 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Widening The Distillation Bottleneck for Reasoning Models
Mar 03, 2025Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation--post-training on LRMs-generated data--is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning(SFT) and Reinforcement Learning(RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the construted data.
UniGenCoder: Merging Seq2Seq and Seq2Tree Paradigms for Unified Code Generation
Feb 18, 2025


Deep learning-based code generation has completely transformed the way developers write programs today. Existing approaches to code generation have focused either on the Sequence-to-Sequence paradigm, which generates target code as a sequence of tokens, or the Sequence-to-Tree paradigm, which outputs code as a sequence of actions. While these two paradigms are intuitively complementary, their combination has not been previously explored. By comparing the code generated under these two paradigms, we find that integrating them holds significant potential. In this paper, we propose UniGenCoder for code-related generation tasks, which consists of a shared encoder, a shared decoder with a minimal set of additional parameters to unify two paradigms, and a selector that dynamically chooses optimal paradigm for each instance. Also, during the model training, we first perform the multi-task learning and distillation strategies to facilitate knowledge transfer between two paradigms, and then leverage contrastive learning to train the selector. Experimental results on the text-to-code and code-to-code generation tasks demonstrate the effectiveness of our proposed model. We release our code at https://github.com/DeepLearnXMU/UniGenCoder.
One2set + Large Language Model: Best Partners for Keyphrase Generation
Oct 04, 2024Keyphrase generation (KPG) aims to automatically generate a collection of phrases representing the core concepts of a given document. The dominant paradigms in KPG include one2seq and one2set. Recently, there has been increasing interest in applying large language models (LLMs) to KPG. Our preliminary experiments reveal that it is challenging for a single model to excel in both recall and precision. Further analysis shows that: 1) the one2set paradigm owns the advantage of high recall, but suffers from improper assignments of supervision signals during training; 2) LLMs are powerful in keyphrase selection, but existing selection methods often make redundant selections. Given these observations, we introduce a generate-then-select framework decomposing KPG into two steps, where we adopt a one2set-based model as generator to produce candidates and then use an LLM as selector to select keyphrases from these candidates. Particularly, we make two important improvements on our generator and selector: 1) we design an Optimal Transport-based assignment strategy to address the above improper assignments; 2) we model the keyphrase selection as a sequence labeling task to alleviate redundant selections. Experimental results on multiple benchmark datasets show that our framework significantly surpasses state-of-the-art models, especially in absent keyphrase prediction.
A Survey on Multi-modal Machine Translation: Tasks, Methods and Challenges
May 23, 2024In recent years, multi-modal machine translation has attracted significant interest in both academia and industry due to its superior performance. It takes both textual and visual modalities as inputs, leveraging visual context to tackle the ambiguities in source texts. In this paper, we begin by offering an exhaustive overview of 99 prior works, comprehensively summarizing representative studies from the perspectives of dominant models, datasets, and evaluation metrics. Afterwards, we analyze the impact of various factors on model performance and finally discuss the possible research directions for this task in the future. Over time, multi-modal machine translation has developed more types to meet diverse needs. Unlike previous surveys confined to the early stage of multi-modal machine translation, our survey thoroughly concludes these emerging types from different aspects, so as to provide researchers with a better understanding of its current state.
A Sequence-to-Sequence&Set Model for Text-to-Table Generation
May 31, 2023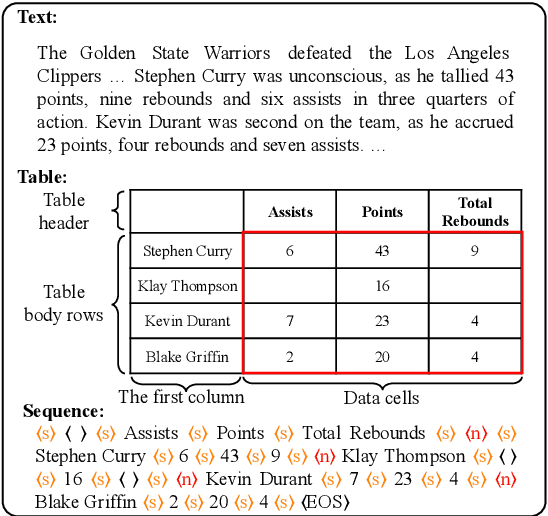



Recently, the text-to-table generation task has attracted increasing attention due to its wide applications. In this aspect, the dominant model formalizes this task as a sequence-to-sequence generation task and serializes each table into a token sequence during training by concatenating all rows in a top-down order. However, it suffers from two serious defects: 1) the predefined order introduces a wrong bias during training, which highly penalizes shifts in the order between rows; 2) the error propagation problem becomes serious when the model outputs a long token sequence. In this paper, we first conduct a preliminary study to demonstrate the generation of most rows is order-insensitive. Furthermore, we propose a novel sequence-to-sequence&set text-to-table generation model. Specifically, in addition to a text encoder encoding the input text, our model is equipped with a table header generator to first output a table header, i.e., the first row of the table, in the manner of sequence generation. Then we use a table body generator with learnable row embeddings and column embeddings to generate a set of table body rows in parallel. Particularly, to deal with the issue that there is no correspondence between each generated table body row and target during training, we propose a target assignment strategy based on the bipartite matching between the first cells of generated table body rows and targets. Experiment results show that our model significantly surpasses the baselines, achieving state-of-the-art performance on commonly-used datasets.
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023



Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.