 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2IR: Proactive All-in-One Image Restoration via Mamba-style Modulation and Mixture-of-Experts
Mar 16, 2026While Transformer-based architectures have dominated recent advances in all-in-one image restoration, they remain fundamentally reactive: propagating degradations rather than proactively suppressing them. In the absence of explicit suppression mechanisms, degraded signals interfere with feature learning, compelling the decoder to balance artifact removal and detail preservation, thereby increasing model complexity and limiting adaptability. To address these challenges, we propose M2IR, a novel restoration framework that proactively regulates degradation propagation during the encoding stage and efficiently eliminates residual degradations during decoding. Specifically, the Mamba-Style Transformer (MST) block performs pixel-wise selective state modulation to mitigate degradations while preserving structural integrity. In parallel, the Adaptive Degradation Expert Collaboration (ADEC) module utilizes degradation-specific experts guided by a DA-CLIP-driven router and complemented by a shared expert to eliminate residual degradations through targeted and cooperative restoration. By integrating the MST block and ADEC module, M2IR transitions from passive reaction to active degradation control, effectively harnessing learned representations to achieve superior generalization, enhanced adaptability, and refined recovery of fine-grained details across diverse all-in-one image restoration benchmarks. Our source codes are available at https://github.com/Im34v/M2IR.
Unwarping Screen Content Images via Structure-texture Enhancement Network and Transformation Self-estimation
Apr 21, 2025While existing implicit neural network-based image unwarping methods perform well on natural images, they struggle to handle screen content images (SCIs), which often contain large geometric distortions, text, symbols, and sharp edges. To address this, we propose a structure-texture enhancement network (STEN) with transformation self-estimation for SCI warping. STEN integrates a B-spline implicit neural representation module and a transformation error estimation and self-correction algorithm. It comprises two branches: the structure estimation branch (SEB), which enhances local aggregation and global dependency modeling, and the texture estimation branch (TEB), which improves texture detail synthesis using B-spline implicit neural representation. Additionally, the transformation self-estimation module autonomously estimates the transformation error and corrects the coordinate transformation matrix, effectively handling real-world image distortions. Extensive experiments on public SCI datasets demonstrate that our approach significantly outperforms state-of-the-art methods. Comparisons on well-known natural image datasets also show the potential of our approach for natural image distortion.
CLIP-SR: Collaborative Linguistic and Image Processing for Super-Resolution
Dec 16, 2024Convolutional Neural Networks (CNNs) have advanced Image Super-Resolution (SR), but most CNN-based methods rely solely on pixel-based transformations, often leading to artifacts and blurring, particularly with severe downsampling (e.g., 8x or 16x). Recent text-guided SR methods attempt to leverage textual information for enhanced detail, but they frequently struggle with effective alignment, resulting in inconsistent semantic coherence. To address these limitations, we introduce a multi-modal semantic enhancement approach that combines textual semantics with visual features, effectively tackling semantic mismatches and detail loss in highly degraded LR images. Our proposed multi-modal collaborative framework enables the production of realistic and high-quality SR images at significant up-scaling factors. The framework integrates text and image inputs, employing a prompt predictor, Text-Image Fusion Block (TIFBlock), and Iterative Refinement Module alongside CLIP (Contrastive Language-Image Pretraining) features to guide a progressive enhancement process with fine-grained alignment. This alignment produces high-resolution outputs with crisp details and semantic coherence, even at large scaling factors. Through extensive comparative experiments and ablation studies, we validate the effectiveness of our approach. Additionally, by incorporating textual semantic guidance, our technique enables a degree of super-resolution editability while maintaining semantic coherence.
CaLa: Complementary Association Learning for Augmenting Composed Image Retrieval
May 29, 2024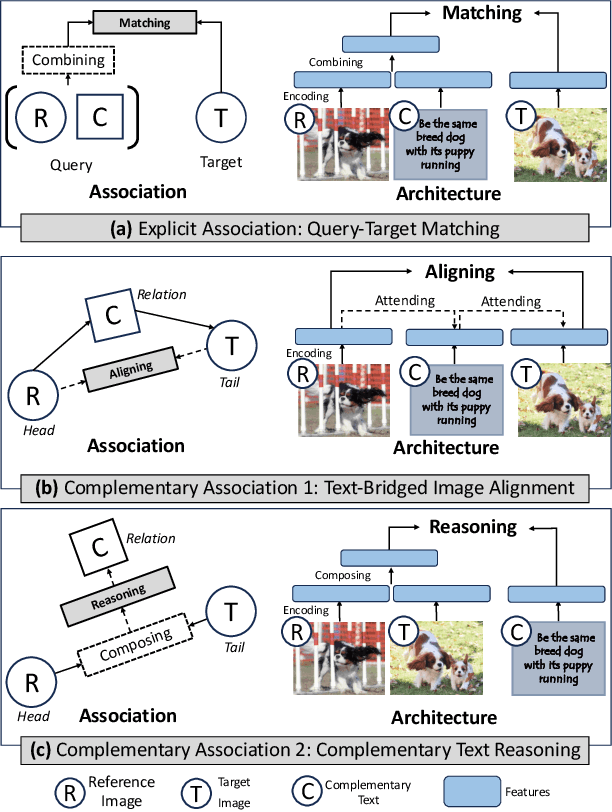
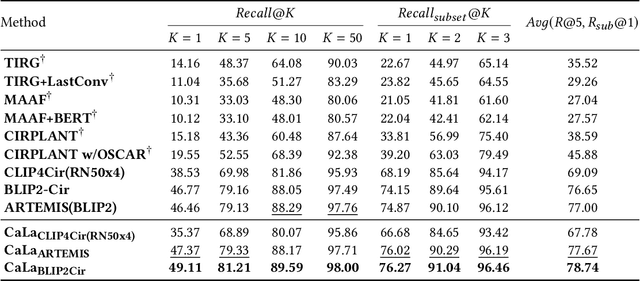
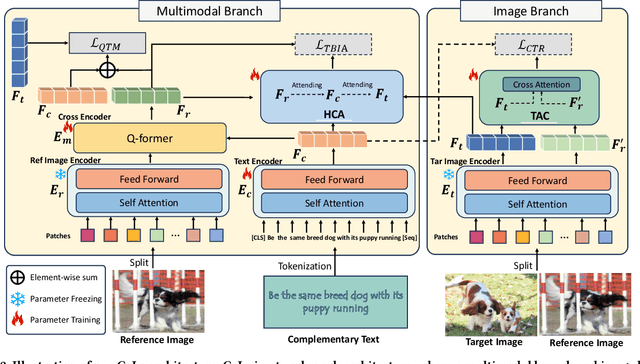
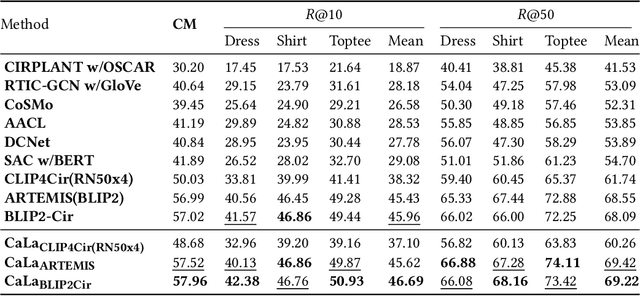
Composed Image Retrieval (CIR) involves searching for target images based on an image-text pair query. While current methods treat this as a query-target matching problem, we argue that CIR triplets contain additional associations beyond this primary relation. In our paper, we identify two new relations within triplets, treating each triplet as a graph node. Firstly, we introduce the concept of text-bridged image alignment, where the query text serves as a bridge between the query image and the target image. We propose a hinge-based cross-attention mechanism to incorporate this relation into network learning. Secondly, we explore complementary text reasoning, considering CIR as a form of cross-modal retrieval where two images compose to reason about complementary text. To integrate these perspectives effectively, we design a twin attention-based compositor. By combining these complementary associations with the explicit query pair-target image relation, we establish a comprehensive set of constraints for CIR. Our framework, CaLa (Complementary Association Learning for Augmenting Composed Image Retrieval), leverages these insights. We evaluate CaLa on CIRR and FashionIQ benchmarks with multiple backbones, demonstrating its superiority in composed image retrieval.
SPG-VTON: Semantic Prediction Guidance for Multi-pose Virtual Try-on
Aug 03, 2021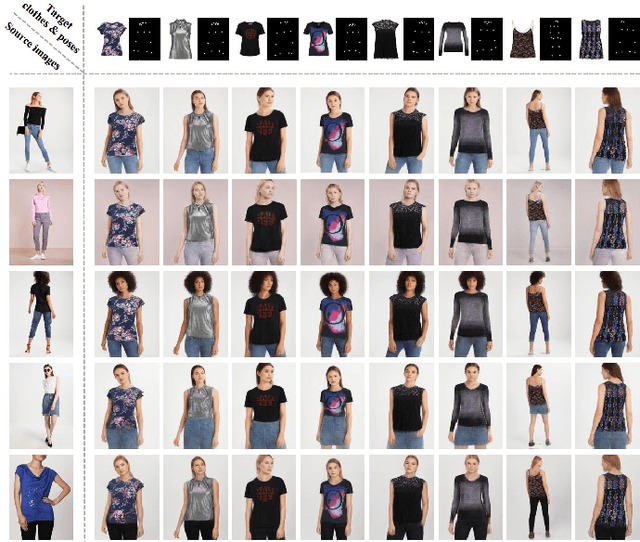
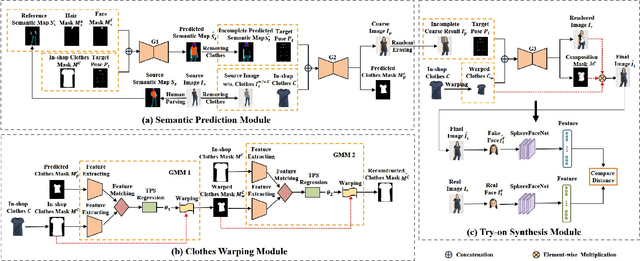
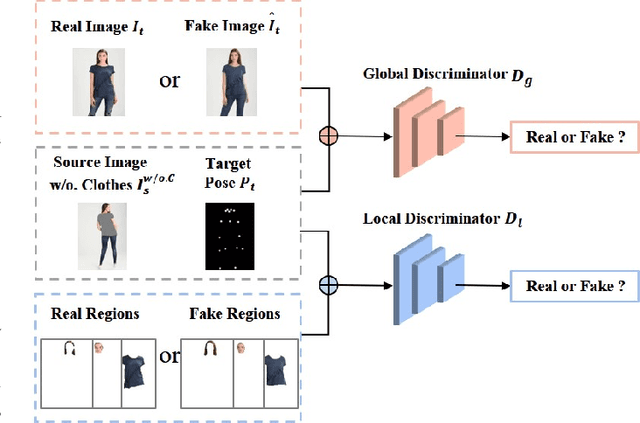

Image-based virtual try-on is challenging in fitting a target in-shop clothes into a reference person under diverse human poses. Previous works focus on preserving clothing details ( e.g., texture, logos, patterns ) when transferring desired clothes onto a target person under a fixed pose. However, the performances of existing methods significantly dropped when extending existing methods to multi-pose virtual try-on. In this paper, we propose an end-to-end Semantic Prediction Guidance multi-pose Virtual Try-On Network (SPG-VTON), which could fit the desired clothing into a reference person under arbitrary poses. Concretely, SPG-VTON is composed of three sub-modules. First, a Semantic Prediction Module (SPM) generates the desired semantic map. The predicted semantic map provides more abundant guidance to locate the desired clothes region and produce a coarse try-on image. Second, a Clothes Warping Module (CWM) warps in-shop clothes to the desired shape according to the predicted semantic map and the desired pose. Specifically, we introduce a conductible cycle consistency loss to alleviate the misalignment in the clothes warping process. Third, a Try-on Synthesis Module (TSM) combines the coarse result and the warped clothes to generate the final virtual try-on image, preserving details of the desired clothes and under the desired pose. Besides, we introduce a face identity loss to refine the facial appearance and maintain the identity of the final virtual try-on result at the same time. We evaluate the proposed method on the most massive multi-pose dataset (MPV) and the DeepFashion dataset. The qualitative and quantitative experiments show that SPG-VTON is superior to the state-of-the-art methods and is robust to the data noise, including background and accessory changes, i.e., hats and handbags, showing good scalability to the real-world scenario.
Unsupervised Eyeglasses Removal in the Wild
Sep 16, 2019
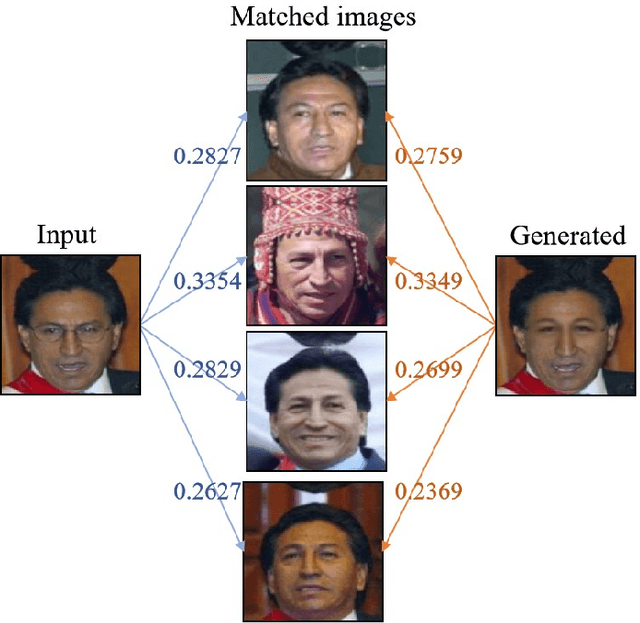

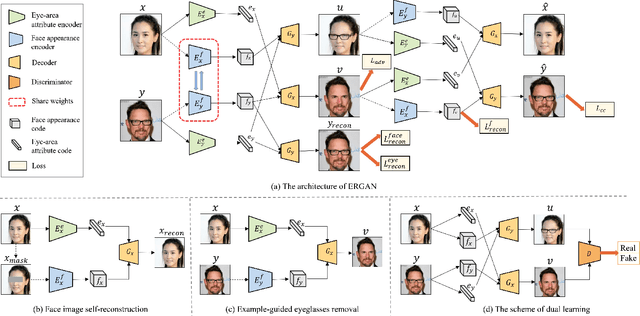
Eyeglasses removal is challenging in removing different kinds of eyeglasses, e.g., rimless glasses, full-rim glasses and sunglasses, and recovering appropriate eyes. Due to the large visual variants, the conventional methods lack scalability. Most existing works focus on the frontal face images in the controlled environment such as laboratory and need to design specific systems for different eyeglass types. To address the limitation, we propose a unified eyeglass removal model called Eyeglasses Removal Generative Adversarial Network (ERGAN), which could handle different types of glasses in the wild. The proposed method does not depend on the dense annotation of eyeglasses location but benefits from the large-scale face images with weak annotations. Specifically, we study the two relevant tasks simultaneously, i.e., removing and wearing eyeglasses. Given two facial images with and without eyeglasses, the proposed model learns to swap the eye area in two faces. The generation mechanism focuses on the eye area and invades the difficulty of generating a new face. In the experiment, we show the proposed method achieves a competitive removal quality in terms of realism and diversity. Furthermore, we evaluate our method on several subsequent tasks, such as face verification and facial expression recognition. The experiment shows that our method could serve as a pre-processing method for these tasks.