 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing 3D Scenes in Native High Dynamic Range
Nov 17, 2025High Dynamic Range (HDR) imaging is essential for professional digital media creation, e.g., filmmaking, virtual production, and photorealistic rendering. However, 3D scene reconstruction has primarily focused on Low Dynamic Range (LDR) data, limiting its applicability to professional workflows. Existing approaches that reconstruct HDR scenes from LDR observations rely on multi-exposure fusion or inverse tone-mapping, which increase capture complexity and depend on synthetic supervision. With the recent emergence of cameras that directly capture native HDR data in a single exposure, we present the first method for 3D scene reconstruction that directly models native HDR observations. We propose {\bf Native High dynamic range 3D Gaussian Splatting (NH-3DGS)}, which preserves the full dynamic range throughout the reconstruction pipeline. Our key technical contribution is a novel luminance-chromaticity decomposition of the color representation that enables direct optimization from native HDR camera data. We demonstrate on both synthetic and real multi-view HDR datasets that NH-3DGS significantly outperforms existing methods in reconstruction quality and dynamic range preservation, enabling professional-grade 3D reconstruction directly from native HDR captures. Code and datasets will be made available.
Bridging Granularity Gaps: Hierarchical Semantic Learning for Cross-domain Few-shot Segmentation
Nov 15, 2025Cross-domain Few-shot Segmentation (CD-FSS) aims to segment novel classes from target domains that are not involved in training and have significantly different data distributions from the source domain, using only a few annotated samples, and recent years have witnessed significant progress on this task. However, existing CD-FSS methods primarily focus on style gaps between source and target domains while ignoring segmentation granularity gaps, resulting in insufficient semantic discriminability for novel classes in target domains. Therefore, we propose a Hierarchical Semantic Learning (HSL) framework to tackle this problem. Specifically, we introduce a Dual Style Randomization (DSR) module and a Hierarchical Semantic Mining (HSM) module to learn hierarchical semantic features, thereby enhancing the model's ability to recognize semantics at varying granularities. DSR simulates target domain data with diverse foreground-background style differences and overall style variations through foreground and global style randomization respectively, while HSM leverages multi-scale superpixels to guide the model to mine intra-class consistency and inter-class distinction at different granularities. Additionally, we also propose a Prototype Confidence-modulated Thresholding (PCMT) module to mitigate segmentation ambiguity when foreground and background are excessively similar. Extensive experiments are conducted on four popular target domain datasets, and the results demonstrate that our method achieves state-of-the-art performance.
High Dynamic Range Novel View Synthesis with Single Exposure
May 02, 2025
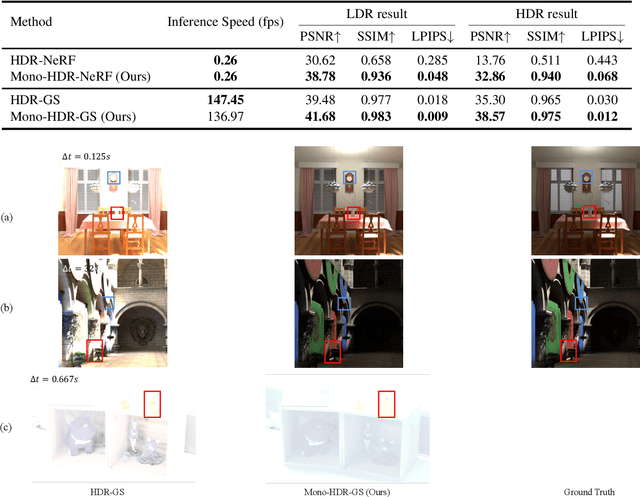
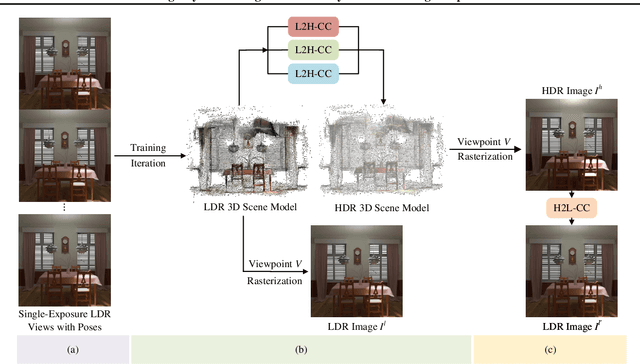
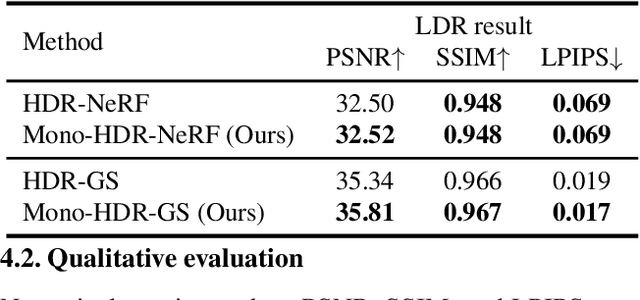
High Dynamic Range Novel View Synthesis (HDR-NVS) aims to establish a 3D scene HDR model from Low Dynamic Range (LDR) imagery. Typically, multiple-exposure LDR images are employed to capture a wider range of brightness levels in a scene, as a single LDR image cannot represent both the brightest and darkest regions simultaneously. While effective, this multiple-exposure HDR-NVS approach has significant limitations, including susceptibility to motion artifacts (e.g., ghosting and blurring), high capture and storage costs. To overcome these challenges, we introduce, for the first time, the single-exposure HDR-NVS problem, where only single exposure LDR images are available during training. We further introduce a novel approach, Mono-HDR-3D, featuring two dedicated modules formulated by the LDR image formation principles, one for converting LDR colors to HDR counterparts, and the other for transforming HDR images to LDR format so that unsupervised learning is enabled in a closed loop. Designed as a meta-algorithm, our approach can be seamlessly integrated with existing NVS models. Extensive experiments show that Mono-HDR-3D significantly outperforms previous methods. Source code will be released.
SPG-VTON: Semantic Prediction Guidance for Multi-pose Virtual Try-on
Aug 03, 2021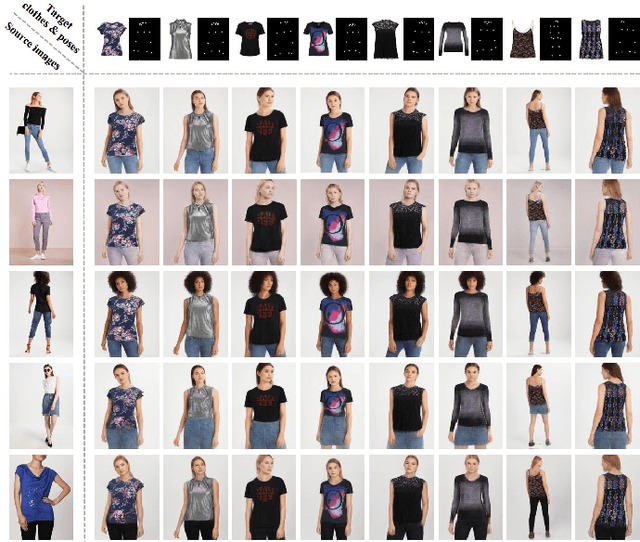
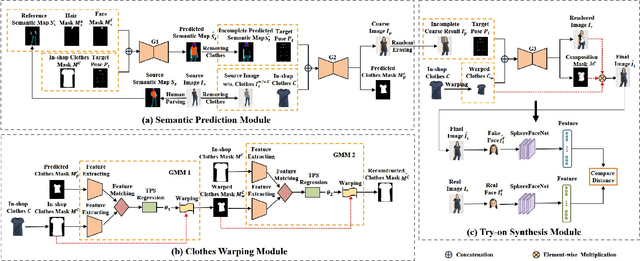
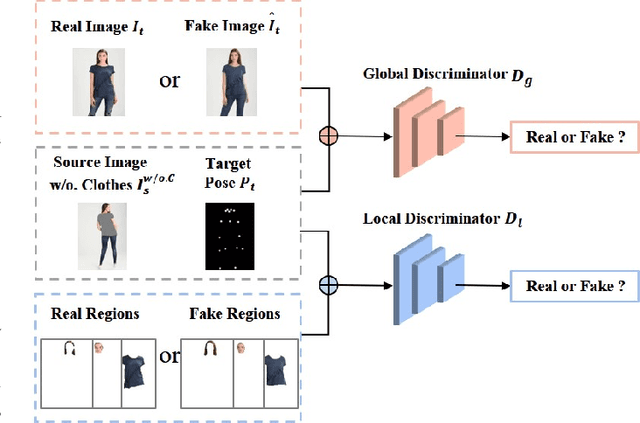

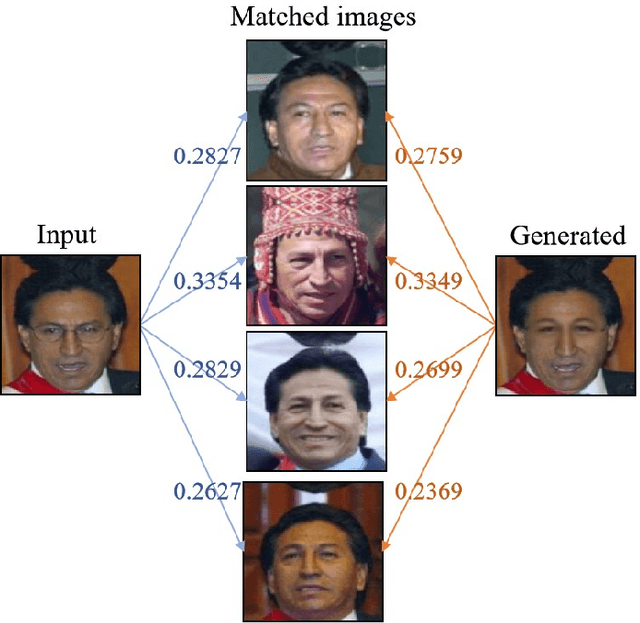
Image-based virtual try-on is challenging in fitting a target in-shop clothes into a reference person under diverse human poses. Previous works focus on preserving clothing details ( e.g., texture, logos, patterns ) when transferring desired clothes onto a target person under a fixed pose. However, the performances of existing methods significantly dropped when extending existing methods to multi-pose virtual try-on. In this paper, we propose an end-to-end Semantic Prediction Guidance multi-pose Virtual Try-On Network (SPG-VTON), which could fit the desired clothing into a reference person under arbitrary poses. Concretely, SPG-VTON is composed of three sub-modules. First, a Semantic Prediction Module (SPM) generates the desired semantic map. The predicted semantic map provides more abundant guidance to locate the desired clothes region and produce a coarse try-on image. Second, a Clothes Warping Module (CWM) warps in-shop clothes to the desired shape according to the predicted semantic map and the desired pose. Specifically, we introduce a conductible cycle consistency loss to alleviate the misalignment in the clothes warping process. Third, a Try-on Synthesis Module (TSM) combines the coarse result and the warped clothes to generate the final virtual try-on image, preserving details of the desired clothes and under the desired pose. Besides, we introduce a face identity loss to refine the facial appearance and maintain the identity of the final virtual try-on result at the same time. We evaluate the proposed method on the most massive multi-pose dataset (MPV) and the DeepFashion dataset. The qualitative and quantitative experiments show that SPG-VTON is superior to the state-of-the-art methods and is robust to the data noise, including background and accessory changes, i.e., hats and handbags, showing good scalability to the real-world scenario.
Unsupervised Eyeglasses Removal in the Wild
Sep 16, 2019

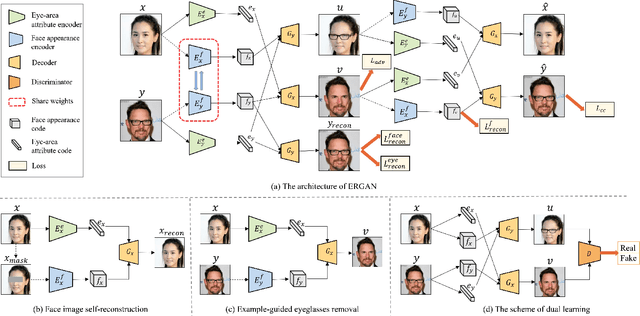
Eyeglasses removal is challenging in removing different kinds of eyeglasses, e.g., rimless glasses, full-rim glasses and sunglasses, and recovering appropriate eyes. Due to the large visual variants, the conventional methods lack scalability. Most existing works focus on the frontal face images in the controlled environment such as laboratory and need to design specific systems for different eyeglass types. To address the limitation, we propose a unified eyeglass removal model called Eyeglasses Removal Generative Adversarial Network (ERGAN), which could handle different types of glasses in the wild. The proposed method does not depend on the dense annotation of eyeglasses location but benefits from the large-scale face images with weak annotations. Specifically, we study the two relevant tasks simultaneously, i.e., removing and wearing eyeglasses. Given two facial images with and without eyeglasses, the proposed model learns to swap the eye area in two faces. The generation mechanism focuses on the eye area and invades the difficulty of generating a new face. In the experiment, we show the proposed method achieves a competitive removal quality in terms of realism and diversity. Furthermore, we evaluate our method on several subsequent tasks, such as face verification and facial expression recognition. The experiment shows that our method could serve as a pre-processing method for these tasks.
Multi-appearance Segmentation and Extended 0-1 Program for Dense Small Object Tracking
Dec 14, 2017



Aiming to address the fast multi-object tracking for dense small object in the cluster background, we review track orientated multi-hypothesis tracking(TOMHT) with consideration of batch optimization. Employing autocorrelation based motion score test and staged hypotheses merging approach, we build our homologous hypothesis generation and management method. A new one-to-many constraint is proposed and applied to tackle the track exclusions during complex occlusions. Besides, to achieve better results, we develop a multi-appearance segmentation for detection, which exploits tree-like topological information and realizes one threshold for one object. Experimental results verify the strength of our methods, indicating speed and performance advantages of our tracker.
Exploiting Color Name Space for Salient Object Detection
Mar 27, 2017

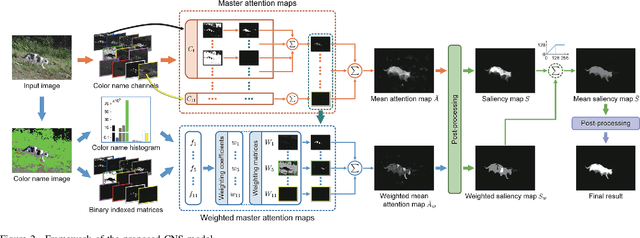
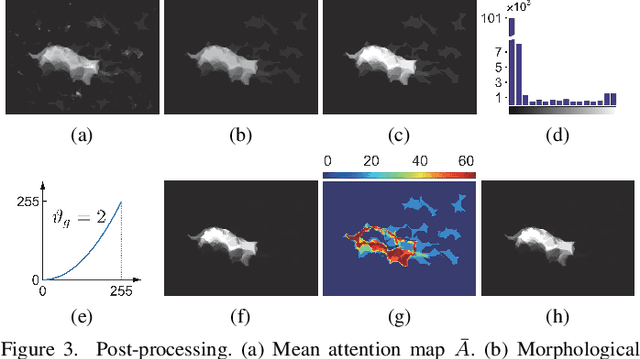
In this paper, we will investigate the contribution of color names for salient object detection. Each input image is first converted to the color name space, which is consisted of 11 probabilistic channels. By exploring the topological structure relationship between the figure and the ground, we obtain a saliency map through a linear combination of a set of sequential attention maps. To overcome the limitation of only exploiting the surroundedness cue, two global cues with respect to color names are invoked for guiding the computation of another weighted saliency map. Finally, we integrate the two saliency maps into a unified framework to infer the saliency result. In addition, an improved post-processing procedure is introduced to effectively suppress the background while uniformly highlight the salient objects. Experimental results show that the proposed model produces more accurate saliency maps and performs well against 23 saliency models in terms of three evaluation metrics on three public datasets.