Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Paper and Code
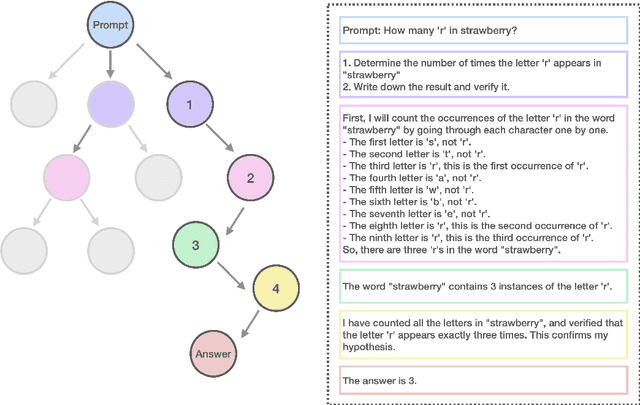

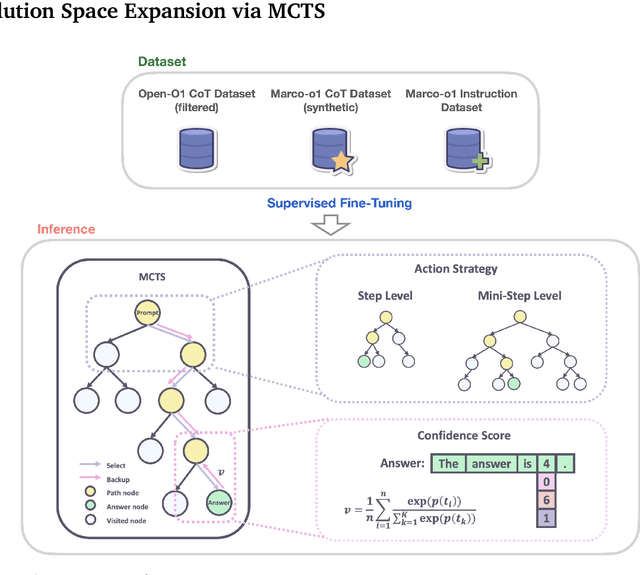
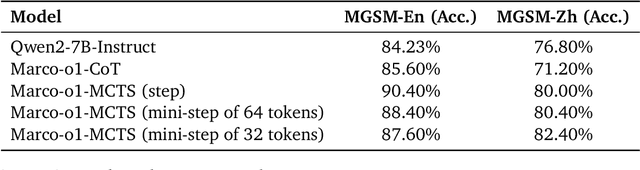
Currently OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mathematics, physics, and coding -- which are well-suited for reinforcement learning (RL) -- but also places greater emphasis on open-ended resolutions. We aim to address the question: "Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?" Marco-o1 is powered by Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), reflection mechanisms, and innovative reasoning strategies -- optimized for complex real-world problem-solving tasks.
View paper on