 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPG-VTON: Semantic Prediction Guidance for Multi-pose Virtual Try-on
Paper and Code
Aug 03, 2021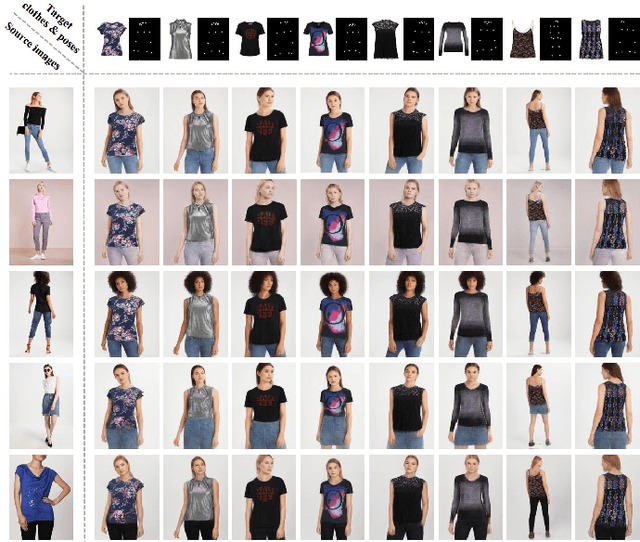
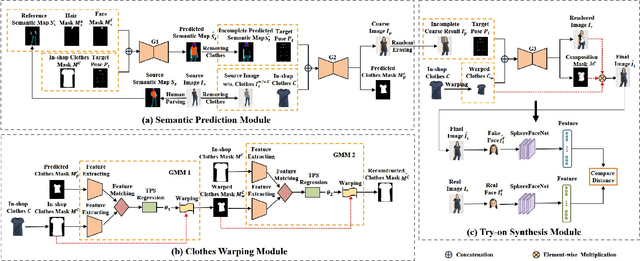
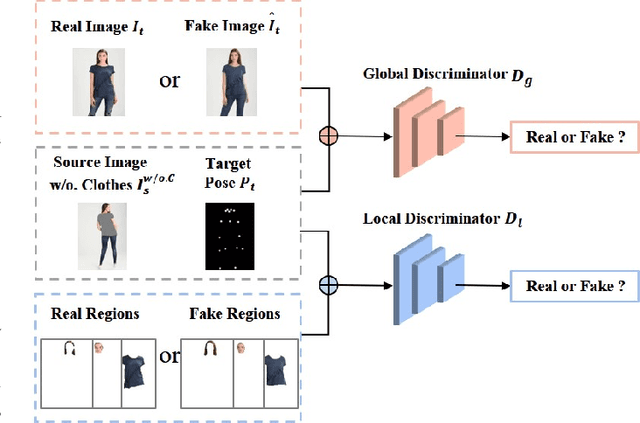

Image-based virtual try-on is challenging in fitting a target in-shop clothes into a reference person under diverse human poses. Previous works focus on preserving clothing details ( e.g., texture, logos, patterns ) when transferring desired clothes onto a target person under a fixed pose. However, the performances of existing methods significantly dropped when extending existing methods to multi-pose virtual try-on. In this paper, we propose an end-to-end Semantic Prediction Guidance multi-pose Virtual Try-On Network (SPG-VTON), which could fit the desired clothing into a reference person under arbitrary poses. Concretely, SPG-VTON is composed of three sub-modules. First, a Semantic Prediction Module (SPM) generates the desired semantic map. The predicted semantic map provides more abundant guidance to locate the desired clothes region and produce a coarse try-on image. Second, a Clothes Warping Module (CWM) warps in-shop clothes to the desired shape according to the predicted semantic map and the desired pose. Specifically, we introduce a conductible cycle consistency loss to alleviate the misalignment in the clothes warping process. Third, a Try-on Synthesis Module (TSM) combines the coarse result and the warped clothes to generate the final virtual try-on image, preserving details of the desired clothes and under the desired pose. Besides, we introduce a face identity loss to refine the facial appearance and maintain the identity of the final virtual try-on result at the same time. We evaluate the proposed method on the most massive multi-pose dataset (MPV) and the DeepFashion dataset. The qualitative and quantitative experiments show that SPG-VTON is superior to the state-of-the-art methods and is robust to the data noise, including background and accessory changes, i.e., hats and handbags, showing good scalability to the real-world scenario.