 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTLayout: Fusion of Visual and Text Features for Document Layout Analysis
Aug 12, 2021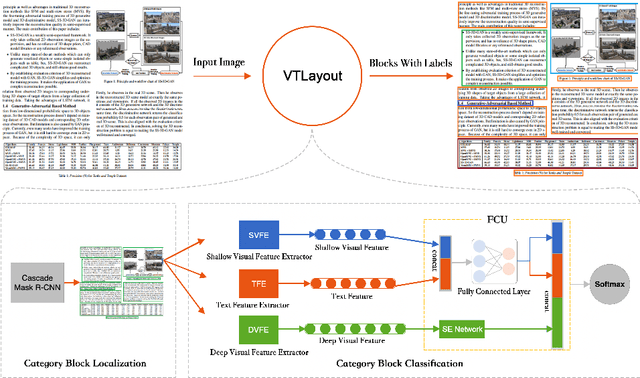
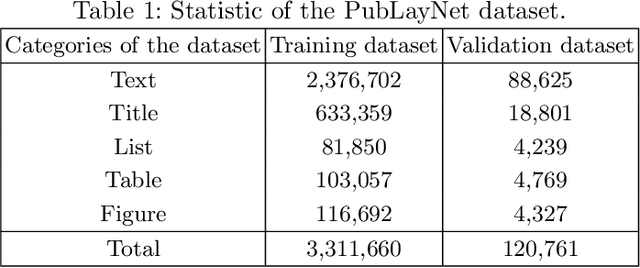
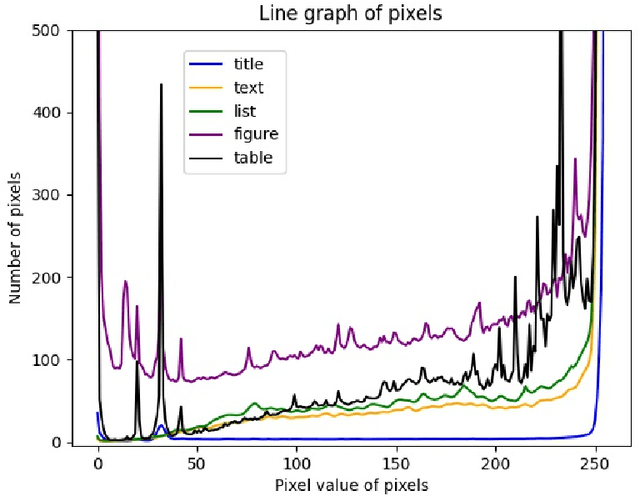
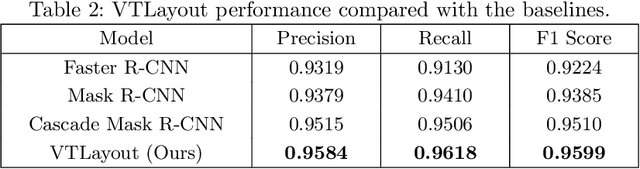
Documents often contain complex physical structures, which make the Document Layout Analysis (DLA) task challenging. As a pre-processing step for content extraction, DLA has the potential to capture rich information in historical or scientific documents on a large scale. Although many deep-learning-based methods from computer vision have already achieved excellent performance in detecting \emph{Figure} from documents, they are still unsatisfactory in recognizing the \emph{List}, \emph{Table}, \emph{Text} and \emph{Title} category blocks in DLA. This paper proposes a VTLayout model fusing the documents' deep visual, shallow visual, and text features to localize and identify different category blocks. The model mainly includes two stages, and the three feature extractors are built in the second stage. In the first stage, the Cascade Mask R-CNN model is applied directly to localize all category blocks of the documents. In the second stage, the deep visual, shallow visual, and text features are extracted for fusion to identify the category blocks of documents. As a result, we strengthen the classification power of different category blocks based on the existing localization technique. The experimental results show that the identification capability of the VTLayout is superior to the most advanced method of DLA based on the PubLayNet dataset, and the F1 score is as high as 0.9599.