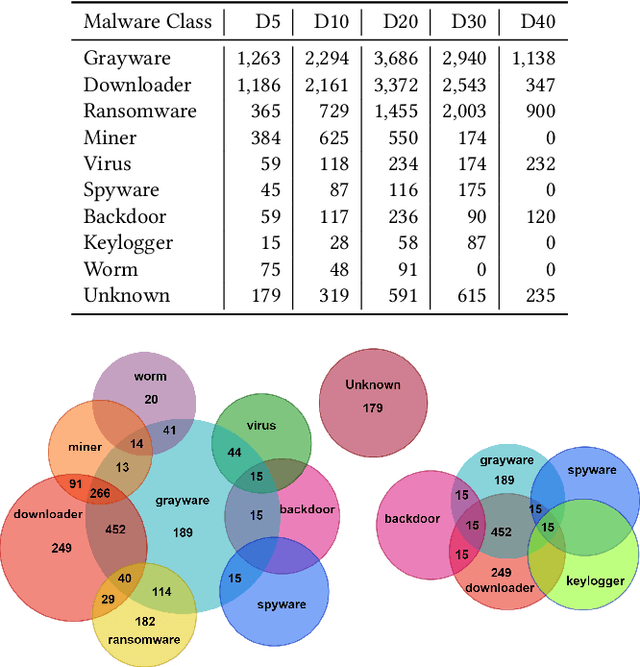

Despite being the most popular privacy-enhancing network, Tor is increasingly adopted by cybercriminals to obfuscate malicious traffic, hindering the identification of malware-related communications between compromised devices and Command and Control (C&C) servers. This malicious traffic can induce congestion and reduce Tor's performance, while encouraging network administrators to block Tor traffic. Recent research, however, demonstrates the potential for accurately classifying captured Tor traffic as malicious or benign. While existing efforts have addressed malware class identification, their performance remains limited, with micro-average precision and recall values around 70%. Accurately classifying specific malware classes is crucial for effective attack prevention and mitigation. Furthermore, understanding the unique patterns and attack vectors employed by different malware classes helps the development of robust and adaptable defence mechanisms. We utilise a multi-label classification technique based on Message-Passing Neural Networks, demonstrating its superiority over previous approaches such as Binary Relevance, Classifier Chains, and Label Powerset, by achieving micro-average precision (MAP) and recall (MAR) exceeding 90%. Compared to previous work, we significantly improve performance by 19.98%, 10.15%, and 59.21% in MAP, MAR, and Hamming Loss, respectively. Next, we employ Explainable Artificial Intelligence (XAI) techniques to interpret the decision-making process within these models. Finally, we assess the robustness of all techniques by crafting adversarial perturbations capable of manipulating classifier predictions and generating false positives and negatives.