 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaLa: Complementary Association Learning for Augmenting Composed Image Retrieval
Paper and Code
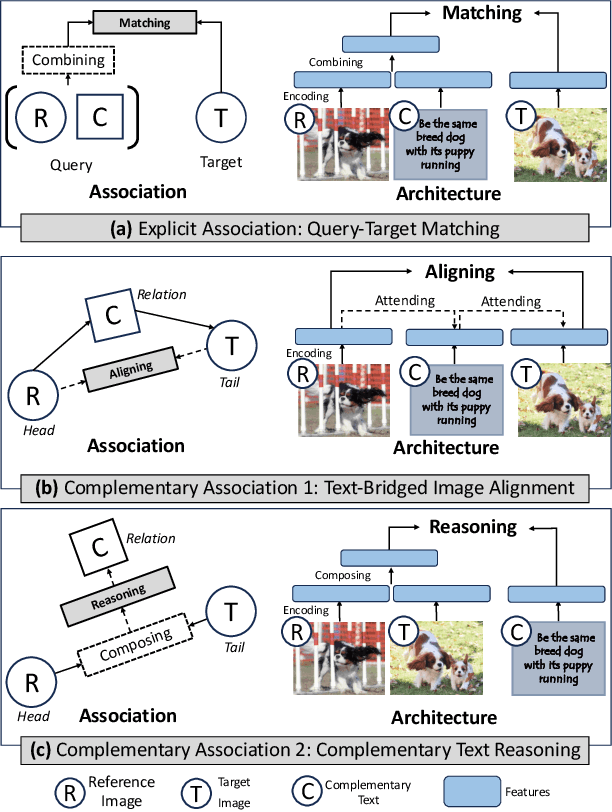
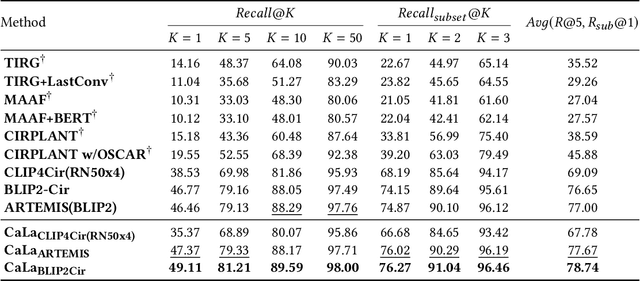
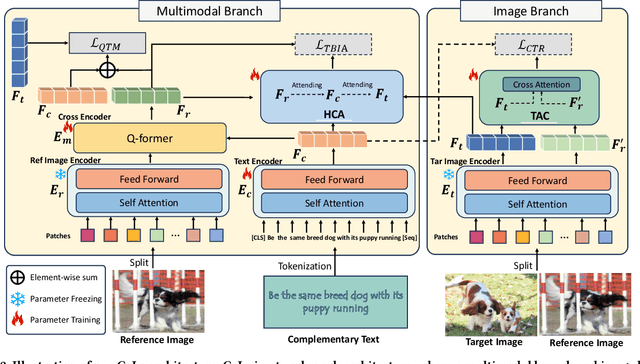
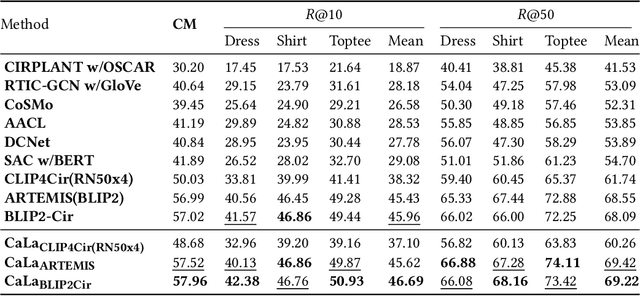
Composed Image Retrieval (CIR) involves searching for target images based on an image-text pair query. While current methods treat this as a query-target matching problem, we argue that CIR triplets contain additional associations beyond this primary relation. In our paper, we identify two new relations within triplets, treating each triplet as a graph node. Firstly, we introduce the concept of text-bridged image alignment, where the query text serves as a bridge between the query image and the target image. We propose a hinge-based cross-attention mechanism to incorporate this relation into network learning. Secondly, we explore complementary text reasoning, considering CIR as a form of cross-modal retrieval where two images compose to reason about complementary text. To integrate these perspectives effectively, we design a twin attention-based compositor. By combining these complementary associations with the explicit query pair-target image relation, we establish a comprehensive set of constraints for CIR. Our framework, CaLa (Complementary Association Learning for Augmenting Composed Image Retrieval), leverages these insights. We evaluate CaLa on CIRR and FashionIQ benchmarks with multiple backbones, demonstrating its superiority in composed image retrieval.