 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-Arena: an Automated Evaluation Framework for Deep Research Agents
Jan 15, 2026As Large Language Models (LLMs) increasingly operate as Deep Research (DR) Agents capable of autonomous investigation and information synthesis, reliable evaluation of their task performance has become a critical bottleneck. Current benchmarks predominantly rely on static datasets, which suffer from several limitations: limited task generality, temporal misalignment, and data contamination. To address these, we introduce DR-Arena, a fully automated evaluation framework that pushes DR agents to their capability limits through dynamic investigation. DR-Arena constructs real-time Information Trees from fresh web trends to ensure the evaluation rubric is synchronized with the live world state, and employs an automated Examiner to generate structured tasks testing two orthogonal capabilities: Deep reasoning and Wide coverage. DR-Arena further adopts Adaptive Evolvement Loop, a state-machine controller that dynamically escalates task complexity based on real-time performance, demanding deeper deduction or wider aggregation until a decisive capability boundary emerges. Experiments with six advanced DR agents demonstrate that DR-Arena achieves a Spearman correlation of 0.94 with the LMSYS Search Arena leaderboard. This represents the state-of-the-art alignment with human preferences without any manual efforts, validating DR-Arena as a reliable alternative for costly human adjudication.
Cross-Domain Sequential Recommendation via Neural Process
Oct 17, 2024



Cross-Domain Sequential Recommendation (CDSR) is a hot topic in sequence-based user interest modeling, which aims at utilizing a single model to predict the next items for different domains. To tackle the CDSR, many methods are focused on domain overlapped users' behaviors fitting, which heavily relies on the same user's different-domain item sequences collaborating signals to capture the synergy of cross-domain item-item correlation. Indeed, these overlapped users occupy a small fraction of the entire user set only, which introduces a strong assumption that the small group of domain overlapped users is enough to represent all domain user behavior characteristics. However, intuitively, such a suggestion is biased, and the insufficient learning paradigm in non-overlapped users will inevitably limit model performance. Further, it is not trivial to model non-overlapped user behaviors in CDSR because there are no other domain behaviors to collaborate with, which causes the observed single-domain users' behavior sequences to be hard to contribute to cross-domain knowledge mining. Considering such a phenomenon, we raise a challenging and unexplored question: How to unleash the potential of non-overlapped users' behaviors to empower CDSR?
Focus, Distinguish, and Prompt: Unleashing CLIP for Efficient and Flexible Scene Text Retrieval
Aug 01, 2024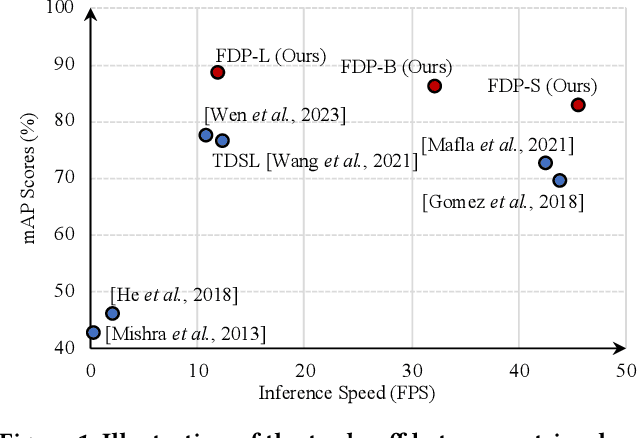
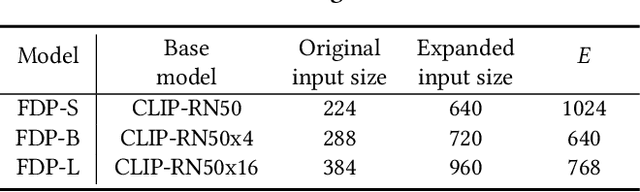


Scene text retrieval aims to find all images containing the query text from an image gallery. Current efforts tend to adopt an Optical Character Recognition (OCR) pipeline, which requires complicated text detection and/or recognition processes, resulting in inefficient and inflexible retrieval. Different from them, in this work we propose to explore the intrinsic potential of Contrastive Language-Image Pre-training (CLIP) for OCR-free scene text retrieval. Through empirical analysis, we observe that the main challenges of CLIP as a text retriever are: 1) limited text perceptual scale, and 2) entangled visual-semantic concepts. To this end, a novel model termed FDP (Focus, Distinguish, and Prompt) is developed. FDP first focuses on scene text via shifting the attention to the text area and probing the hidden text knowledge, and then divides the query text into content word and function word for processing, in which a semantic-aware prompting scheme and a distracted queries assistance module are utilized. Extensive experiments show that FDP significantly enhances the inference speed while achieving better or competitive retrieval accuracy compared to existing methods. Notably, on the IIIT-STR benchmark, FDP surpasses the state-of-the-art model by 4.37% with a 4 times faster speed. Furthermore, additional experiments under phrase-level and attribute-aware scene text retrieval settings validate FDP's particular advantages in handling diverse forms of query text. The source code will be publicly available at https://github.com/Gyann-z/FDP.
MODMA dataset: a Multi-modal Open Dataset for Mental-disorder Analysis
Mar 05, 2020

According to the World Health Organization, the number of mental disorder patients, especially depression patients, has grown rapidly and become a leading contributor to the global burden of disease. However, the present common practice of depression diagnosis is based on interviews and clinical scales carried out by doctors, which is not only labor-consuming but also time-consuming. One important reason is due to the lack of physiological indicators for mental disorders. With the rising of tools such as data mining and artificial intelligence, using physiological data to explore new possible physiological indicators of mental disorder and creating new applications for mental disorder diagnosis has become a new research hot topic. However, good quality physiological data for mental disorder patients are hard to acquire. We present a multi-modal open dataset for mental-disorder analysis. The dataset includes EEG and audio data from clinically depressed patients and matching normal controls. All our patients were carefully diagnosed and selected by professional psychiatrists in hospitals. The EEG dataset includes not only data collected using traditional 128-electrodes mounted elastic cap, but also a novel wearable 3-electrode EEG collector for pervasive applications. The 128-electrodes EEG signals of 53 subjects were recorded as both in resting state and under stimulation; the 3-electrode EEG signals of 55 subjects were recorded in resting state; the audio data of 52 subjects were recorded during interviewing, reading, and picture description. We encourage other researchers in the field to use it for testing their methods of mental-disorder analysis.