 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Multilingual and Bilingual Models for Satirical News Detection of Arabic and English
Nov 16, 2024


Satirical news is real news combined with a humorous comment or exaggerated content, and it often mimics the format and style of real news. However, satirical news is often misunderstood as misinformation, especially by individuals from different cultural and social backgrounds. This research addresses the challenge of distinguishing satire from truthful news by leveraging multilingual satire detection methods in English and Arabic. We explore both zero-shot and chain-of-thought (CoT) prompting using two language models, Jais-chat(13B) and LLaMA-2-chat(7B). Our results show that CoT prompting offers a significant advantage for the Jais-chat model over the LLaMA-2-chat model. Specifically, Jais-chat achieved the best performance, with an F1-score of 80\% in English when using CoT prompting. These results highlight the importance of structured reasoning in CoT, which enhances contextual understanding and is vital for complex tasks like satire detection.
BotSSCL: Social Bot Detection with Self-Supervised Contrastive Learning
Feb 06, 2024

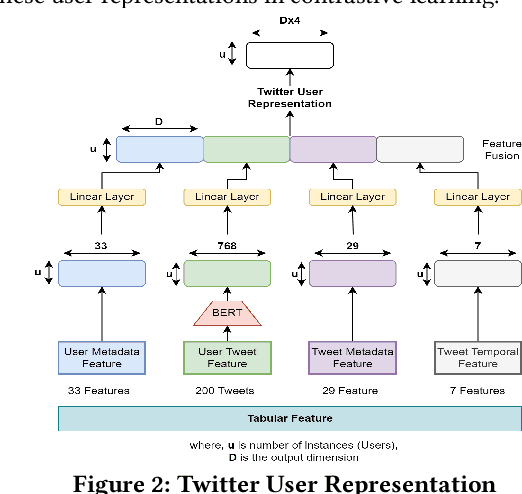

The detection of automated accounts, also known as "social bots", has been an increasingly important concern for online social networks (OSNs). While several methods have been proposed for detecting social bots, significant research gaps remain. First, current models exhibit limitations in detecting sophisticated bots that aim to mimic genuine OSN users. Second, these methods often rely on simplistic profile features, which are susceptible to manipulation. In addition to their vulnerability to adversarial manipulations, these models lack generalizability, resulting in subpar performance when trained on one dataset and tested on another. To address these challenges, we propose a novel framework for social Bot detection with Self-Supervised Contrastive Learning (BotSSCL). Our framework leverages contrastive learning to distinguish between social bots and humans in the embedding space to improve linear separability. The high-level representations derived by BotSSCL enhance its resilience to variations in data distribution and ensure generalizability. We evaluate BotSSCL's robustness against adversarial attempts to manipulate bot accounts to evade detection. Experiments on two datasets featuring sophisticated bots demonstrate that BotSSCL outperforms other supervised, unsupervised, and self-supervised baseline methods. We achieve approx. 6% and approx. 8% higher (F1) performance than SOTA on both datasets. In addition, BotSSCL also achieves 67% F1 when trained on one dataset and tested with another, demonstrating its generalizability. Lastly, BotSSCL increases adversarial complexity and only allows 4% success to the adversary in evading detection.
False Information, Bots and Malicious Campaigns: Demystifying Elements of Social Media Manipulations
Aug 24, 2023The rapid spread of false information and persistent manipulation attacks on online social networks (OSNs), often for political, ideological, or financial gain, has affected the openness of OSNs. While researchers from various disciplines have investigated different manipulation-triggering elements of OSNs (such as understanding information diffusion on OSNs or detecting automated behavior of accounts), these works have not been consolidated to present a comprehensive overview of the interconnections among these elements. Notably, user psychology, the prevalence of bots, and their tactics in relation to false information detection have been overlooked in previous research. To address this research gap, this paper synthesizes insights from various disciplines to provide a comprehensive analysis of the manipulation landscape. By integrating the primary elements of social media manipulation (SMM), including false information, bots, and malicious campaigns, we extensively examine each SMM element. Through a systematic investigation of prior research, we identify commonalities, highlight existing gaps, and extract valuable insights in the field. Our findings underscore the urgent need for interdisciplinary research to effectively combat social media manipulations, and our systematization can guide future research efforts and assist OSN providers in ensuring the safety and integrity of their platforms.
Machine Learning-based Automatic Annotation and Detection of COVID-19 Fake News
Sep 07, 2022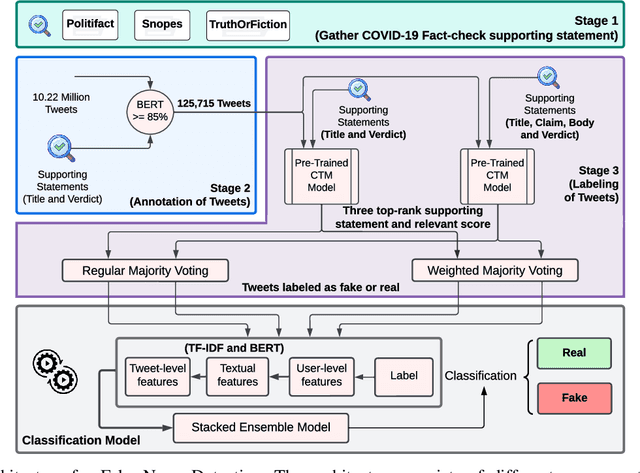
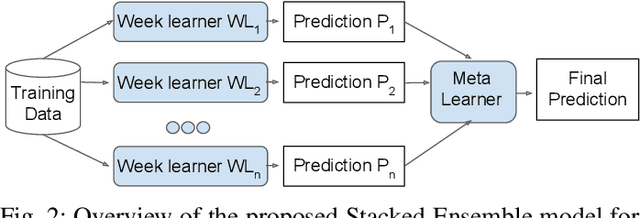
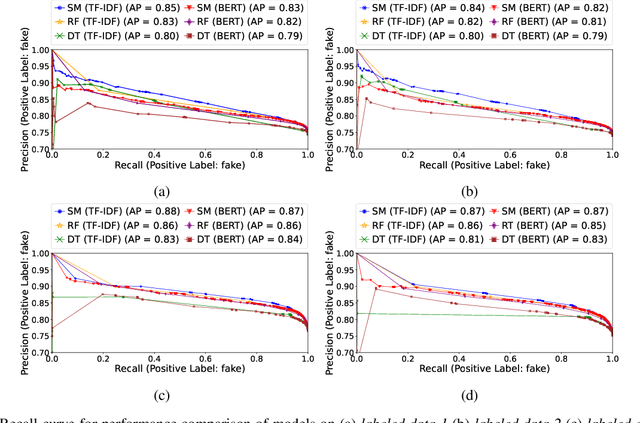
COVID-19 impacted every part of the world, although the misinformation about the outbreak traveled faster than the virus. Misinformation spread through online social networks (OSN) often misled people from following correct medical practices. In particular, OSN bots have been a primary source of disseminating false information and initiating cyber propaganda. Existing work neglects the presence of bots that act as a catalyst in the spread and focuses on fake news detection in 'articles shared in posts' rather than the post (textual) content. Most work on misinformation detection uses manually labeled datasets that are hard to scale for building their predictive models. In this research, we overcome this challenge of data scarcity by proposing an automated approach for labeling data using verified fact-checked statements on a Twitter dataset. In addition, we combine textual features with user-level features (such as followers count and friends count) and tweet-level features (such as number of mentions, hashtags and urls in a tweet) to act as additional indicators to detect misinformation. Moreover, we analyzed the presence of bots in tweets and show that bots change their behavior over time and are most active during the misinformation campaign. We collected 10.22 Million COVID-19 related tweets and used our annotation model to build an extensive and original ground truth dataset for classification purposes. We utilize various machine learning models to accurately detect misinformation and our best classification model achieves precision (82%), recall (96%), and false positive rate (3.58%). Also, our bot analysis indicates that bots generated approximately 10% of misinformation tweets. Our methodology results in substantial exposure of false information, thus improving the trustworthiness of information disseminated through social media platforms.
A Review of Computer Vision Methods in Network Security
May 07, 2020



Network security has become an area of significant importance more than ever as highlighted by the eye-opening numbers of data breaches, attacks on critical infrastructure, and malware/ransomware/cryptojacker attacks that are reported almost every day. Increasingly, we are relying on networked infrastructure and with the advent of IoT, billions of devices will be connected to the internet, providing attackers with more opportunities to exploit. Traditional machine learning methods have been frequently used in the context of network security. However, such methods are more based on statistical features extracted from sources such as binaries, emails, and packet flows. On the other hand, recent years witnessed a phenomenal growth in computer vision mainly driven by the advances in the area of convolutional neural networks. At a glance, it is not trivial to see how computer vision methods are related to network security. Nonetheless, there is a significant amount of work that highlighted how methods from computer vision can be applied in network security for detecting attacks or building security solutions. In this paper, we provide a comprehensive survey of such work under three topics; i) phishing attempt detection, ii) malware detection, and iii) traffic anomaly detection. Next, we review a set of such commercial products for which public information is available and explore how computer vision methods are effectively used in those products. Finally, we discuss existing research gaps and future research directions, especially focusing on how network security research community and the industry can leverage the exponential growth of computer vision methods to build much secure networked systems.