 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dual-Weighting Framework for Federated Learning via Out-of-Distribution Detection
Feb 01, 2026Federated Learning (FL) enables collaborative model training across large-scale distributed service nodes while preserving data privacy, making it a cornerstone of intelligent service systems in edge-cloud environments. However, in real-world service-oriented deployments, data generated by heterogeneous users, devices, and application scenarios are inherently non-IID. This severe data heterogeneity critically undermines the convergence stability, generalization ability, and ultimately the quality of service delivered by the global model. To address this challenge, we propose FLood, a novel FL framework inspired by out-of-distribution (OOD) detection. FLood dynamically counteracts the adverse effects of heterogeneity through a dual-weighting mechanism that jointly governs local training and global aggregation. At the client level, it adaptively reweights the supervised loss by upweighting pseudo-OOD samples, thereby encouraging more robust learning from distributionally misaligned or challenging data. At the server level, it refines model aggregation by weighting client contributions according to their OOD confidence scores, prioritizing updates from clients with higher in-distribution consistency and enhancing the global model's robustness and convergence stability. Extensive experiments across multiple benchmarks under diverse non-IID settings demonstrate that FLood consistently outperforms state-of-the-art FL methods in both accuracy and generalization. Furthermore, FLood functions as an orthogonal plug-in module: it seamlessly integrates with existing FL algorithms to boost their performance under heterogeneity without modifying their core optimization logic. These properties make FLood a practical and scalable solution for deploying reliable intelligent services in real-world federated environments.
Overcoming Dimensional Factorization Limits in Discrete Diffusion Models through Quantum Joint Distribution Learning
May 08, 2025This study explores quantum-enhanced discrete diffusion models to overcome classical limitations in learning high-dimensional distributions. We rigorously prove that classical discrete diffusion models, which calculate per-dimension transition probabilities to avoid exponential computational cost, exhibit worst-case linear scaling of Kullback-Leibler (KL) divergence with data dimension. To address this, we propose a Quantum Discrete Denoising Diffusion Probabilistic Model (QD3PM), which enables joint probability learning through diffusion and denoising in exponentially large Hilbert spaces. By deriving posterior states through quantum Bayes' theorem, similar to the crucial role of posterior probabilities in classical diffusion models, and by learning the joint probability, we establish a solid theoretical foundation for quantum-enhanced diffusion models. For denoising, we design a quantum circuit using temporal information for parameter sharing and learnable classical-data-controlled rotations for encoding. Exploiting joint distribution learning, our approach enables single-step sampling from pure noise, eliminating iterative requirements of existing models. Simulations demonstrate the proposed model's superior accuracy in modeling complex distributions compared to factorization methods. Hence, this paper establishes a new theoretical paradigm in generative models by leveraging the quantum advantage in joint distribution learning.
A Pairwise Comparison Relation-assisted Multi-objective Evolutionary Neural Architecture Search Method with Multi-population Mechanism
Jul 22, 2024Neural architecture search (NAS) enables re-searchers to automatically explore vast search spaces and find efficient neural networks. But NAS suffers from a key bottleneck, i.e., numerous architectures need to be evaluated during the search process, which requires a lot of computing resources and time. In order to improve the efficiency of NAS, a series of methods have been proposed to reduce the evaluation time of neural architectures. However, they are not efficient enough and still only focus on the accuracy of architectures. In addition to the classification accuracy, more efficient and smaller network architectures are required in real-world applications. To address the above problems, we propose the SMEM-NAS, a pairwise com-parison relation-assisted multi-objective evolutionary algorithm based on a multi-population mechanism. In the SMEM-NAS, a surrogate model is constructed based on pairwise compari-son relations to predict the accuracy ranking of architectures, rather than the absolute accuracy. Moreover, two populations cooperate with each other in the search process, i.e., a main population guides the evolution, while a vice population expands the diversity. Our method aims to provide high-performance models that take into account multiple optimization objectives. We conduct a series of experiments on the CIFAR-10, CIFAR-100 and ImageNet datasets to verify its effectiveness. With only a single GPU searching for 0.17 days, competitive architectures can be found by SMEM-NAS which achieves 78.91% accuracy with the MAdds of 570M on the ImageNet. This work makes a significant advance in the important field of NAS.
Solving the Food-Energy-Water Nexus Problem via Intelligent Optimization Algorithms
Apr 10, 2024The application of evolutionary algorithms (EAs) to multi-objective optimization problems has been widespread. However, the EA research community has not paid much attention to large-scale multi-objective optimization problems arising from real-world applications. Especially, Food-Energy-Water systems are intricately linked among food, energy and water that impact each other. They usually involve a huge number of decision variables and many conflicting objectives to be optimized. Solving their related optimization problems is essentially important to sustain the high-quality life of human beings. Their solution space size expands exponentially with the number of decision variables. Searching in such a vast space is challenging because of such large numbers of decision variables and objective functions. In recent years, a number of large-scale many-objectives optimization evolutionary algorithms have been proposed. In this paper, we solve a Food-Energy-Water optimization problem by using the state-of-art intelligent optimization methods and compare their performance. Our results conclude that the algorithm based on an inverse model outperforms the others. This work should be highly useful for practitioners to select the most suitable method for their particular large-scale engineering optimization problems.
MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
Mar 04, 2021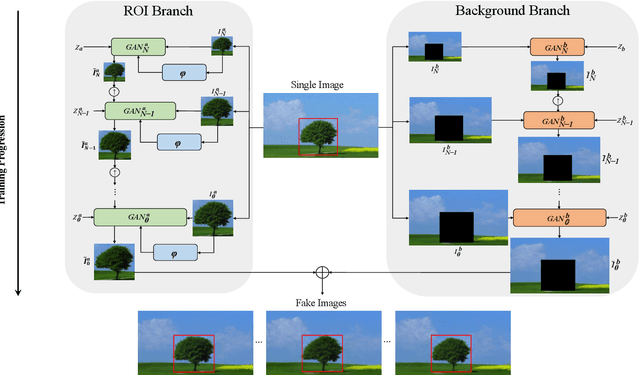
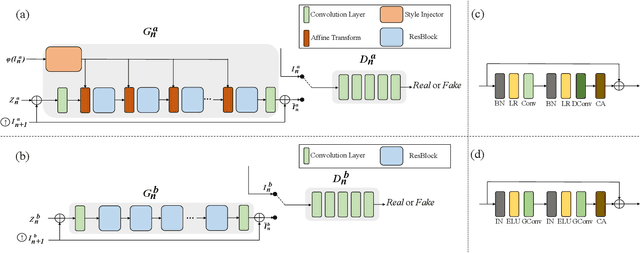
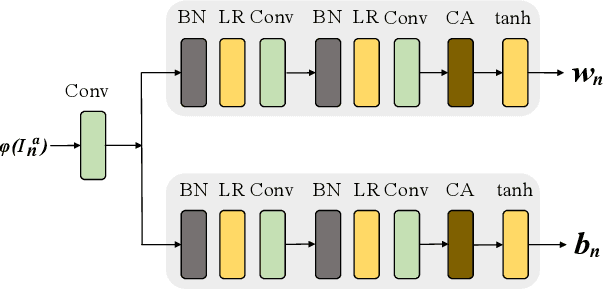

In most interactive image generation tasks, given regions of interest (ROI) by users, the generated results are expected to have adequate diversities in appearance while maintaining correct and reasonable structures in original images. Such tasks become more challenging if only limited data is available. Recently proposed generative models complete training based on only one image. They pay much attention to the monolithic feature of the sample while ignoring the actual semantic information of different objects inside the sample. As a result, for ROI-based generation tasks, they may produce inappropriate samples with excessive randomicity and without maintaining the related objects' correct structures. To address this issue, this work introduces a MOrphologic-structure-aware Generative Adversarial Network named MOGAN that produces random samples with diverse appearances and reliable structures based on only one image. For training for ROI, we propose to utilize the data coming from the original image being augmented and bring in a novel module to transform such augmented data into knowledge containing both structures and appearances, thus enhancing the model's comprehension of the sample. To learn the rest areas other than ROI, we employ binary masks to ensure the generation isolated from ROI. Finally, we set parallel and hierarchical branches of the mentioned learning process. Compared with other single image GAN schemes, our approach focuses on internal features including the maintenance of rational structures and variation on appearance. Experiments confirm a better capacity of our model on ROI-based image generation tasks than its competitive peers.
Scale-free Network-based Differential Evolution
Jan 27, 2021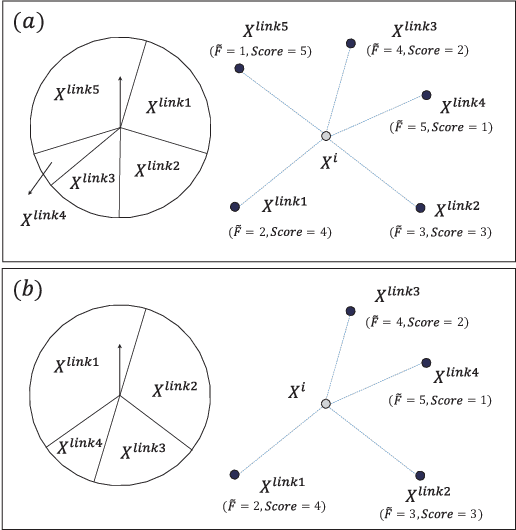
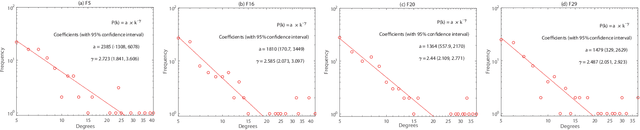
Some recent research reveals that a topological structure in meta-heuristic algorithms can effectively enhance the interaction of population, and thus improve their performance. Inspired by it, we creatively investigate the effectiveness of using a scale-free network in differential evolution methods, and propose a scale-free network-based differential evolution method. The novelties of this paper include a scale-free network-based population structure and a new mutation operator designed to fully utilize the neighborhood information provided by a scale-free structure. The elite individuals and population at the latest generation are both employed to guide a global optimization process. In this manner, the proposed algorithm owns balanced exploration and exploitation capabilities to alleviate the drawbacks of premature convergence. Experimental and statistical analyses are performed on the CEC'17 benchmark function suite and three real world problems. Results demonstrate its superior effectiveness and efficiency in comparison with its competitive peers.
Urban Sensing based on Mobile Phone Data: Approaches, Applications and Challenges
Aug 29, 2020
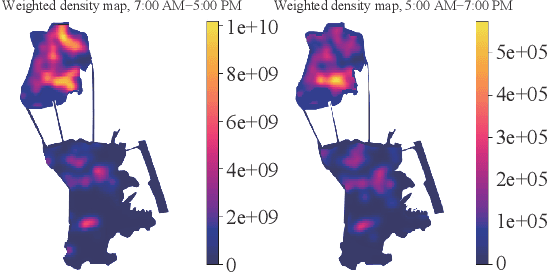
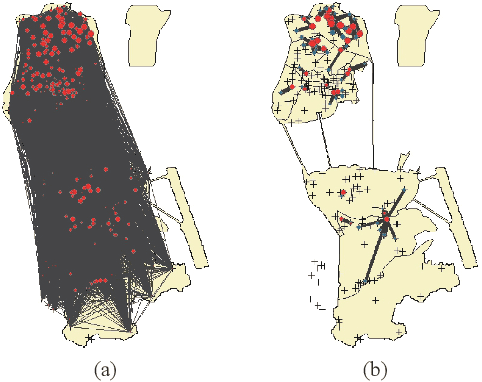
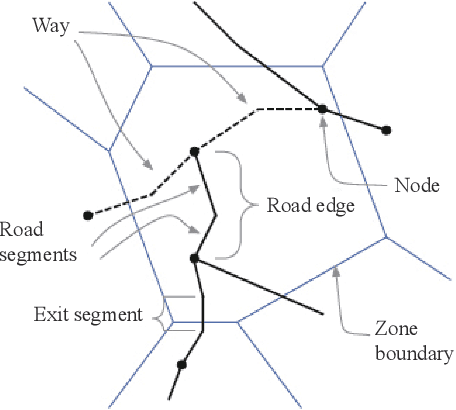
Data volume grows explosively with the proliferation of powerful smartphones and innovative mobile applications. The ability to accurately and extensively monitor and analyze these data is necessary. Much concern in mobile data analysis is related to human beings and their behaviours. Due to the potential value that lies behind these massive data, there have been different proposed approaches for understanding corresponding patterns. To that end, monitoring people's interactions, whether counting them at fixed locations or tracking them by generating origin-destination matrices is crucial. The former can be used to determine the utilization of assets like roads and city attractions. The latter is valuable when planning transport infrastructure. Such insights allow a government to predict the adoption of new roads, new public transport routes, modification of existing infrastructure, and detection of congestion zones, resulting in more efficient designs and improvement. Smartphone data exploration can help research in various fields, e.g., urban planning, transportation, health care, and business marketing. It can also help organizations in decision making, policy implementation, monitoring and evaluation at all levels. This work aims to review the methods and techniques that have been implemented to discover knowledge from mobile phone data. We classify these existing methods and present a taxonomy of the related work by discussing their pros and cons.
AI-based Modeling and Data-driven Evaluation for Smart Manufacturing Processes
Aug 29, 2020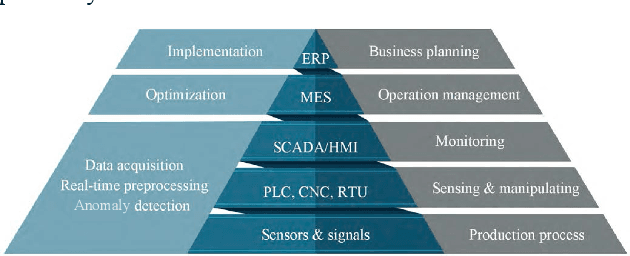
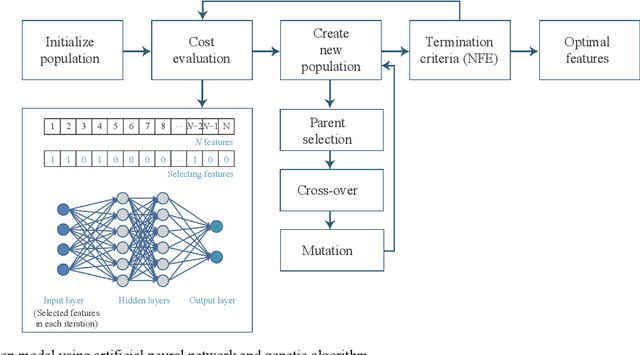
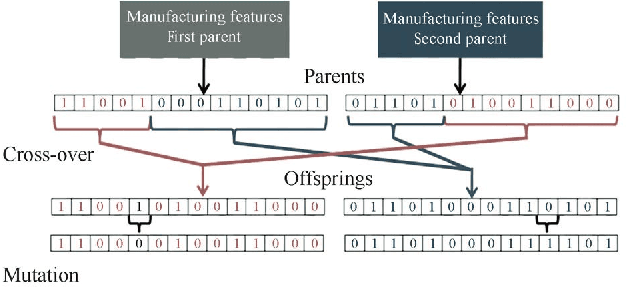
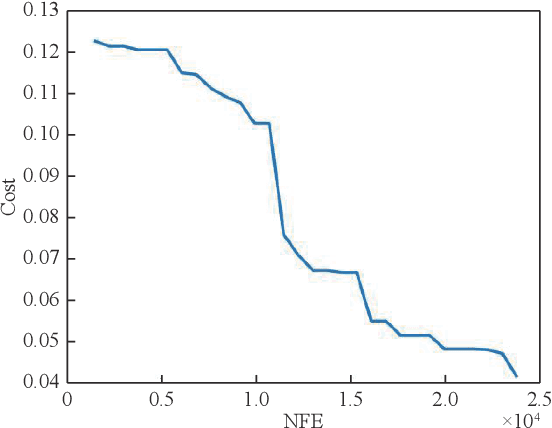
Smart Manufacturing refers to optimization techniques that are implemented in production operations by utilizing advanced analytics approaches. With the widespread increase in deploying Industrial Internet of Things (IIoT) sensors in manufacturing processes, there is a progressive need for optimal and effective approaches to data management. Embracing Machine Learning and Artificial Intelligence to take advantage of manufacturing data can lead to efficient and intelligent automation. In this paper, we conduct a comprehensive analysis based on Evolutionary Computing and Deep Learning algorithms toward making semiconductor manufacturing smart. We propose a dynamic algorithm for gaining useful insights about semiconductor manufacturing processes and to address various challenges. We elaborate on the utilization of a Genetic Algorithm and Neural Network to propose an intelligent feature selection algorithm. Our objective is to provide an advanced solution for controlling manufacturing processes and to gain perspective on various dimensions that enable manufacturers to access effective predictive technologies.
G-image Segmentation: Similarity-preserving Fuzzy C-Means with Spatial Information Constraint in Wavelet Space
Jul 01, 2020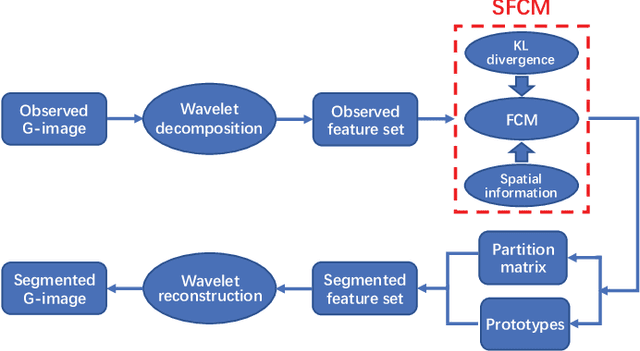
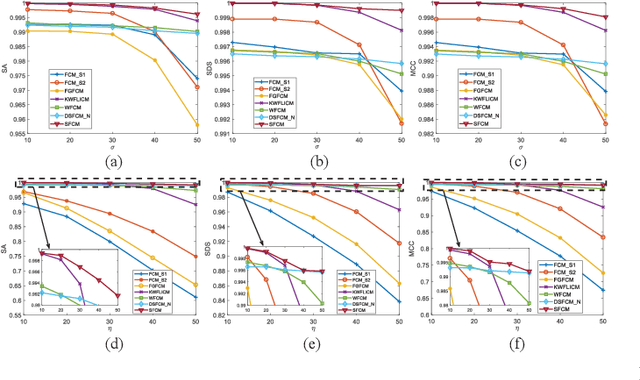
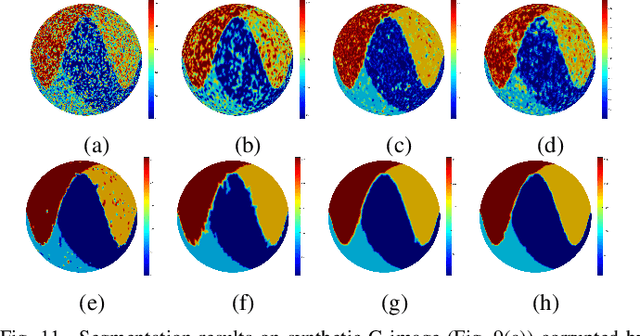
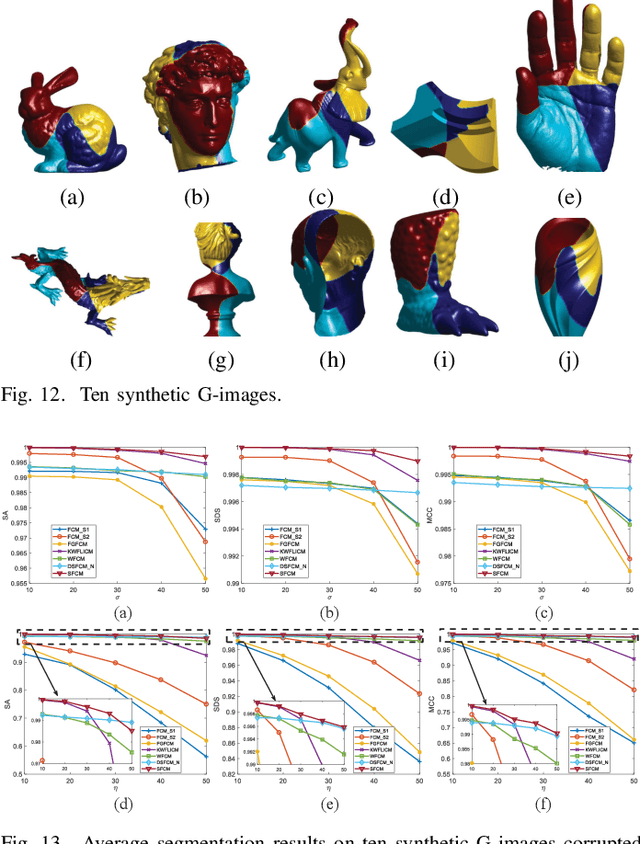
G-images refer to image data defined on irregular graph domains. This work elaborates a similarity-preserving Fuzzy C-Means (FCM) algorithm for G-image segmentation and aims to develop techniques and tools for segmenting G-images. To preserve the membership similarity between an arbitrary image pixel and its neighbors, a Kullback-Leibler divergence term on membership partition is introduced as a part of FCM. As a result, similarity-preserving FCM is developed by considering spatial information of image pixels for its robustness enhancement. Due to superior characteristics of a wavelet space, the proposed FCM is performed in this space rather than Euclidean one used in conventional FCM to secure its high robustness. Experiments on synthetic and real-world G-images demonstrate that it indeed achieves higher robustness and performance than the state-of-the-art FCM algorithms. Moreover, it requires less computation than most of them.
Residual-driven Fuzzy C-Means Clustering for Image Segmentation
Apr 20, 2020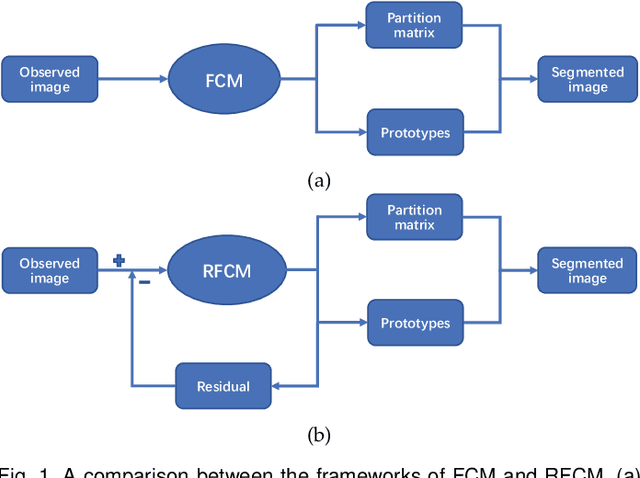
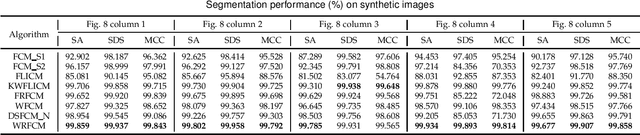
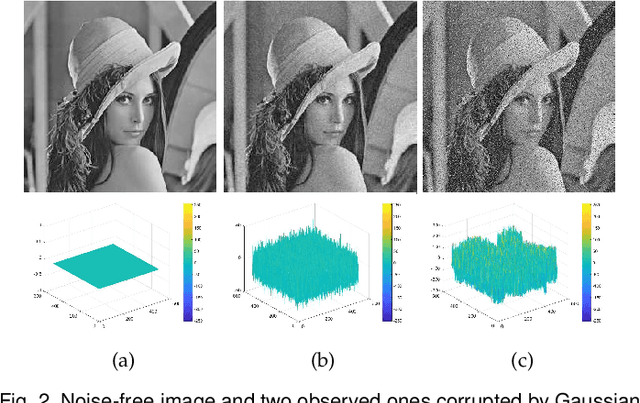
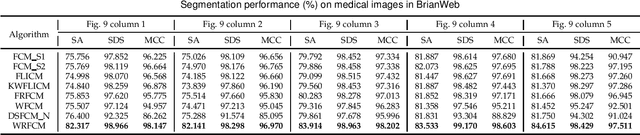
Due to its inferior characteristics, an observed (noisy) image's direct use gives rise to poor segmentation results. Intuitively, using its noise-free image can favorably impact image segmentation. Hence, the accurate estimation of the residual between observed and noise-free images is an important task. To do so, we elaborate on residual-driven Fuzzy C-Means (FCM) for image segmentation, which is the first approach that realizes accurate residual estimation and leads noise-free image to participate in clustering. We propose a residual-driven FCM framework by integrating into FCM a residual-related fidelity term derived from the distribution of different types of noise. Built on this framework, we present a weighted $\ell_{2}$-norm fidelity term by weighting mixed noise distribution, thus resulting in a universal residual-driven FCM algorithm in presence of mixed or unknown noise. Besides, with the constraint of spatial information, the residual estimation becomes more reliable than that only considering an observed image itself. Supporting experiments on synthetic, medical, and real-world images are conducted. The results demonstrate the superior effectiveness and efficiency of the proposed algorithm over existing FCM-related algorithms.