 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Comparison and Evaluation of Building Ontologies for Deploying Data-Driven Analytics in Smart Buildings
Mar 15, 2026Ontologies play a critical role in data exchange, information integration, and knowledge sharing across diverse smart building applications. Yet, semantic differences between the prevailing building ontologies hamper their purpose of bringing data interoperability and restrict the ability to reuse building ontologies in real-world applications. In this paper, we propose and adopt a framework to conduct a systematic comparison and evaluation of four popular building ontologies (Brick Schema, RealEstateCore, Project Haystack and Google's Digital Buildings) from both axiomatic design and assertions in a use case, namely the Terminological Box (TBox) evaluation and the Assertion Box (ABox) evaluation. In the TBox evaluation, we use the SQuaRE-based Ontology Quality Evaluation (OQuaRE) Framework and concede that Project Haystack and Brick Schema are more compact with respect to the ontology axiomatic design. In the ABox evaluation, we apply an empirical study with sample building data that suggests that Brick Schema and RealEstateCore have greater completeness and expressiveness in capturing the main concepts and relations within the building domain. The results implicitly indicate that there is no universal building ontology for integrating Linked Building Data (LBD). We also discuss ontology compatibility and investigate building ontology design patterns (ODPs) to support ontology matching, alignment, and harmonisation.
"Forgetting" in Machine Learning and Beyond: A Survey
May 31, 2024



This survey investigates the multifaceted nature of forgetting in machine learning, drawing insights from neuroscientific research that posits forgetting as an adaptive function rather than a defect, enhancing the learning process and preventing overfitting. This survey focuses on the benefits of forgetting and its applications across various machine learning sub-fields that can help improve model performance and enhance data privacy. Moreover, the paper discusses current challenges, future directions, and ethical considerations regarding the integration of forgetting mechanisms into machine learning models.
Syntactic Complexity Identification, Measurement, and Reduction Through Controlled Syntactic Simplification
Apr 16, 2023
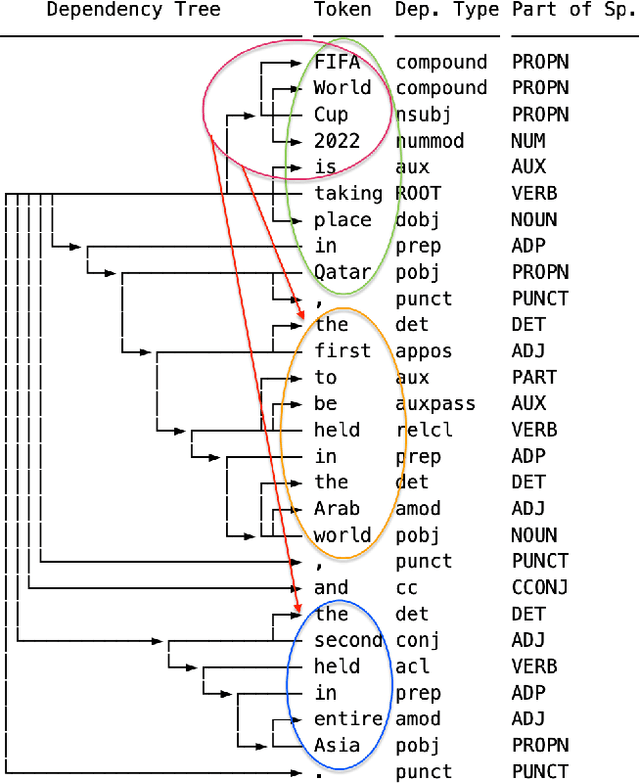

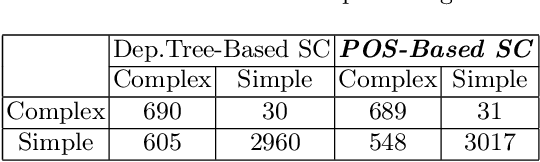
Text simplification is one of the domains in Natural Language Processing (NLP) that offers an opportunity to understand the text in a simplified manner for exploration. However, it is always hard to understand and retrieve knowledge from unstructured text, which is usually in the form of compound and complex sentences. There are state-of-the-art neural network-based methods to simplify the sentences for improved readability while replacing words with plain English substitutes and summarising the sentences and paragraphs. In the Knowledge Graph (KG) creation process from unstructured text, summarising long sentences and substituting words is undesirable since this may lead to information loss. However, KG creation from text requires the extraction of all possible facts (triples) with the same mentions as in the text. In this work, we propose a controlled simplification based on the factual information in a sentence, i.e., triple. We present a classical syntactic dependency-based approach to split and rephrase a compound and complex sentence into a set of simplified sentences. This simplification process will retain the original wording with a simple structure of possible domain facts in each sentence, i.e., triples. The paper also introduces an algorithm to identify and measure a sentence's syntactic complexity (SC), followed by reduction through a controlled syntactic simplification process. Last, an experiment for a dataset re-annotation is also conducted through GPT3; we aim to publish this refined corpus as a resource. This work is accepted and presented in International workshop on Learning with Knowledge Graphs (IWLKG) at WSDM-2023 Conference. The code and data is available at www.github.com/sallmanm/SynSim.
A System's Approach Taxonomy for User-Centred XAI: A Survey
Mar 06, 2023Recent advancements in AI have coincided with ever-increasing efforts in the research community to investigate, classify and evaluate various methods aimed at making AI models explainable. However, most of existing attempts present a method-centric view of eXplainable AI (XAI) which is typically meaningful only for domain experts. There is an apparent lack of a robust qualitative and quantitative performance framework that evaluates the suitability of explanations for different types of users. We survey relevant efforts, and then, propose a unified, inclusive and user-centred taxonomy for XAI based on the principles of General System's Theory, which serves us as a basis for evaluating the appropriateness of XAI approaches for all user types, including both developers and end users.
TNNT: The Named Entity Recognition Toolkit
Aug 31, 2021
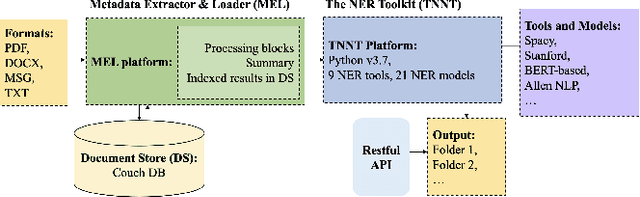
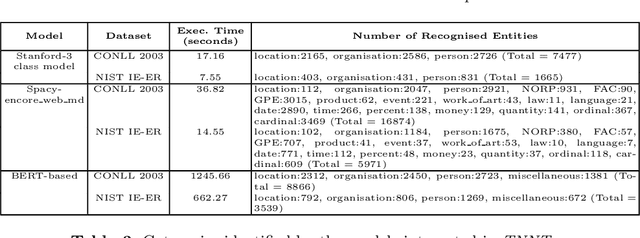
Extraction of categorised named entities from text is a complex task given the availability of a variety of Named Entity Recognition (NER) models and the unstructured information encoded in different source document formats. Processing the documents to extract text, identifying suitable NER models for a task, and obtaining statistical information is important in data analysis to make informed decisions. This paper presents TNNT, a toolkit that automates the extraction of categorised named entities from unstructured information encoded in source documents, using diverse state-of-the-art Natural Language Processing (NLP) tools and NER models. TNNT integrates 21 different NER models as part of a Knowledge Graph Construction Pipeline (KGCP) that takes a document set as input and processes it based on the defined settings, applying the selected blocks of NER models to output the results. The toolkit generates all results with an integrated summary of the extracted entities, enabling enhanced data analysis to support the KGCP, and also, to aid further NLP tasks.
SOSA: A Lightweight Ontology for Sensors, Observations, Samples, and Actuators
May 25, 2018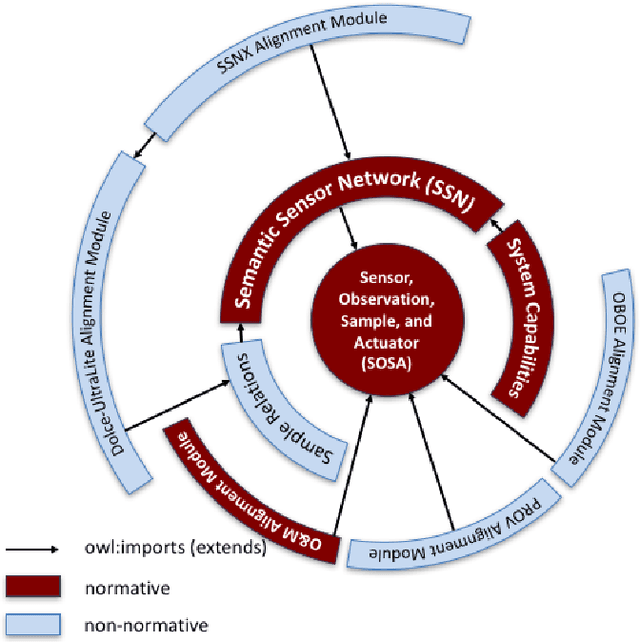
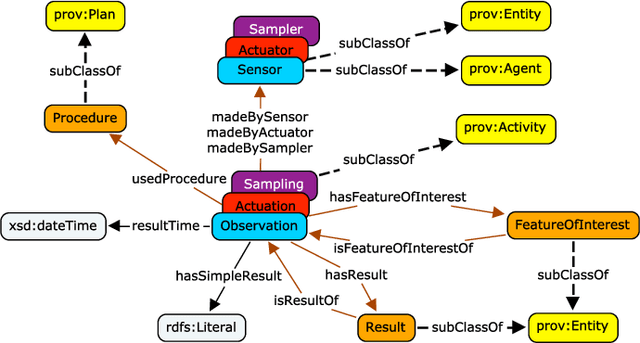
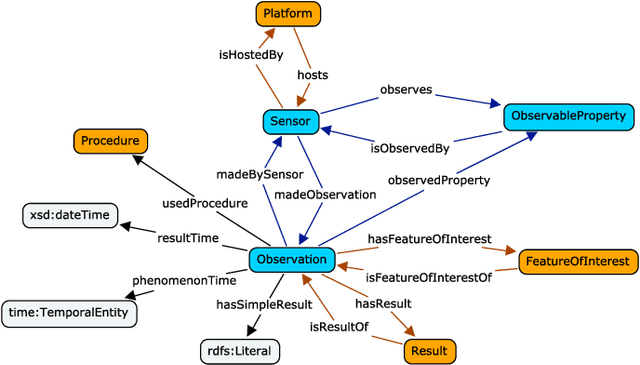
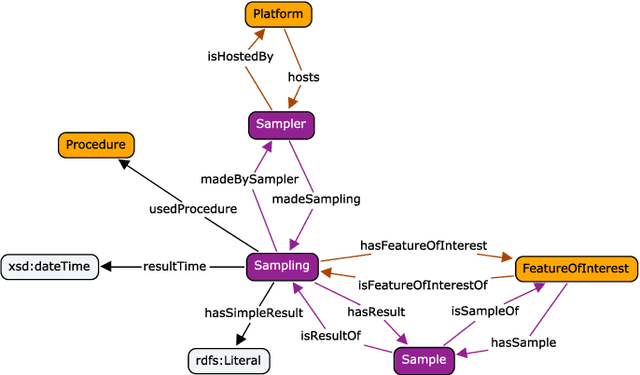
The Sensor, Observation, Sample, and Actuator (SOSA) ontology provides a formal but lightweight general-purpose specification for modeling the interaction between the entities involved in the acts of observation, actuation, and sampling. SOSA is the result of rethinking the W3C-XG Semantic Sensor Network (SSN) ontology based on changes in scope and target audience, technical developments, and lessons learned over the past years. SOSA also acts as a replacement of SSN's Stimulus Sensor Observation (SSO) core. It has been developed by the first joint working group of the Open Geospatial Consortium (OGC) and the World Wide Web Consortium (W3C) on \emph{Spatial Data on the Web}. In this work, we motivate the need for SOSA, provide an overview of the main classes and properties, and briefly discuss its integration with the new release of the SSN ontology as well as various other alignments to specifications such as OGC's Observations and Measurements (O\&M), Dolce-Ultralite (DUL), and other prominent ontologies. We will also touch upon common modeling problems and application areas related to publishing and searching observation, sampling, and actuation data on the Web. The SOSA ontology and standard can be accessed at \url{https://www.w3.org/TR/vocab-ssn/}.